Alice E Huang, Michael T Chang, Ashoke Khanwalkar, Carol H Yan, Katie M Phillips, Michael J Yong, Jayakar V Nayak, Peter H Hwang, Zara M Patel
{"title":"Utilization of ChatGPT for Rhinology Patient Education: Limitations in a Surgical Sub-Specialty.","authors":"Alice E Huang, Michael T Chang, Ashoke Khanwalkar, Carol H Yan, Katie M Phillips, Michael J Yong, Jayakar V Nayak, Peter H Hwang, Zara M Patel","doi":"10.1002/oto2.70065","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To analyze the accuracy of ChatGPT-generated responses to common rhinologic patient questions.</p><p><strong>Methods: </strong>Ten common questions from rhinology patients were compiled by a panel of 4 rhinology fellowship-trained surgeons based on clinical patient experience. This panel (Panel 1) developed consensus \"expert\" responses to each question. Questions were individually posed to ChatGPT (version 3.5) and its responses recorded. ChatGPT-generated responses were individually graded by Panel 1 on a scale of 0 (incorrect) to 3 (correct and exceeding the quality of expert responses). A 2nd panel was given the consensus and ChatGPT responses to each question and asked to guess which response corresponded to which source. They then graded ChatGPT responses using the same criteria as Panel 1. Question-specific and overall mean grades for ChatGPT responses, as well as interclass correlation coefficient (ICC) as a measure of interrater reliability, were calculated.</p><p><strong>Results: </strong>The overall mean grade for ChatGPT responses was 1.65/3. For 2 out of 10 questions, ChatGPT responses were equal to or better than expert responses. However, for 8 out of 10 questions, ChatGPT provided responses that were incorrect, false, or incomplete based on mean rater grades. Overall ICC was 0.526, indicating moderate reliability among raters of ChatGPT responses. Reviewers were able to discern ChatGPT from human responses with 97.5% accuracy.</p><p><strong>Conclusion: </strong>This preliminary study demonstrates overall near-complete and variably accurate responses provided by ChatGPT to common rhinologic questions, demonstrating important limitations in nuanced subspecialty fields.</p>","PeriodicalId":19697,"journal":{"name":"OTO Open","volume":"9 1","pages":"e70065"},"PeriodicalIF":1.8000,"publicationDate":"2025-01-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11705442/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"OTO Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1002/oto2.70065","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"OTORHINOLARYNGOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: To analyze the accuracy of ChatGPT-generated responses to common rhinologic patient questions.
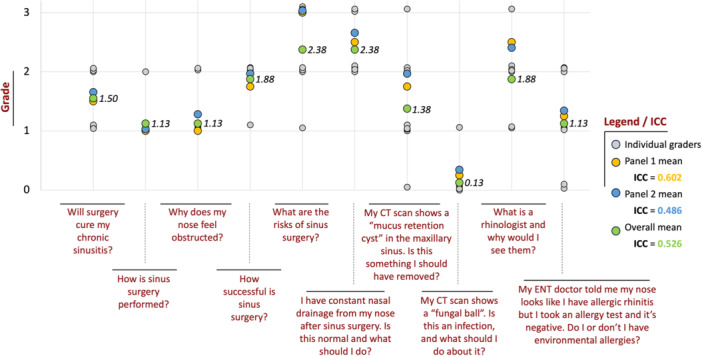
Methods: Ten common questions from rhinology patients were compiled by a panel of 4 rhinology fellowship-trained surgeons based on clinical patient experience. This panel (Panel 1) developed consensus "expert" responses to each question. Questions were individually posed to ChatGPT (version 3.5) and its responses recorded. ChatGPT-generated responses were individually graded by Panel 1 on a scale of 0 (incorrect) to 3 (correct and exceeding the quality of expert responses). A 2nd panel was given the consensus and ChatGPT responses to each question and asked to guess which response corresponded to which source. They then graded ChatGPT responses using the same criteria as Panel 1. Question-specific and overall mean grades for ChatGPT responses, as well as interclass correlation coefficient (ICC) as a measure of interrater reliability, were calculated.
Results: The overall mean grade for ChatGPT responses was 1.65/3. For 2 out of 10 questions, ChatGPT responses were equal to or better than expert responses. However, for 8 out of 10 questions, ChatGPT provided responses that were incorrect, false, or incomplete based on mean rater grades. Overall ICC was 0.526, indicating moderate reliability among raters of ChatGPT responses. Reviewers were able to discern ChatGPT from human responses with 97.5% accuracy.
Conclusion: This preliminary study demonstrates overall near-complete and variably accurate responses provided by ChatGPT to common rhinologic questions, demonstrating important limitations in nuanced subspecialty fields.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
