{"title":"An augmented transformer model trained on protein family specific variant data leads to improved prediction of variants of uncertain significance.","authors":"Dinesh Joshi, Swatantra Pradhan, Rakshanda Sajeed, Rajgopal Srinivasan, Sadhna Rana","doi":"10.1007/s00439-025-02727-z","DOIUrl":null,"url":null,"abstract":"<p><p>Variants of uncertain significance (VUS) represent variants that lack sufficient evidence to be confidently associated with a disease, thus posing a challenge in the interpretation of genetic testing results. Here we report an improved method for predicting the VUS of Arylsulfatase A (ARSA) gene as part of the Critical Assessment of Genome Interpretation challenge (CAGI6). Our method uses a transfer learning approach that leverages a pre-trained protein language model to predict the impact of mutations on the activity of the ARSA enzyme, whose deficiency is known to cause a rare genetic disorder, metachromatic leukodystrophy. Our innovative framework combines zero-shot log odds scores and embeddings from the ESM, an evolutionary scale model as features for training a supervised model on gene variants functionally related to the ARSA gene. The zero-shot log odds score feature captures the generic properties of the proteins learned due to its pre-training on millions of sequences in the UniProt data, while the ESM embeddings for the proteins in the ARSA family capture features specific to the family. We also tested our approach on another enzyme, N-acetyl-glucosaminidase (NAGLU), that belongs to the same superfamily as ARSA. Our results demonstrate that the performance of our family models (augmented ESM models) is either comparable or better than the ESM models. The ARSA model compares favorably with the majority of state-of-the-art predictors on area under precision and recall curve (AUPRC) performance metric. However, the NAGLU model outperforms all pathogenicity predictors evaluated in this study on AUPRC metric. The improved AUPRC has relevance in a diagnostic setting where variant prioritization generally entails identifying a small number of pathogenic variants from a larger number of benign variants. Our results also indicate that genes that have sparse or no experimental variant impact data, the family variant data can serve as a proxy training data for making accurate predictions. Attention analysis of active sites and binding sites in ARSA and NAGLU proteins shed light on probable mechanisms of pathogenicity for positions that are highly attended.</p>","PeriodicalId":13175,"journal":{"name":"Human Genetics","volume":" ","pages":"143-158"},"PeriodicalIF":3.6000,"publicationDate":"2025-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12166291/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Human Genetics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1007/s00439-025-02727-z","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/27 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
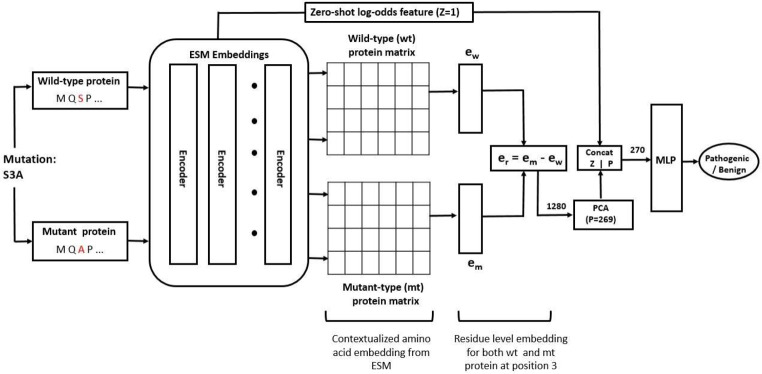
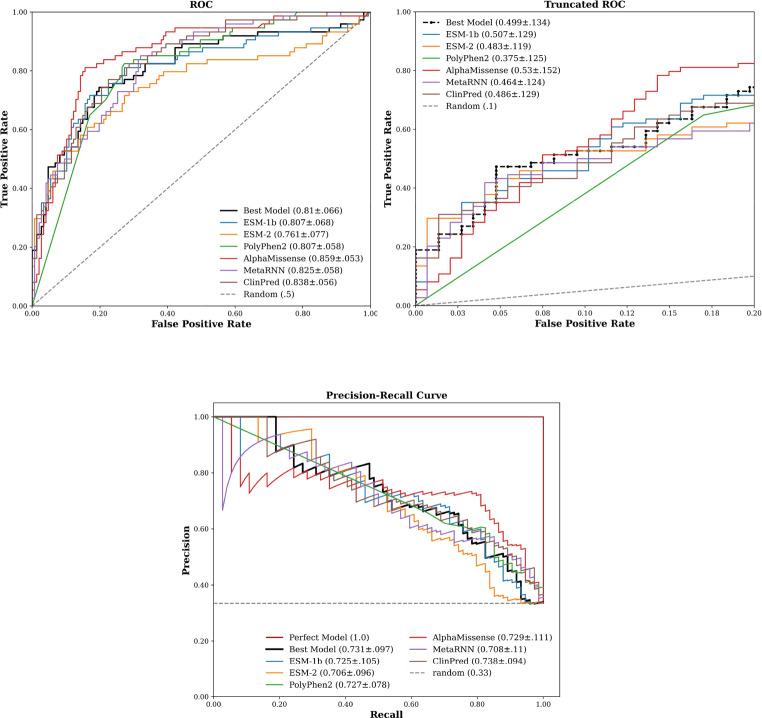
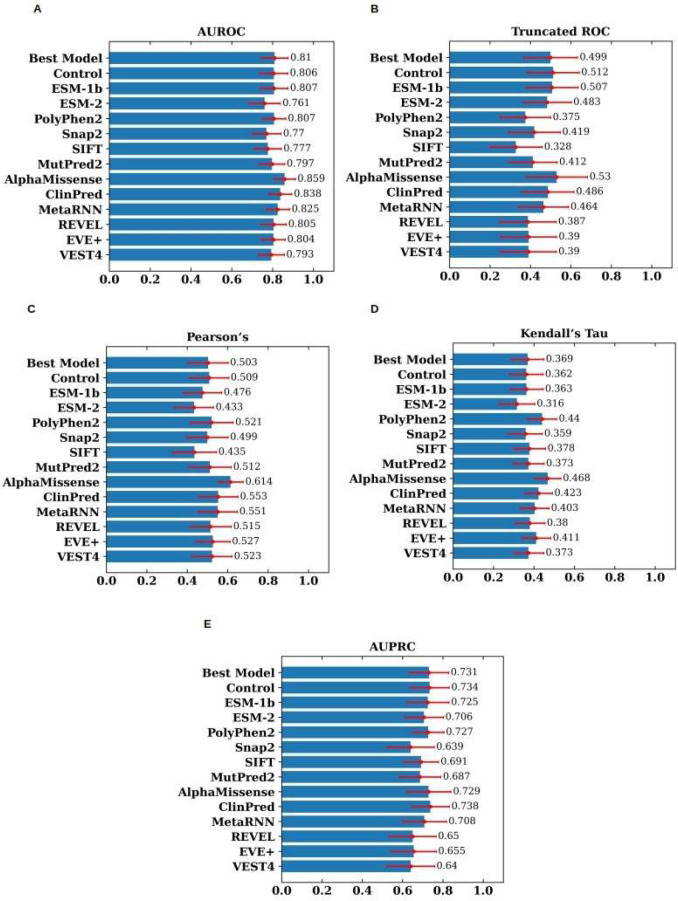
Variants of uncertain significance (VUS) represent variants that lack sufficient evidence to be confidently associated with a disease, thus posing a challenge in the interpretation of genetic testing results. Here we report an improved method for predicting the VUS of Arylsulfatase A (ARSA) gene as part of the Critical Assessment of Genome Interpretation challenge (CAGI6). Our method uses a transfer learning approach that leverages a pre-trained protein language model to predict the impact of mutations on the activity of the ARSA enzyme, whose deficiency is known to cause a rare genetic disorder, metachromatic leukodystrophy. Our innovative framework combines zero-shot log odds scores and embeddings from the ESM, an evolutionary scale model as features for training a supervised model on gene variants functionally related to the ARSA gene. The zero-shot log odds score feature captures the generic properties of the proteins learned due to its pre-training on millions of sequences in the UniProt data, while the ESM embeddings for the proteins in the ARSA family capture features specific to the family. We also tested our approach on another enzyme, N-acetyl-glucosaminidase (NAGLU), that belongs to the same superfamily as ARSA. Our results demonstrate that the performance of our family models (augmented ESM models) is either comparable or better than the ESM models. The ARSA model compares favorably with the majority of state-of-the-art predictors on area under precision and recall curve (AUPRC) performance metric. However, the NAGLU model outperforms all pathogenicity predictors evaluated in this study on AUPRC metric. The improved AUPRC has relevance in a diagnostic setting where variant prioritization generally entails identifying a small number of pathogenic variants from a larger number of benign variants. Our results also indicate that genes that have sparse or no experimental variant impact data, the family variant data can serve as a proxy training data for making accurate predictions. Attention analysis of active sites and binding sites in ARSA and NAGLU proteins shed light on probable mechanisms of pathogenicity for positions that are highly attended.
不确定意义变异(VUS)表示缺乏足够证据来确定与疾病相关的变异,因此对基因检测结果的解释提出了挑战。在这里,我们报告了一种改进的方法来预测Arylsulfatase A (ARSA)基因的VUS,作为基因组解释挑战的关键评估(CAGI6)的一部分。我们的方法使用迁移学习方法,利用预训练的蛋白质语言模型来预测突变对ARSA酶活性的影响,已知ARSA酶的缺乏会导致一种罕见的遗传疾病,异色性脑白质营养不良。我们的创新框架结合了零投对数赔率分数和ESM的嵌入,ESM是一种进化尺度模型,作为训练与ARSA基因功能相关的基因变异的监督模型的特征。零射击对数赔率得分特征捕获了由于对UniProt数据中数百万序列的预训练而学习到的蛋白质的通用特性,而ARSA家族中蛋白质的ESM嵌入捕获了该家族特有的特征。我们还在与ARSA属于同一超家族的另一种酶n -乙酰氨基葡萄糖酶(NAGLU)上测试了我们的方法。我们的结果表明,我们的家族模型(增强ESM模型)的性能与ESM模型相当或更好。ARSA模型在精确度下面积和召回曲线(AUPRC)性能指标上优于大多数最先进的预测器。然而,NAGLU模型在AUPRC度量上优于本研究中评估的所有致病性预测因子。改进的AUPRC在诊断环境中具有相关性,其中变异优先级通常需要从大量良性变异中识别少量致病变异。我们的研究结果还表明,具有稀疏或没有实验变异影响数据的基因,家族变异数据可以作为代理训练数据进行准确预测。对ARSA和NAGLU蛋白活性位点和结合位点的关注分析揭示了这些备受关注的位点的可能致病机制。
期刊介绍:
Human Genetics is a monthly journal publishing original and timely articles on all aspects of human genetics. The Journal particularly welcomes articles in the areas of Behavioral genetics, Bioinformatics, Cancer genetics and genomics, Cytogenetics, Developmental genetics, Disease association studies, Dysmorphology, ELSI (ethical, legal and social issues), Evolutionary genetics, Gene expression, Gene structure and organization, Genetics of complex diseases and epistatic interactions, Genetic epidemiology, Genome biology, Genome structure and organization, Genotype-phenotype relationships, Human Genomics, Immunogenetics and genomics, Linkage analysis and genetic mapping, Methods in Statistical Genetics, Molecular diagnostics, Mutation detection and analysis, Neurogenetics, Physical mapping and Population Genetics. Articles reporting animal models relevant to human biology or disease are also welcome. Preference will be given to those articles which address clinically relevant questions or which provide new insights into human biology.
Unless reporting entirely novel and unusual aspects of a topic, clinical case reports, cytogenetic case reports, papers on descriptive population genetics, articles dealing with the frequency of polymorphisms or additional mutations within genes in which numerous lesions have already been described, and papers that report meta-analyses of previously published datasets will normally not be accepted.
The Journal typically will not consider for publication manuscripts that report merely the isolation, map position, structure, and tissue expression profile of a gene of unknown function unless the gene is of particular interest or is a candidate gene involved in a human trait or disorder.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
