{"title":"A mixed-precision memristor and SRAM compute-in-memory AI processor","authors":"Win-San Khwa, Tai-Hao Wen, Hung-Hsi Hsu, Wei-Hsing Huang, Yu-Chen Chang, Ting-Chien Chiu, Zhao-En Ke, Yu-Hsiang Chin, Hua-Jin Wen, Wei-Ting Hsu, Chung-Chuan Lo, Ren-Shuo Liu, Chih-Cheng Hsieh, Kea-Tiong Tang, Mon-Shu Ho, Ashwin Sanjay Lele, Shih-Hsin Teng, Chung-Cheng Chou, Yu-Der Chih, Tsung-Yung Jonathan Chang, Meng-Fan Chang","doi":"10.1038/s41586-025-08639-2","DOIUrl":null,"url":null,"abstract":"Artificial intelligence (AI) edge devices1–12 demand high-precision energy-efficient computations, large on-chip model storage, rapid wakeup-to-response time and cost-effective foundry-ready solutions. Floating point (FP) computation provides precision exceeding that of integer (INT) formats at the cost of higher power and storage overhead. Multi-level-cell (MLC) memristor compute-in-memory (CIM)13–15 provides compact non-volatile storage and energy-efficient computation but is prone to accuracy loss owing to process variation. Digital static random-access memory (SRAM)-CIM16–22 enables lossless computation; however, storage is low as a result of large bit-cell area and model loading is required during inference. Thus, conventional approaches using homogeneous CIM architectures and computation formats impose a trade-off between efficiency, storage, wakeup latency and inference accuracy. Here we present a mixed-precision heterogeneous CIM AI edge processor, which supports the layer-granular/kernel-granular partitioning of network layers among on-chip CIM architectures (that is, memristor-CIM, SRAM-CIM and tiny-digital units) and computation number formats (INT and FP) based on sensitivity to error. This layer-granular/kernel-granular flexibility allows simultaneous optimization within the two-dimensional design space at the hardware level. The proposed hardware achieved high energy efficiency (40.91 TFLOPS W−1 for ResNet-20 with CIFAR-100 and 28.63 TFLOPS W−1 for MobileNet-v2 with ImageNet), low accuracy degradation (<0.45% for ResNet-20 with CIFAR-100 and for MobilNet-v2 with ImageNet) and rapid wakeup-to-response time (373.52 μs). A mixed-precision heterogeneous memristor combined with a compute-in-memory artificial intelligence (AI) processor allows optimization of the precision, energy efficiency, storage and wakeup-to-response time requirements of AI edge devices, which is demonstrated using existing models and datasets.","PeriodicalId":18787,"journal":{"name":"Nature","volume":"639 8055","pages":"617-623"},"PeriodicalIF":48.5000,"publicationDate":"2025-03-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature","FirstCategoryId":"103","ListUrlMain":"https://www.nature.com/articles/s41586-025-08639-2","RegionNum":1,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
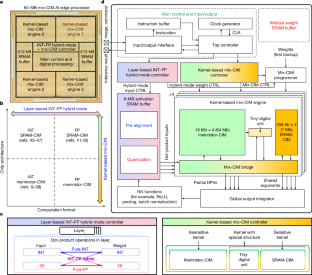
Artificial intelligence (AI) edge devices1–12 demand high-precision energy-efficient computations, large on-chip model storage, rapid wakeup-to-response time and cost-effective foundry-ready solutions. Floating point (FP) computation provides precision exceeding that of integer (INT) formats at the cost of higher power and storage overhead. Multi-level-cell (MLC) memristor compute-in-memory (CIM)13–15 provides compact non-volatile storage and energy-efficient computation but is prone to accuracy loss owing to process variation. Digital static random-access memory (SRAM)-CIM16–22 enables lossless computation; however, storage is low as a result of large bit-cell area and model loading is required during inference. Thus, conventional approaches using homogeneous CIM architectures and computation formats impose a trade-off between efficiency, storage, wakeup latency and inference accuracy. Here we present a mixed-precision heterogeneous CIM AI edge processor, which supports the layer-granular/kernel-granular partitioning of network layers among on-chip CIM architectures (that is, memristor-CIM, SRAM-CIM and tiny-digital units) and computation number formats (INT and FP) based on sensitivity to error. This layer-granular/kernel-granular flexibility allows simultaneous optimization within the two-dimensional design space at the hardware level. The proposed hardware achieved high energy efficiency (40.91 TFLOPS W−1 for ResNet-20 with CIFAR-100 and 28.63 TFLOPS W−1 for MobileNet-v2 with ImageNet), low accuracy degradation (<0.45% for ResNet-20 with CIFAR-100 and for MobilNet-v2 with ImageNet) and rapid wakeup-to-response time (373.52 μs). A mixed-precision heterogeneous memristor combined with a compute-in-memory artificial intelligence (AI) processor allows optimization of the precision, energy efficiency, storage and wakeup-to-response time requirements of AI edge devices, which is demonstrated using existing models and datasets.
期刊介绍:
Nature is a prestigious international journal that publishes peer-reviewed research in various scientific and technological fields. The selection of articles is based on criteria such as originality, importance, interdisciplinary relevance, timeliness, accessibility, elegance, and surprising conclusions. In addition to showcasing significant scientific advances, Nature delivers rapid, authoritative, insightful news, and interpretation of current and upcoming trends impacting science, scientists, and the broader public. The journal serves a dual purpose: firstly, to promptly share noteworthy scientific advances and foster discussions among scientists, and secondly, to ensure the swift dissemination of scientific results globally, emphasizing their significance for knowledge, culture, and daily life.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
