Using ChatGPT to Improve the Presentation of Plain Language Summaries of Cochrane Systematic Reviews About Oncology Interventions: Cross-Sectional Study.
{"title":"Using ChatGPT to Improve the Presentation of Plain Language Summaries of Cochrane Systematic Reviews About Oncology Interventions: Cross-Sectional Study.","authors":"Jelena Šuto Pavičić, Ana Marušić, Ivan Buljan","doi":"10.2196/63347","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Plain language summaries (PLSs) of Cochrane systematic reviews are a simple format for presenting medical information to the lay public. This is particularly important in oncology, where patients have a more active role in decision-making. However, current PLS formats often exceed the readability requirements for the general population. There is still a lack of cost-effective and more automated solutions to this problem.</p><p><strong>Objective: </strong>This study assessed whether a large language model (eg, ChatGPT) can improve the readability and linguistic characteristics of Cochrane PLSs about oncology interventions, without changing evidence synthesis conclusions.</p><p><strong>Methods: </strong>The dataset included 275 scientific abstracts and corresponding PLSs of Cochrane systematic reviews about oncology interventions. ChatGPT-4 was tasked to make each scientific abstract into a PLS using 3 prompts as follows: (1) rewrite this scientific abstract into a PLS to achieve a Simple Measure of Gobbledygook (SMOG) index of 6, (2) rewrite the PLS from prompt 1 so it is more emotional, and (3) rewrite this scientific abstract so it is easier to read and more appropriate for the lay audience. ChatGPT-generated PLSs were analyzed for word count, level of readability (SMOG index), and linguistic characteristics using Linguistic Inquiry and Word Count (LIWC) software and compared with the original PLSs. Two independent assessors reviewed the conclusiveness categories of ChatGPT-generated PLSs and compared them with original abstracts to evaluate consistency. The conclusion of each abstract about the efficacy and safety of the intervention was categorized as conclusive (positive/negative/equal), inconclusive, or unclear. Group comparisons were conducted using the Friedman nonparametric test.</p><p><strong>Results: </strong>ChatGPT-generated PLSs using the first prompt (SMOG index 6) were the shortest and easiest to read, with a median SMOG score of 8.2 (95% CI 8-8.4), compared with the original PLSs (median SMOG score 13.1, 95% CI 12.9-13.4). These PLSs had a median word count of 240 (95% CI 232-248) compared with the original PLSs' median word count of 364 (95% CI 339-388). The second prompt (emotional tone) generated PLSs with a median SMOG score of 11.4 (95% CI 11.1-12), again lower than the original PLSs. PLSs produced with the third prompt (write simpler and easier) had a median SMOG score of 8.7 (95% CI 8.4-8.8). ChatGPT-generated PLSs across all prompts demonstrated reduced analytical tone and increased authenticity, clout, and emotional tone compared with the original PLSs. Importantly, the conclusiveness categorization of the original abstracts was unchanged in the ChatGPT-generated PLSs.</p><p><strong>Conclusions: </strong>ChatGPT can be a valuable tool in simplifying PLSs as medically related formats for lay audiences. More research is needed, including oversight mechanisms to ensure that the information is accurate, reliable, and culturally relevant for different audiences.</p>","PeriodicalId":45538,"journal":{"name":"JMIR Cancer","volume":"11 ","pages":"e63347"},"PeriodicalIF":2.7000,"publicationDate":"2025-03-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11939027/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Cancer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/63347","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Plain language summaries (PLSs) of Cochrane systematic reviews are a simple format for presenting medical information to the lay public. This is particularly important in oncology, where patients have a more active role in decision-making. However, current PLS formats often exceed the readability requirements for the general population. There is still a lack of cost-effective and more automated solutions to this problem.
Objective: This study assessed whether a large language model (eg, ChatGPT) can improve the readability and linguistic characteristics of Cochrane PLSs about oncology interventions, without changing evidence synthesis conclusions.
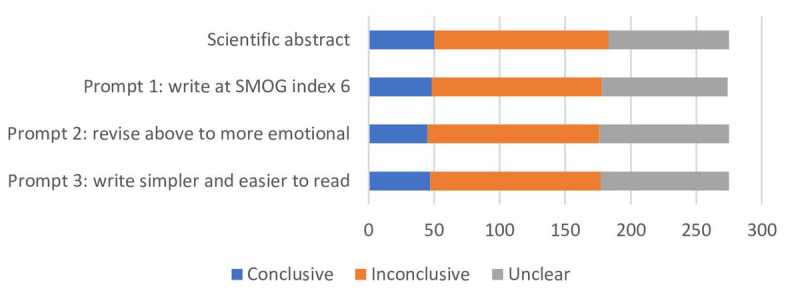
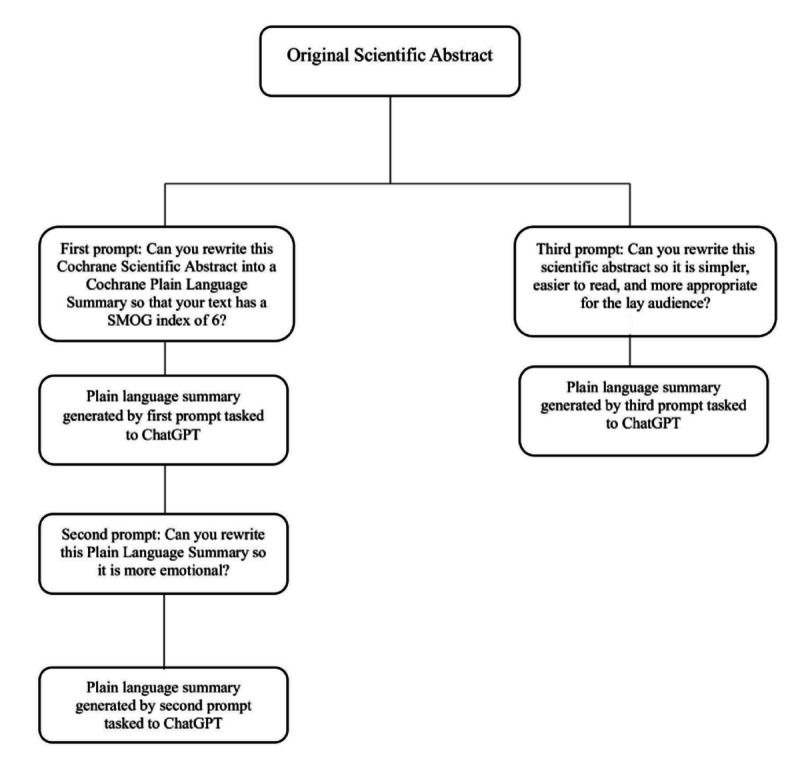
Methods: The dataset included 275 scientific abstracts and corresponding PLSs of Cochrane systematic reviews about oncology interventions. ChatGPT-4 was tasked to make each scientific abstract into a PLS using 3 prompts as follows: (1) rewrite this scientific abstract into a PLS to achieve a Simple Measure of Gobbledygook (SMOG) index of 6, (2) rewrite the PLS from prompt 1 so it is more emotional, and (3) rewrite this scientific abstract so it is easier to read and more appropriate for the lay audience. ChatGPT-generated PLSs were analyzed for word count, level of readability (SMOG index), and linguistic characteristics using Linguistic Inquiry and Word Count (LIWC) software and compared with the original PLSs. Two independent assessors reviewed the conclusiveness categories of ChatGPT-generated PLSs and compared them with original abstracts to evaluate consistency. The conclusion of each abstract about the efficacy and safety of the intervention was categorized as conclusive (positive/negative/equal), inconclusive, or unclear. Group comparisons were conducted using the Friedman nonparametric test.
Results: ChatGPT-generated PLSs using the first prompt (SMOG index 6) were the shortest and easiest to read, with a median SMOG score of 8.2 (95% CI 8-8.4), compared with the original PLSs (median SMOG score 13.1, 95% CI 12.9-13.4). These PLSs had a median word count of 240 (95% CI 232-248) compared with the original PLSs' median word count of 364 (95% CI 339-388). The second prompt (emotional tone) generated PLSs with a median SMOG score of 11.4 (95% CI 11.1-12), again lower than the original PLSs. PLSs produced with the third prompt (write simpler and easier) had a median SMOG score of 8.7 (95% CI 8.4-8.8). ChatGPT-generated PLSs across all prompts demonstrated reduced analytical tone and increased authenticity, clout, and emotional tone compared with the original PLSs. Importantly, the conclusiveness categorization of the original abstracts was unchanged in the ChatGPT-generated PLSs.
Conclusions: ChatGPT can be a valuable tool in simplifying PLSs as medically related formats for lay audiences. More research is needed, including oversight mechanisms to ensure that the information is accurate, reliable, and culturally relevant for different audiences.
背景:Cochrane系统评价的简单语言摘要(pls)是一种向公众展示医学信息的简单格式。这在肿瘤学中尤其重要,因为患者在决策中扮演着更积极的角色。然而,当前的PLS格式经常超出一般人群的可读性要求。对于这个问题,仍然缺乏成本效益高、自动化程度更高的解决方案。目的:本研究评估在不改变证据合成结论的情况下,大型语言模型(如ChatGPT)是否可以提高肿瘤干预Cochrane pls的可读性和语言特征。方法:数据集包括275篇关于肿瘤干预的Cochrane系统综述的科学摘要和相应的pls。ChatGPT-4的任务是使用以下3个提示将每个科学摘要转换为PLS:(1)将该科学摘要重写为PLS,以实现简单测量的Gobbledygook (SMOG)指数为6,(2)从提示1重写PLS,使其更情绪化,(3)重写该科学摘要,使其更容易阅读,更适合非专业观众。使用语言查询和单词计数(LIWC)软件分析chatgpt生成的pls的字数、可读性水平(SMOG指数)和语言特征,并与原始pls进行比较。两名独立评估人员审查了chatgpt生成的pls的结论性类别,并将其与原始摘要进行比较,以评估一致性。关于干预的有效性和安全性的每个摘要的结论被分类为结论性(阳性/阴性/相等)、不确定性或不明确。采用Friedman非参数检验进行组间比较。结果:使用第一个提示(烟雾指数6)的chatgpt生成的pls最短,最容易阅读,与原始pls(烟雾中位数评分13.1,95% CI 12.9-13.4)相比,烟雾中位数评分为8.2 (95% CI 8-8.4)。这些pls的中位数字数为240 (95% CI为232-248),而原始pls的中位数字数为364 (95% CI为339-388)。第二个提示(情绪语气)产生的pls中位数烟雾评分为11.4 (95% CI 11.1-12),再次低于原始pls。使用第三种提示(写得更简单和更容易)生成的pls的烟雾评分中位数为8.7 (95% CI 8.4-8.8)。与原始的pls相比,chatgpt生成的pls在所有提示中显示出减少的分析语气和增加的真实性、影响力和情感语气。重要的是,原始摘要的结论性分类在chatgpt生成的pl中没有变化。结论:ChatGPT是一种有价值的工具,可以简化pls作为外行观众的医学相关格式。需要进行更多的研究,包括监督机制,以确保信息准确、可靠,并与不同受众的文化相关。




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
