Loriano Storchi, Laura Bellentani, Jeff Hammond, Sergio Orlandini, Leonardo Pacifici, Nicoló Antonini, Leonardo Belpassi
{"title":"Acceleration of the Relativistic Dirac-Kohn-Sham Method with GPU: A Pre-Exascale Implementation of BERTHA and PyBERTHA.","authors":"Loriano Storchi, Laura Bellentani, Jeff Hammond, Sergio Orlandini, Leonardo Pacifici, Nicoló Antonini, Leonardo Belpassi","doi":"10.1021/acs.jctc.4c01759","DOIUrl":null,"url":null,"abstract":"<p><p>In this paper, we present the recent advances in the computation of the Dirac-Kohn-Sham (DKS) method of the BERTHA code. We show here that the simple underlined structure of the FORTRAN code also favors efficient porting of the code to GPUs, leading to a particularly efficient hybrid CPU/GPU implementation (OpenMP/OpenACC), where the most computationally intensive part for DKS matrix evaluation (three-center two-electron integrals evaluated via the McMurchie-Davidson scheme) is efficiently offloaded to the GPU via compiler directives based on the OpenACC programming model. This scheme in combination with the use of a linear algebra library optimized for GPUs (cuBLAS, cuSOLVER) significantly accelerates the DKS calculations. In addition, the low-level integral kernel developed here at FORTRAN level was used to port our real-time DKS (RT-TDDKS) implementation based on Python (PyBERTHART) for the utilization of the GPU. The results obtained on the new Tier-0 EuroHPC supercomputer (LEONARDO) of the CINECA Supercomputing Centre with a single NVIDIA A100 card are very satisfactory. We achieve a speedup up to 30 for Au<sub>16</sub> in a single-point DKS energy calculation and up to 10 for the Au<sub>8</sub> systems in an RT-TDDKS calculation, compared to our OpenMP (i.e., CPU only) parallel implementation (with 32 cores). The approach presented here is very general and, to our knowledge, represents the first port of a Python API to GPUs based on a FORTRAN kernel for the evaluation of two-electron integrals. The implementation is currently limited to the use of a single GPU accelerator, but future paths to an actual exascale implementation are discussed.</p>","PeriodicalId":45,"journal":{"name":"Journal of Chemical Theory and Computation","volume":" ","pages":"3460-3475"},"PeriodicalIF":5.5000,"publicationDate":"2025-04-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11983715/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemical Theory and Computation","FirstCategoryId":"92","ListUrlMain":"https://doi.org/10.1021/acs.jctc.4c01759","RegionNum":1,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/3/21 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"CHEMISTRY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
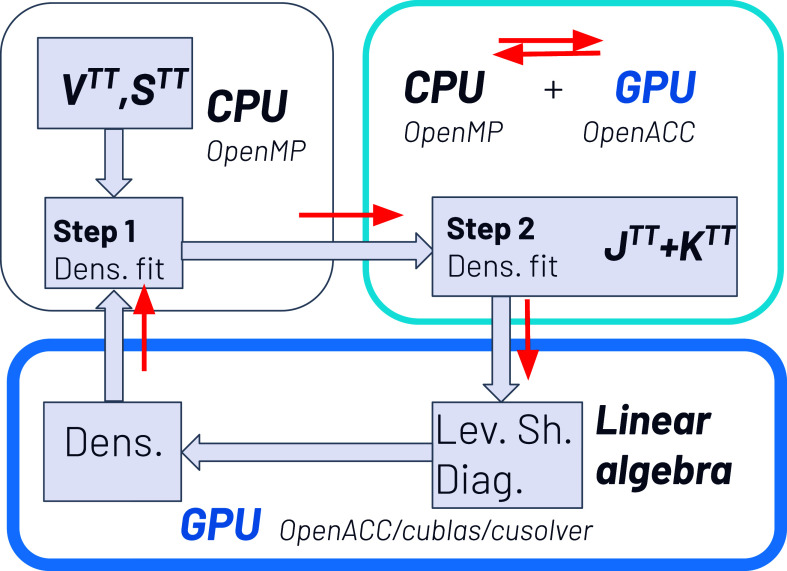
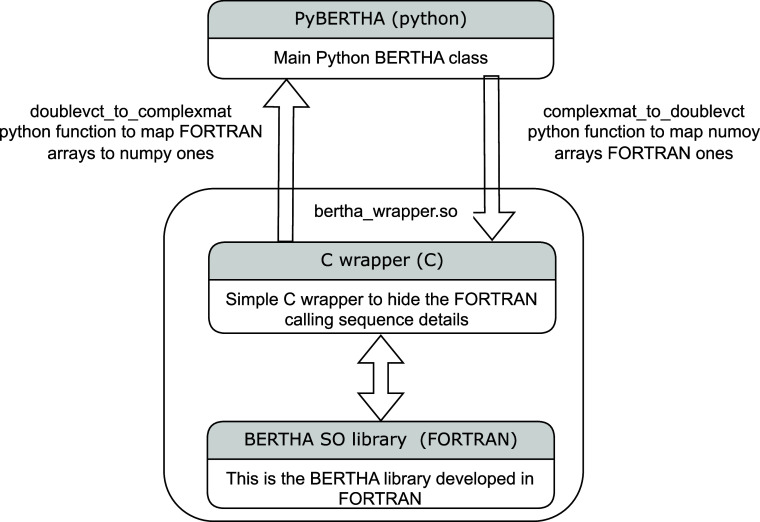
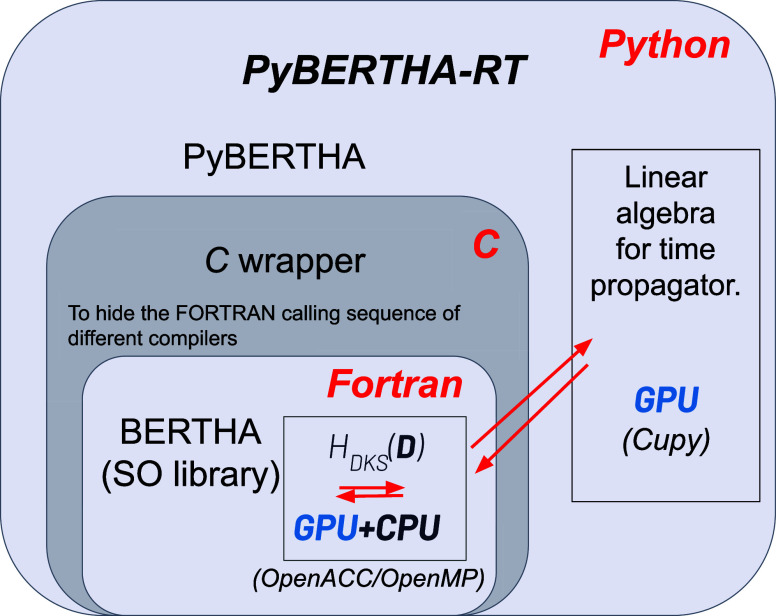
In this paper, we present the recent advances in the computation of the Dirac-Kohn-Sham (DKS) method of the BERTHA code. We show here that the simple underlined structure of the FORTRAN code also favors efficient porting of the code to GPUs, leading to a particularly efficient hybrid CPU/GPU implementation (OpenMP/OpenACC), where the most computationally intensive part for DKS matrix evaluation (three-center two-electron integrals evaluated via the McMurchie-Davidson scheme) is efficiently offloaded to the GPU via compiler directives based on the OpenACC programming model. This scheme in combination with the use of a linear algebra library optimized for GPUs (cuBLAS, cuSOLVER) significantly accelerates the DKS calculations. In addition, the low-level integral kernel developed here at FORTRAN level was used to port our real-time DKS (RT-TDDKS) implementation based on Python (PyBERTHART) for the utilization of the GPU. The results obtained on the new Tier-0 EuroHPC supercomputer (LEONARDO) of the CINECA Supercomputing Centre with a single NVIDIA A100 card are very satisfactory. We achieve a speedup up to 30 for Au16 in a single-point DKS energy calculation and up to 10 for the Au8 systems in an RT-TDDKS calculation, compared to our OpenMP (i.e., CPU only) parallel implementation (with 32 cores). The approach presented here is very general and, to our knowledge, represents the first port of a Python API to GPUs based on a FORTRAN kernel for the evaluation of two-electron integrals. The implementation is currently limited to the use of a single GPU accelerator, but future paths to an actual exascale implementation are discussed.
期刊介绍:
The Journal of Chemical Theory and Computation invites new and original contributions with the understanding that, if accepted, they will not be published elsewhere. Papers reporting new theories, methodology, and/or important applications in quantum electronic structure, molecular dynamics, and statistical mechanics are appropriate for submission to this Journal. Specific topics include advances in or applications of ab initio quantum mechanics, density functional theory, design and properties of new materials, surface science, Monte Carlo simulations, solvation models, QM/MM calculations, biomolecular structure prediction, and molecular dynamics in the broadest sense including gas-phase dynamics, ab initio dynamics, biomolecular dynamics, and protein folding. The Journal does not consider papers that are straightforward applications of known methods including DFT and molecular dynamics. The Journal favors submissions that include advances in theory or methodology with applications to compelling problems.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
