Brett R South, Shuying Shen, Makoto Jones, Jennifer Garvin, Matthew H Samore, Wendy W Chapman, Adi V Gundlapalli
{"title":"Developing a manually annotated clinical document corpus to identify phenotypic information for inflammatory bowel disease.","authors":"Brett R South, Shuying Shen, Makoto Jones, Jennifer Garvin, Matthew H Samore, Wendy W Chapman, Adi V Gundlapalli","doi":"","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Natural Language Processing (NLP) systems can be used for specific Information Extraction (IE) tasks such as extracting phenotypic data from the electronic medical record (EMR). These data are useful for translational research and are often found only in free text clinical notes. A key required step for IE is the manual annotation of clinical corpora and the creation of a reference standard for (1) training and validation tasks and (2) to focus and clarify NLP system requirements. These tasks are time consuming, expensive, and require considerable effort on the part of human reviewers.</p><p><strong>Methods: </strong>Using a set of clinical documents from the VA EMR for a particular use case of interest we identify specific challenges and present several opportunities for annotation tasks. We demonstrate specific methods using an open source annotation tool, a customized annotation schema, and a corpus of clinical documents for patients known to have a diagnosis of Inflammatory Bowel Disease (IBD). We report clinician annotator agreement at the document, concept, and concept attribute level. We estimate concept yield in terms of annotated concepts within specific note sections and document types.</p><p><strong>Results: </strong>Annotator agreement at the document level for documents that contained concepts of interest for IBD using estimated Kappa statistic (95% CI) was very high at 0.87 (0.82, 0.93). At the concept level, F-measure ranged from 0.61 to 0.83. However, agreement varied greatly at the specific concept attribute level. For this particular use case (IBD), clinical documents producing the highest concept yield per document included GI clinic notes and primary care notes. Within the various types of notes, the highest concept yield was in sections representing patient assessment and history of presenting illness. Ancillary service documents and family history and plan note sections produced the lowest concept yield.</p><p><strong>Conclusions: </strong>Challenges include defining and building appropriate annotation schemas, adequately training clinician annotators, and determining the appropriate level of information to be annotated. Opportunities include narrowing the focus of information extraction to use case specific note types and sections, especially in cases where NLP systems will be used to extract information from large repositories of electronic clinical note documents.</p>","PeriodicalId":89276,"journal":{"name":"Summit on translational bioinformatics","volume":"2009 ","pages":"1-32"},"PeriodicalIF":0.0000,"publicationDate":"2009-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3041557/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Summit on translational bioinformatics","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Natural Language Processing (NLP) systems can be used for specific Information Extraction (IE) tasks such as extracting phenotypic data from the electronic medical record (EMR). These data are useful for translational research and are often found only in free text clinical notes. A key required step for IE is the manual annotation of clinical corpora and the creation of a reference standard for (1) training and validation tasks and (2) to focus and clarify NLP system requirements. These tasks are time consuming, expensive, and require considerable effort on the part of human reviewers.
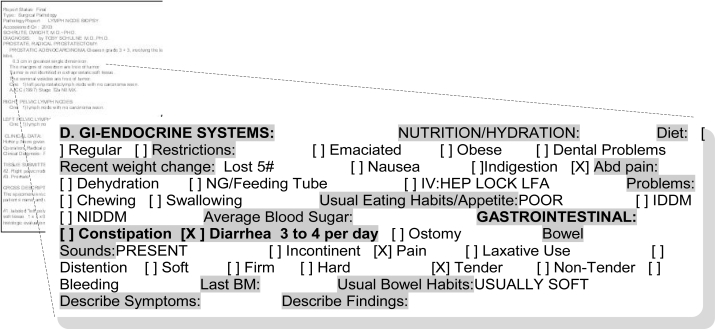
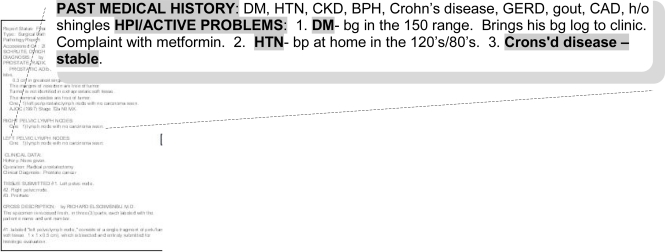
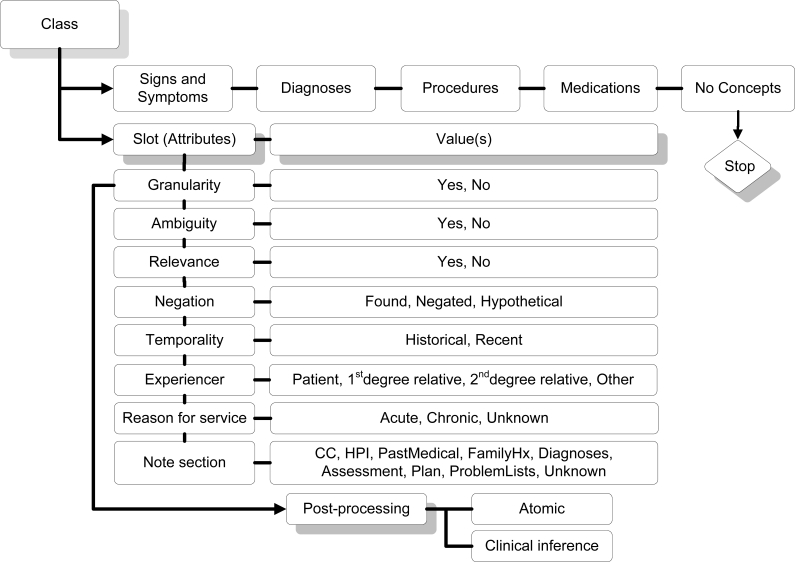
Methods: Using a set of clinical documents from the VA EMR for a particular use case of interest we identify specific challenges and present several opportunities for annotation tasks. We demonstrate specific methods using an open source annotation tool, a customized annotation schema, and a corpus of clinical documents for patients known to have a diagnosis of Inflammatory Bowel Disease (IBD). We report clinician annotator agreement at the document, concept, and concept attribute level. We estimate concept yield in terms of annotated concepts within specific note sections and document types.
Results: Annotator agreement at the document level for documents that contained concepts of interest for IBD using estimated Kappa statistic (95% CI) was very high at 0.87 (0.82, 0.93). At the concept level, F-measure ranged from 0.61 to 0.83. However, agreement varied greatly at the specific concept attribute level. For this particular use case (IBD), clinical documents producing the highest concept yield per document included GI clinic notes and primary care notes. Within the various types of notes, the highest concept yield was in sections representing patient assessment and history of presenting illness. Ancillary service documents and family history and plan note sections produced the lowest concept yield.
Conclusions: Challenges include defining and building appropriate annotation schemas, adequately training clinician annotators, and determining the appropriate level of information to be annotated. Opportunities include narrowing the focus of information extraction to use case specific note types and sections, especially in cases where NLP systems will be used to extract information from large repositories of electronic clinical note documents.
 分享
分享



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
