M.G.M. Kok , M.W.J. de Ronde , P.D. Moerland , J.M. Ruijter , E.E. Creemers , S.J. Pinto-Sietsma
{"title":"Small sample sizes in high-throughput miRNA screens: A common pitfall for the identification of miRNA biomarkers","authors":"M.G.M. Kok , M.W.J. de Ronde , P.D. Moerland , J.M. Ruijter , E.E. Creemers , S.J. Pinto-Sietsma","doi":"10.1016/j.bdq.2017.11.002","DOIUrl":null,"url":null,"abstract":"<div><p>Since the discovery of microRNAs (miRNAs), circulating miRNAs have been proposed as biomarkers for disease. Consequently, many groups have tried to identify circulating miRNA biomarkers for various types of diseases including cardiovascular disease and cancer. However, the replicability of these experiments has been disappointingly low. In order to identify circulating miRNA candidate biomarkers, in general, first an unbiased high-throughput screen is performed in which a large number of miRNAs is detected and quantified in the circulation. Because these are costly experiments, many of such studies have been performed using a low number of study subjects (small sample size). Due to lack of power in small sample size experiments, true effects are often missed and many of the detected effects are wrong. Therefore, it is important to have a good estimate of the appropriate sample size for a miRNA high-throughput screen. In this review, we discuss the effects of small sample sizes in high-throughput screens for circulating miRNAs. Using data from a miRNA high-throughput experiment on isolated monocytes, we illustrate that the implementation of power calculations in a high-throughput miRNA discovery experiment will avoid unnecessarily large and expensive experiments, while still having enough power to be able to detect clinically important differences.</p></div>","PeriodicalId":38073,"journal":{"name":"Biomolecular Detection and Quantification","volume":"15 ","pages":"Pages 1-5"},"PeriodicalIF":0.0000,"publicationDate":"2018-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1016/j.bdq.2017.11.002","citationCount":"67","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomolecular Detection and Quantification","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2214753517302103","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2017/12/18 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"Biochemistry, Genetics and Molecular Biology","Score":null,"Total":0}
引用次数: 67
Abstract
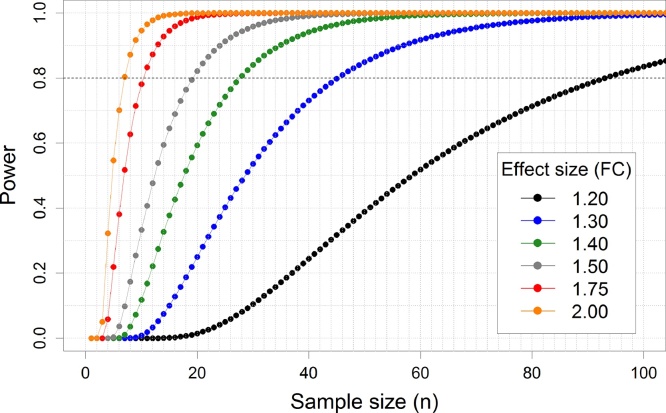
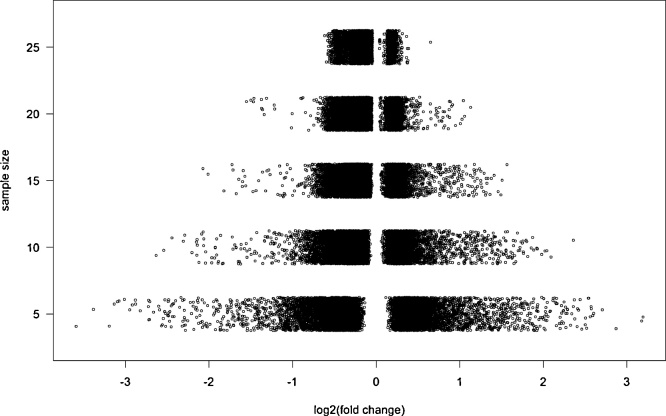
Since the discovery of microRNAs (miRNAs), circulating miRNAs have been proposed as biomarkers for disease. Consequently, many groups have tried to identify circulating miRNA biomarkers for various types of diseases including cardiovascular disease and cancer. However, the replicability of these experiments has been disappointingly low. In order to identify circulating miRNA candidate biomarkers, in general, first an unbiased high-throughput screen is performed in which a large number of miRNAs is detected and quantified in the circulation. Because these are costly experiments, many of such studies have been performed using a low number of study subjects (small sample size). Due to lack of power in small sample size experiments, true effects are often missed and many of the detected effects are wrong. Therefore, it is important to have a good estimate of the appropriate sample size for a miRNA high-throughput screen. In this review, we discuss the effects of small sample sizes in high-throughput screens for circulating miRNAs. Using data from a miRNA high-throughput experiment on isolated monocytes, we illustrate that the implementation of power calculations in a high-throughput miRNA discovery experiment will avoid unnecessarily large and expensive experiments, while still having enough power to be able to detect clinically important differences.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
