Mariusz Butkiewicz, Yanli Wang, Stephen H Bryant, Edward W Lowe, David C Weaver, Jens Meiler
{"title":"High-Throughput Screening Assay Datasets from the PubChem Database.","authors":"Mariusz Butkiewicz, Yanli Wang, Stephen H Bryant, Edward W Lowe, David C Weaver, Jens Meiler","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Availability of high-throughput screening (HTS) data in the public domain offers great potential to foster development of ligand-based computer-aided drug discovery (LB-CADD) methods crucial for drug discovery efforts in academia and industry. LB-CADD method development depends on high-quality HTS assay data, i.e., datasets that contain both active and inactive compounds. These active compounds are hits from primary screens that have been tested in concentration-response experiments and where the target-specificity of the hits has been validated through suitable secondary screening experiments. Publicly available HTS repositories such as PubChem often provide such data in a convoluted way: compounds that are classified as inactive need to be extracted from the primary screening record. However, compounds classified as active in the primary screening record are not suitable as a set of active compounds for LB-CADD experiments due to high false-positive rate. A suitable set of actives can be derived by carefully analysing results in often up to five or more assays that are used to confirm and classify the activity of compounds. These assays, in part, build on each other. However, often not all hit compounds from the previous screen have been tested. Sometimes a compound can be classified as 'active', though its meaning is 'inactive' on the target of interest as it is 'active' on a different target protein. Here, a curation process of hierarchically related confirmatory screens is illustrated based on two specifically chosen protein use-cases. The subsequent re-upload procedure into PubChem is described for the findings of those two scenarios. Further, we provide nine publicly accessible high quality datasets for future LB-CADD method development that provide a common baseline for comparison of future methods to the scientific community. We also provide a protocol researchers can follow to upload additional datasets for benchmarking.</p>","PeriodicalId":92340,"journal":{"name":"Chemical informatics (Wilmington, Del.)","volume":"3 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2017-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/e1/a7/nihms936862.PMC5962024.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Chemical informatics (Wilmington, Del.)","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2017/4/26 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
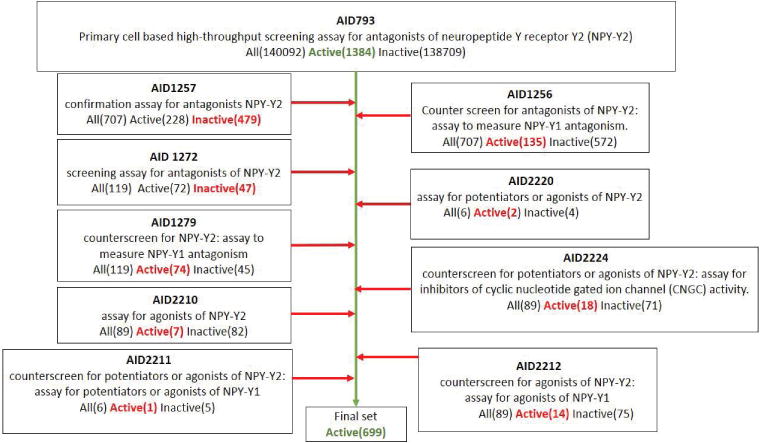
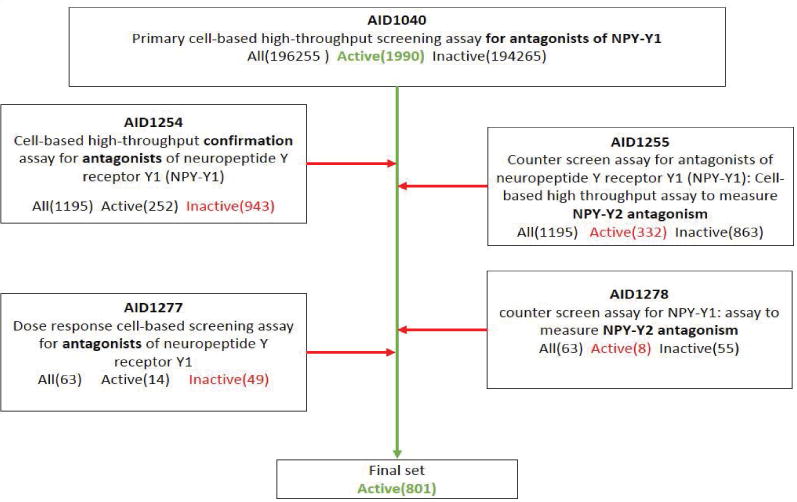
Availability of high-throughput screening (HTS) data in the public domain offers great potential to foster development of ligand-based computer-aided drug discovery (LB-CADD) methods crucial for drug discovery efforts in academia and industry. LB-CADD method development depends on high-quality HTS assay data, i.e., datasets that contain both active and inactive compounds. These active compounds are hits from primary screens that have been tested in concentration-response experiments and where the target-specificity of the hits has been validated through suitable secondary screening experiments. Publicly available HTS repositories such as PubChem often provide such data in a convoluted way: compounds that are classified as inactive need to be extracted from the primary screening record. However, compounds classified as active in the primary screening record are not suitable as a set of active compounds for LB-CADD experiments due to high false-positive rate. A suitable set of actives can be derived by carefully analysing results in often up to five or more assays that are used to confirm and classify the activity of compounds. These assays, in part, build on each other. However, often not all hit compounds from the previous screen have been tested. Sometimes a compound can be classified as 'active', though its meaning is 'inactive' on the target of interest as it is 'active' on a different target protein. Here, a curation process of hierarchically related confirmatory screens is illustrated based on two specifically chosen protein use-cases. The subsequent re-upload procedure into PubChem is described for the findings of those two scenarios. Further, we provide nine publicly accessible high quality datasets for future LB-CADD method development that provide a common baseline for comparison of future methods to the scientific community. We also provide a protocol researchers can follow to upload additional datasets for benchmarking.
 分享
分享



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
