Lei Chen, Rui Liu, Dongsheng Zhou, Xin Yang, Qiang Zhang
{"title":"Fused behavior recognition model based on attention mechanism.","authors":"Lei Chen, Rui Liu, Dongsheng Zhou, Xin Yang, Qiang Zhang","doi":"10.1186/s42492-020-00045-x","DOIUrl":null,"url":null,"abstract":"<p><p>With the rapid development of deep learning technology, behavior recognition based on video streams has made great progress in recent years. However, there are also some problems that must be solved: (1) In order to improve behavior recognition performance, the models have tended to become deeper, wider, and more complex. However, some new problems have been introduced also, such as that their real-time performance decreases; (2) Some actions in existing datasets are so similar that they are difficult to distinguish. To solve these problems, the ResNet34-3DRes18 model, which is a lightweight and efficient two-dimensional (2D) and three-dimensional (3D) fused model, is constructed in this study. The model used 2D convolutional neural network (2DCNN) to obtain the feature maps of input images and 3D convolutional neural network (3DCNN) to process the temporal relationships between frames, which made the model not only make use of 3DCNN's advantages on video temporal modeling but reduced model complexity. Compared with state-of-the-art models, this method has shown excellent performance at a faster speed. Furthermore, to distinguish between similar motions in the datasets, an attention gate mechanism is added, and a Res34-SE-IM-Net attention recognition model is constructed. The Res34-SE-IM-Net achieved 71.85%, 92.196%, and 36.5% top-1 accuracy (The predicting label obtained from model is the largest one in the output probability vector. If the label is the same as the target label of the motion, the classification is correct.) respectively on the test sets of the HMDB51, UCF101, and Something-Something v1 datasets.</p>","PeriodicalId":52384,"journal":{"name":"Visual Computing for Industry, Biomedicine, and Art","volume":"3 1","pages":"7"},"PeriodicalIF":6.0000,"publicationDate":"2020-03-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7099545/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Visual Computing for Industry, Biomedicine, and Art","FirstCategoryId":"1093","ListUrlMain":"https://doi.org/10.1186/s42492-020-00045-x","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Arts and Humanities","Score":null,"Total":0}
引用次数: 0
Abstract
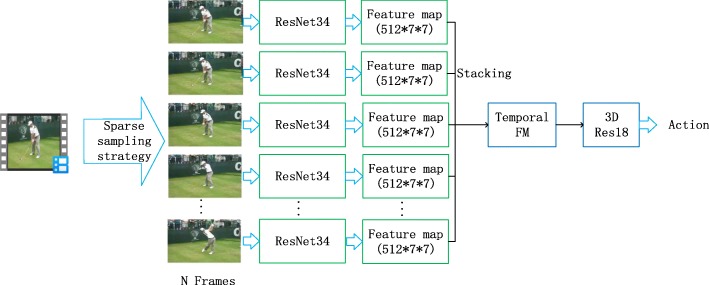
With the rapid development of deep learning technology, behavior recognition based on video streams has made great progress in recent years. However, there are also some problems that must be solved: (1) In order to improve behavior recognition performance, the models have tended to become deeper, wider, and more complex. However, some new problems have been introduced also, such as that their real-time performance decreases; (2) Some actions in existing datasets are so similar that they are difficult to distinguish. To solve these problems, the ResNet34-3DRes18 model, which is a lightweight and efficient two-dimensional (2D) and three-dimensional (3D) fused model, is constructed in this study. The model used 2D convolutional neural network (2DCNN) to obtain the feature maps of input images and 3D convolutional neural network (3DCNN) to process the temporal relationships between frames, which made the model not only make use of 3DCNN's advantages on video temporal modeling but reduced model complexity. Compared with state-of-the-art models, this method has shown excellent performance at a faster speed. Furthermore, to distinguish between similar motions in the datasets, an attention gate mechanism is added, and a Res34-SE-IM-Net attention recognition model is constructed. The Res34-SE-IM-Net achieved 71.85%, 92.196%, and 36.5% top-1 accuracy (The predicting label obtained from model is the largest one in the output probability vector. If the label is the same as the target label of the motion, the classification is correct.) respectively on the test sets of the HMDB51, UCF101, and Something-Something v1 datasets.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
