Antje Wulff, Marcel Mast, Marcus Hassler, Sara Montag, Michael Marschollek, Thomas Jack
{"title":"Designing an openEHR-Based Pipeline for Extracting and Standardizing Unstructured Clinical Data Using Natural Language Processing.","authors":"Antje Wulff, Marcel Mast, Marcus Hassler, Sara Montag, Michael Marschollek, Thomas Jack","doi":"10.1055/s-0040-1716403","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Merging disparate and heterogeneous datasets from clinical routine in a standardized and semantically enriched format to enable a multiple use of data also means incorporating unstructured data such as medical free texts. Although the extraction of structured data from texts, known as natural language processing (NLP), has been researched at least for the English language extensively, it is not enough to get a structured output in any format. NLP techniques need to be used together with clinical information standards such as openEHR to be able to reuse and exchange still unstructured data sensibly.</p><p><strong>Objectives: </strong>The aim of the study is to automatically extract crucial information from medical free texts and to transform this unstructured clinical data into a standardized and structured representation by designing and implementing an exemplary pipeline for the processing of pediatric medical histories.</p><p><strong>Methods: </strong>We constructed a pipeline that allows reusing medical free texts such as pediatric medical histories in a structured and standardized way by (1) selecting and modeling appropriate openEHR archetypes as standard clinical information models, (2) defining a German dictionary with crucial text markers serving as expert knowledge base for a NLP pipeline, and (3) creating mapping rules between the NLP output and the archetypes. The approach was evaluated in a first pilot study by using 50 manually annotated medical histories from the pediatric intensive care unit of the Hannover Medical School.</p><p><strong>Results: </strong>We successfully reused 24 existing international archetypes to represent the most crucial elements of unstructured pediatric medical histories in a standardized form. The self-developed NLP pipeline was constructed by defining 3.055 text marker entries, 132 text events, 66 regular expressions, and a text corpus consisting of 776 entries for automatic correction of spelling mistakes. A total of 123 mapping rules were implemented to transform the extracted snippets to an openEHR-based representation to be able to store them together with other structured data in an existing openEHR-based data repository. In the first evaluation, the NLP pipeline yielded 97% precision and 94% recall.</p><p><strong>Conclusion: </strong>The use of NLP and openEHR archetypes was demonstrated as a viable approach for extracting and representing important information from pediatric medical histories in a structured and semantically enriched format. We designed a promising approach with potential to be generalized, and implemented a prototype that is extensible and reusable for other use cases concerning German medical free texts. In a long term, this will harness unstructured clinical data for further research purposes such as the design of clinical decision support systems. Together with structured data already integrated in openEHR-based representations, we aim at developing an interoperable openEHR-based application that is capable of automatically assessing a patient's risk status based on the patient's medical history at time of admission.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":"59 S 02","pages":"e64-e78"},"PeriodicalIF":1.8000,"publicationDate":"2020-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1055/s-0040-1716403","citationCount":"9","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/s-0040-1716403","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2020/10/14 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 9
Abstract
Background: Merging disparate and heterogeneous datasets from clinical routine in a standardized and semantically enriched format to enable a multiple use of data also means incorporating unstructured data such as medical free texts. Although the extraction of structured data from texts, known as natural language processing (NLP), has been researched at least for the English language extensively, it is not enough to get a structured output in any format. NLP techniques need to be used together with clinical information standards such as openEHR to be able to reuse and exchange still unstructured data sensibly.
Objectives: The aim of the study is to automatically extract crucial information from medical free texts and to transform this unstructured clinical data into a standardized and structured representation by designing and implementing an exemplary pipeline for the processing of pediatric medical histories.
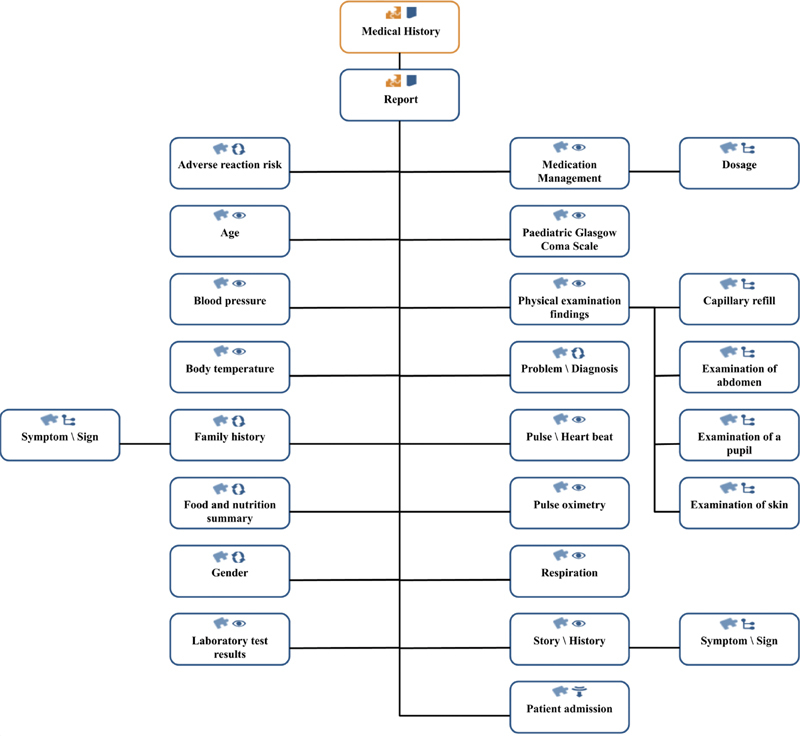
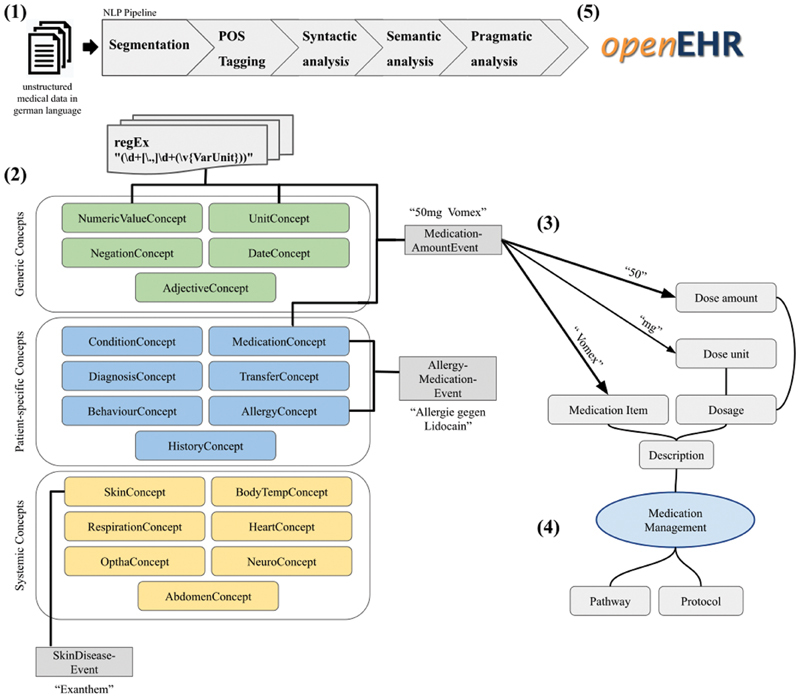
Methods: We constructed a pipeline that allows reusing medical free texts such as pediatric medical histories in a structured and standardized way by (1) selecting and modeling appropriate openEHR archetypes as standard clinical information models, (2) defining a German dictionary with crucial text markers serving as expert knowledge base for a NLP pipeline, and (3) creating mapping rules between the NLP output and the archetypes. The approach was evaluated in a first pilot study by using 50 manually annotated medical histories from the pediatric intensive care unit of the Hannover Medical School.
Results: We successfully reused 24 existing international archetypes to represent the most crucial elements of unstructured pediatric medical histories in a standardized form. The self-developed NLP pipeline was constructed by defining 3.055 text marker entries, 132 text events, 66 regular expressions, and a text corpus consisting of 776 entries for automatic correction of spelling mistakes. A total of 123 mapping rules were implemented to transform the extracted snippets to an openEHR-based representation to be able to store them together with other structured data in an existing openEHR-based data repository. In the first evaluation, the NLP pipeline yielded 97% precision and 94% recall.
Conclusion: The use of NLP and openEHR archetypes was demonstrated as a viable approach for extracting and representing important information from pediatric medical histories in a structured and semantically enriched format. We designed a promising approach with potential to be generalized, and implemented a prototype that is extensible and reusable for other use cases concerning German medical free texts. In a long term, this will harness unstructured clinical data for further research purposes such as the design of clinical decision support systems. Together with structured data already integrated in openEHR-based representations, we aim at developing an interoperable openEHR-based application that is capable of automatically assessing a patient's risk status based on the patient's medical history at time of admission.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
