{"title":"Learning and Planning for Time-Varying MDPs Using Maximum Likelihood Estimation.","authors":"Melkior Ornik, Ufuk Topcu","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>This paper proposes a formal approach to online learning and planning for agents operating in a priori unknown, time-varying environments. The proposed method computes the maximally likely model of the environment, given the observations about the environment made by an agent earlier in the system run and assuming knowledge of a bound on the maximal rate of change of system dynamics. Such an approach generalizes the estimation method commonly used in learning algorithms for unknown Markov decision processes with time-invariant transition probabilities, but is also able to quickly and correctly identify the system dynamics following a change. Based on the proposed method, we generalize the exploration bonuses used in learning for time-invariant Markov decision processes by introducing a notion of uncertainty in a learned time-varying model, and develop a control policy for time-varying Markov decision processes based on the exploitation and exploration trade-off. We demonstrate the proposed methods on four numerical examples: a patrolling task with a change in system dynamics, a two-state MDP with periodically changing outcomes of actions, a wind flow estimation task, and a multi-armed bandit problem with periodically changing probabilities of different rewards.</p>","PeriodicalId":314696,"journal":{"name":"Journal of machine learning research : JMLR","volume":" ","pages":"1-40"},"PeriodicalIF":0.0000,"publicationDate":"2021-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8739185/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of machine learning research : JMLR","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/2/1 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
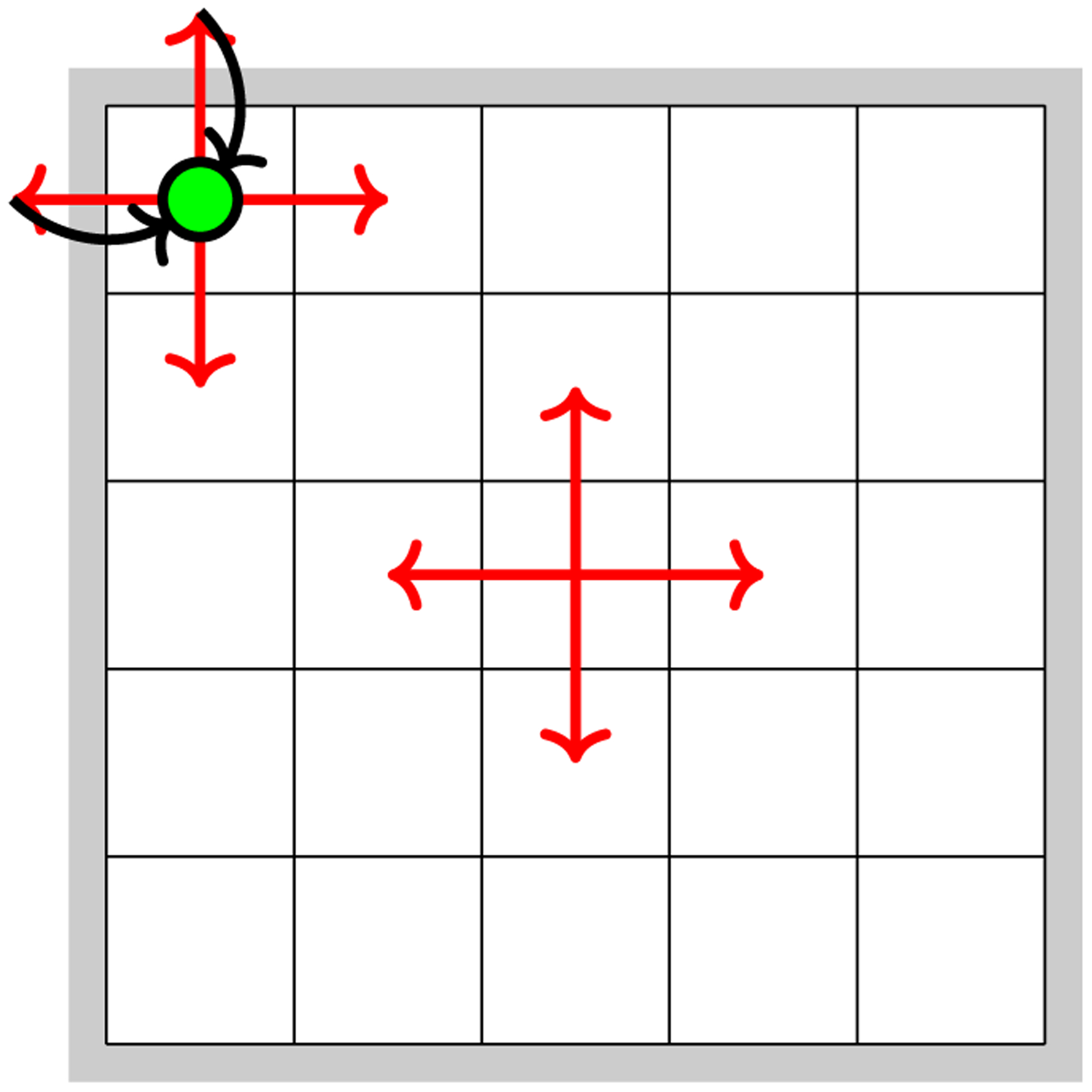
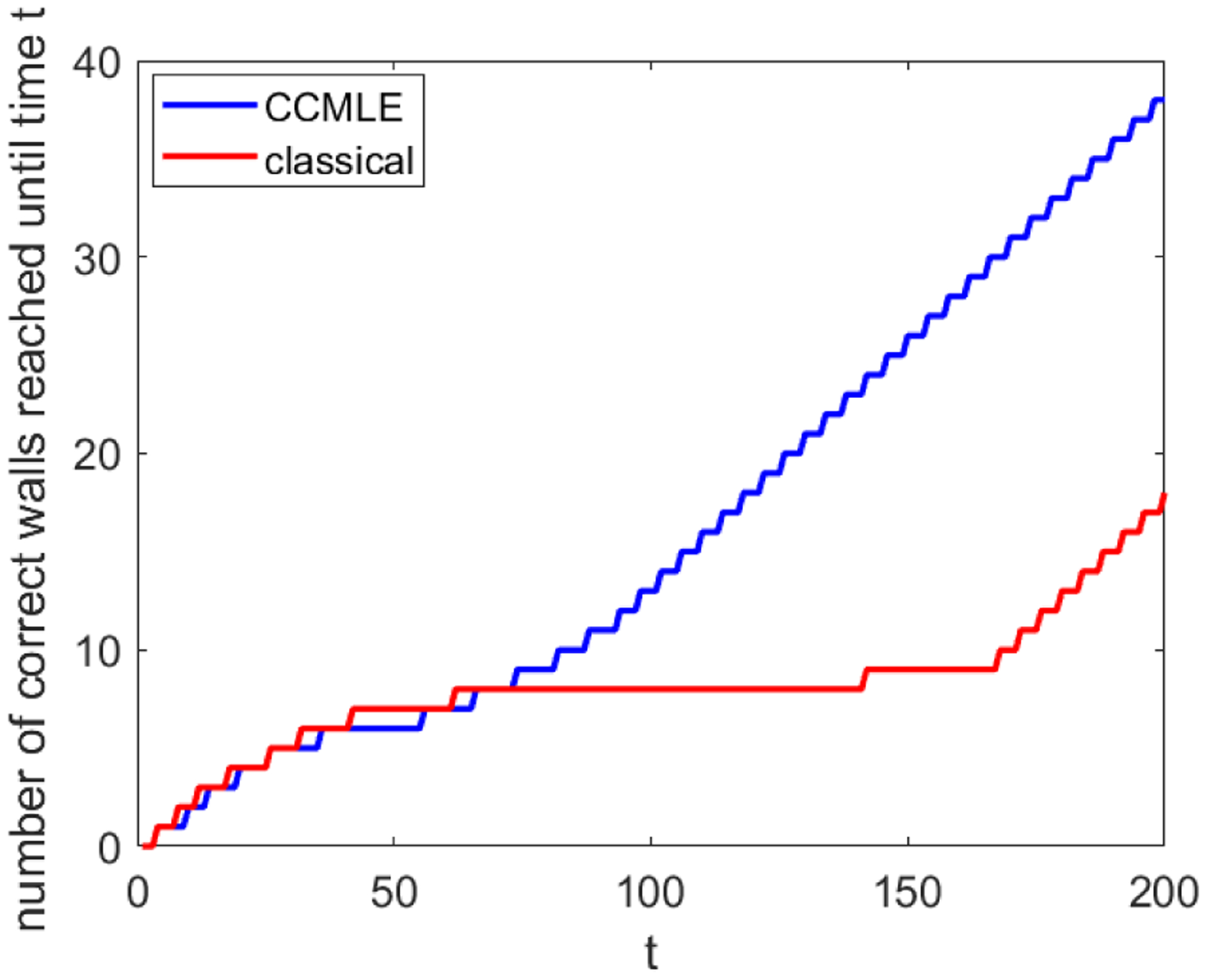
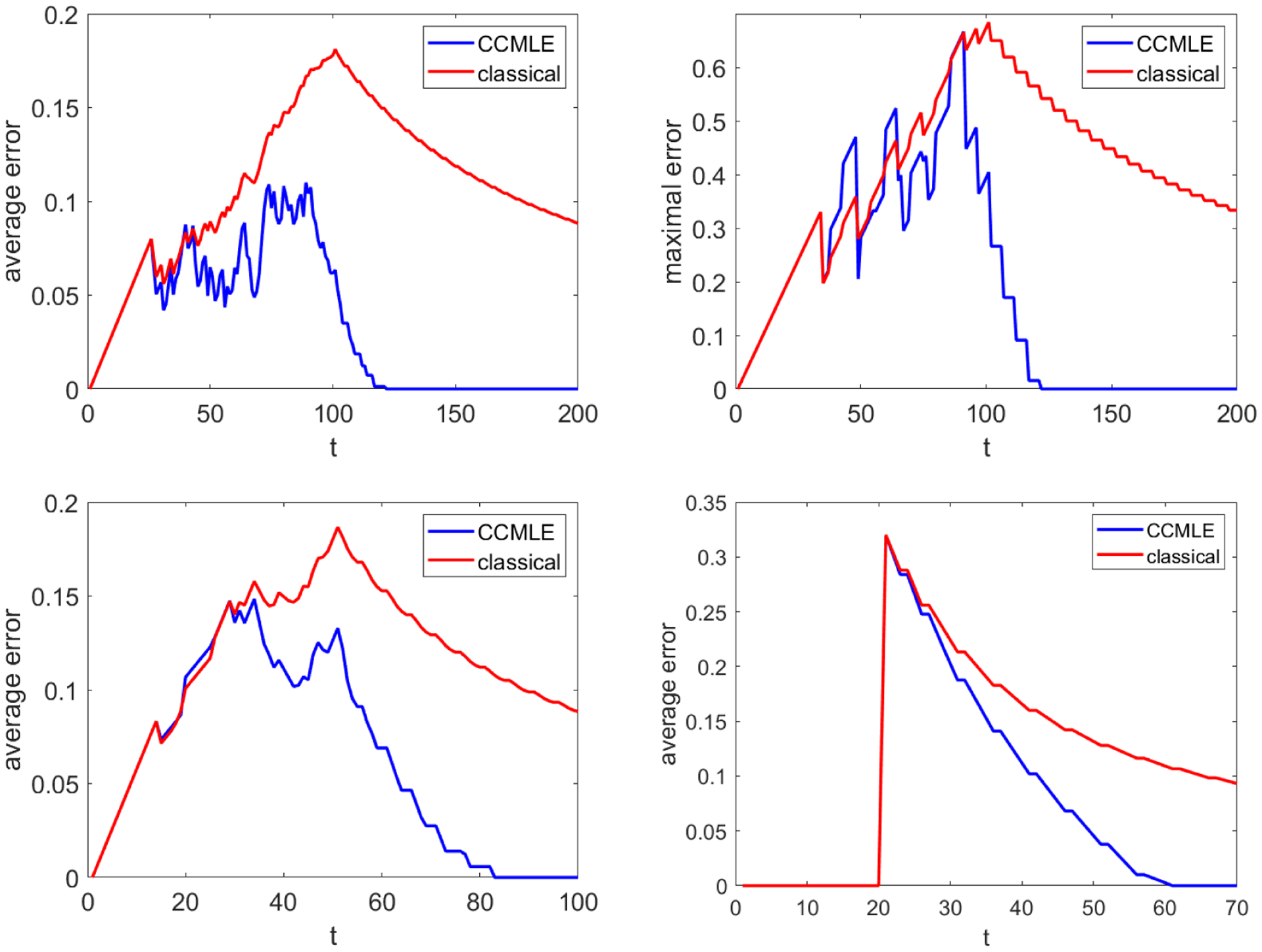
This paper proposes a formal approach to online learning and planning for agents operating in a priori unknown, time-varying environments. The proposed method computes the maximally likely model of the environment, given the observations about the environment made by an agent earlier in the system run and assuming knowledge of a bound on the maximal rate of change of system dynamics. Such an approach generalizes the estimation method commonly used in learning algorithms for unknown Markov decision processes with time-invariant transition probabilities, but is also able to quickly and correctly identify the system dynamics following a change. Based on the proposed method, we generalize the exploration bonuses used in learning for time-invariant Markov decision processes by introducing a notion of uncertainty in a learned time-varying model, and develop a control policy for time-varying Markov decision processes based on the exploitation and exploration trade-off. We demonstrate the proposed methods on four numerical examples: a patrolling task with a change in system dynamics, a two-state MDP with periodically changing outcomes of actions, a wind flow estimation task, and a multi-armed bandit problem with periodically changing probabilities of different rewards.
 分享
分享



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
