James A Michaelov, Megan D Bardolph, Cyma K Van Petten, Benjamin K Bergen, Seana Coulson
{"title":"Strong Prediction: Language Model Surprisal Explains Multiple N400 Effects.","authors":"James A Michaelov, Megan D Bardolph, Cyma K Van Petten, Benjamin K Bergen, Seana Coulson","doi":"10.1162/nol_a_00105","DOIUrl":null,"url":null,"abstract":"<p><p>Theoretical accounts of the N400 are divided as to whether the amplitude of the N400 response to a stimulus reflects the extent to which the stimulus was predicted, the extent to which the stimulus is semantically similar to its preceding context, or both. We use state-of-the-art machine learning tools to investigate which of these three accounts is best supported by the evidence. GPT-3, a neural language model trained to compute the conditional probability of any word based on the words that precede it, was used to operationalize contextual predictability. In particular, we used an information-theoretic construct known as surprisal (the negative logarithm of the conditional probability). Contextual semantic similarity was operationalized by using two high-quality co-occurrence-derived vector-based meaning representations for words: GloVe and fastText. The cosine between the vector representation of the sentence frame and final word was used to derive contextual cosine similarity estimates. A series of regression models were constructed, where these variables, along with cloze probability and plausibility ratings, were used to predict single trial N400 amplitudes recorded from healthy adults as they read sentences whose final word varied in its predictability, plausibility, and semantic relationship to the likeliest sentence completion. Statistical model comparison indicated GPT-3 surprisal provided the best account of N400 amplitude and suggested that apparently disparate N400 effects of expectancy, plausibility, and contextual semantic similarity can be reduced to variation in the predictability of words. The results are argued to support predictive coding in the human language network.</p>","PeriodicalId":3,"journal":{"name":"ACS Applied Electronic Materials","volume":" ","pages":"107-135"},"PeriodicalIF":4.7000,"publicationDate":"2024-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11025652/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Applied Electronic Materials","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1162/nol_a_00105","RegionNum":3,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
Abstract
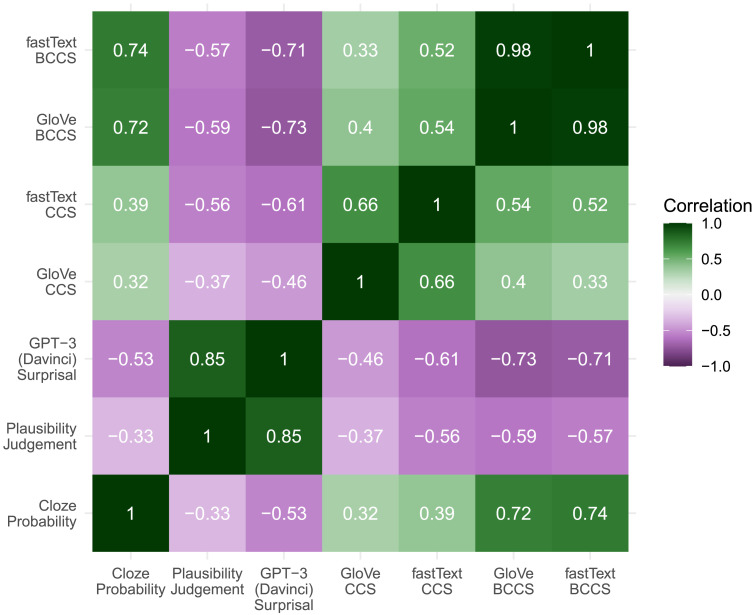
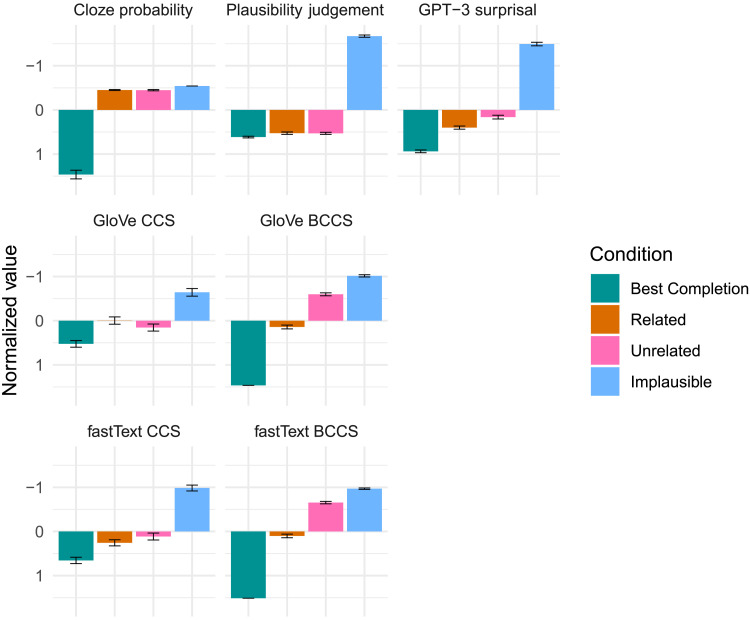
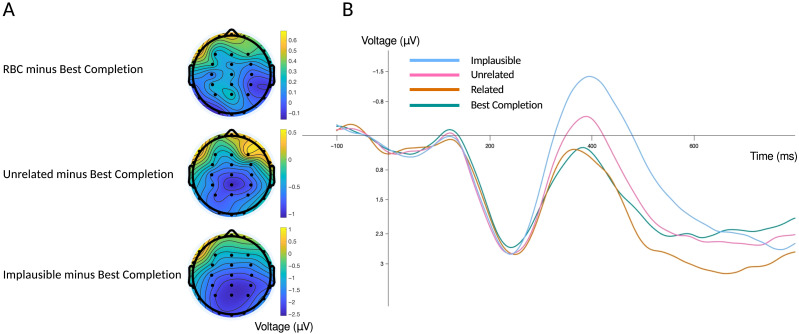
Theoretical accounts of the N400 are divided as to whether the amplitude of the N400 response to a stimulus reflects the extent to which the stimulus was predicted, the extent to which the stimulus is semantically similar to its preceding context, or both. We use state-of-the-art machine learning tools to investigate which of these three accounts is best supported by the evidence. GPT-3, a neural language model trained to compute the conditional probability of any word based on the words that precede it, was used to operationalize contextual predictability. In particular, we used an information-theoretic construct known as surprisal (the negative logarithm of the conditional probability). Contextual semantic similarity was operationalized by using two high-quality co-occurrence-derived vector-based meaning representations for words: GloVe and fastText. The cosine between the vector representation of the sentence frame and final word was used to derive contextual cosine similarity estimates. A series of regression models were constructed, where these variables, along with cloze probability and plausibility ratings, were used to predict single trial N400 amplitudes recorded from healthy adults as they read sentences whose final word varied in its predictability, plausibility, and semantic relationship to the likeliest sentence completion. Statistical model comparison indicated GPT-3 surprisal provided the best account of N400 amplitude and suggested that apparently disparate N400 effects of expectancy, plausibility, and contextual semantic similarity can be reduced to variation in the predictability of words. The results are argued to support predictive coding in the human language network.
期刊介绍:
ACS Applied Electronic Materials is an interdisciplinary journal publishing original research covering all aspects of electronic materials. The journal is devoted to reports of new and original experimental and theoretical research of an applied nature that integrate knowledge in the areas of materials science, engineering, optics, physics, and chemistry into important applications of electronic materials. Sample research topics that span the journal's scope are inorganic, organic, ionic and polymeric materials with properties that include conducting, semiconducting, superconducting, insulating, dielectric, magnetic, optoelectronic, piezoelectric, ferroelectric and thermoelectric.
Indexed/Abstracted:
Web of Science SCIE
Scopus
CAS
INSPEC
Portico



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
