{"title":"Nodes2STRNet for structural dense displacement recognition by deformable mesh model and motion representation","authors":"Jin Zhao, Hui Li, Yang Xu","doi":"10.1002/msd2.12083","DOIUrl":null,"url":null,"abstract":"<p>Displacement is a critical indicator for mechanical systems and civil structures. Conventional vision-based displacement recognition methods mainly focus on the sparse identification of limited measurement points, and the motion representation of an entire structure is very challenging. This study proposes a novel Nodes2STRNet for structural dense displacement recognition using a handful of structural control nodes based on a deformable structural three-dimensional mesh model, which consists of control node estimation subnetwork (NodesEstimate) and pose parameter recognition subnetwork (Nodes2PoseNet). NodesEstimate calculates the dense optical flow field based on FlowNet 2.0 and generates structural control node coordinates. Nodes2PoseNet uses structural control node coordinates as input and regresses structural pose parameters by a multilayer perceptron. A self-supervised learning strategy is designed with a mean square error loss and <i>L</i><sub>2</sub> regularization to train Nodes2PoseNet. The effectiveness and accuracy of dense displacement recognition and robustness to light condition variations are validated by seismic shaking table tests of a four-story-building model. Comparative studies with image-segmentation-based Structure-PoseNet show that the proposed Nodes2STRNet can achieve higher accuracy and better robustness against light condition variations. In addition, NodesEstimate does not require retraining when faced with new scenarios, and Nodes2PoseNet has high self-supervised training efficiency with only a few control nodes instead of fully supervised pixel-level segmentation.</p>","PeriodicalId":60486,"journal":{"name":"国际机械系统动力学学报(英文)","volume":"3 3","pages":"229-250"},"PeriodicalIF":3.6000,"publicationDate":"2023-09-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/msd2.12083","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"国际机械系统动力学学报(英文)","FirstCategoryId":"1087","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/msd2.12083","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, MECHANICAL","Score":null,"Total":0}
引用次数: 0
Abstract
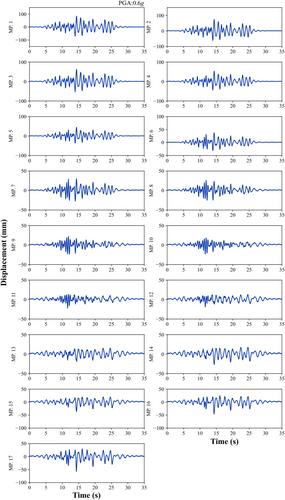
Displacement is a critical indicator for mechanical systems and civil structures. Conventional vision-based displacement recognition methods mainly focus on the sparse identification of limited measurement points, and the motion representation of an entire structure is very challenging. This study proposes a novel Nodes2STRNet for structural dense displacement recognition using a handful of structural control nodes based on a deformable structural three-dimensional mesh model, which consists of control node estimation subnetwork (NodesEstimate) and pose parameter recognition subnetwork (Nodes2PoseNet). NodesEstimate calculates the dense optical flow field based on FlowNet 2.0 and generates structural control node coordinates. Nodes2PoseNet uses structural control node coordinates as input and regresses structural pose parameters by a multilayer perceptron. A self-supervised learning strategy is designed with a mean square error loss and L2 regularization to train Nodes2PoseNet. The effectiveness and accuracy of dense displacement recognition and robustness to light condition variations are validated by seismic shaking table tests of a four-story-building model. Comparative studies with image-segmentation-based Structure-PoseNet show that the proposed Nodes2STRNet can achieve higher accuracy and better robustness against light condition variations. In addition, NodesEstimate does not require retraining when faced with new scenarios, and Nodes2PoseNet has high self-supervised training efficiency with only a few control nodes instead of fully supervised pixel-level segmentation.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
