下载PDF
{"title":"An information-theoretic approach to the prediction of protein structural class","authors":"Xiaoqi Zheng, Chun Li, Jun Wang","doi":"10.1002/jcc.21406","DOIUrl":null,"url":null,"abstract":"<p>An information-theoretical approach, which combines a sequence decomposition technique and a fuzzy clustering algorithm, is proposed for prediction of protein structural class. This approach could bypass the process of selecting and comparing sequence features as done previously. First, distances between each pair of protein sequences are estimated using a conditional decomposition technique in information theory. Then, the fuzzy <i>k</i>-nearest neighbor algorithm is used to identify the structural class of a protein given as set of sample sequences. To verify the strength of our method, we choose three widely used datasets constructed by Chou and Zhou. It is shown by the Jackknife test that our approach represents an improvement in the prediction of accuracy over existing methods. © 2009 Wiley Periodicals, Inc. J Comput Chem, 2010</p>","PeriodicalId":188,"journal":{"name":"Journal of Computational Chemistry","volume":"31 6","pages":"1201-1206"},"PeriodicalIF":4.8000,"publicationDate":"2009-09-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1002/jcc.21406","citationCount":"24","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Computational Chemistry","FirstCategoryId":"92","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/jcc.21406","RegionNum":3,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 24
引用
批量引用
Abstract
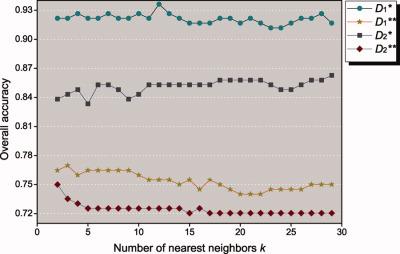
An information-theoretical approach, which combines a sequence decomposition technique and a fuzzy clustering algorithm, is proposed for prediction of protein structural class. This approach could bypass the process of selecting and comparing sequence features as done previously. First, distances between each pair of protein sequences are estimated using a conditional decomposition technique in information theory. Then, the fuzzy k -nearest neighbor algorithm is used to identify the structural class of a protein given as set of sample sequences. To verify the strength of our method, we choose three widely used datasets constructed by Chou and Zhou. It is shown by the Jackknife test that our approach represents an improvement in the prediction of accuracy over existing methods. © 2009 Wiley Periodicals, Inc. J Comput Chem, 2010
蛋白质结构类预测的信息论方法
提出了一种结合序列分解技术和模糊聚类算法的信息理论方法来预测蛋白质结构类。这种方法可以绕过之前选择和比较序列特征的过程。首先,利用信息论中的条件分解技术估计每对蛋白质序列之间的距离。然后,使用模糊k近邻算法对给定的一组样本序列的蛋白质进行结构类识别。为了验证我们方法的强度,我们选择了Chou和Zhou构建的三个广泛使用的数据集。刀切试验表明,与现有方法相比,我们的方法在预测精度方面有所提高。©2009 Wiley期刊公司计算机学报,2010
本文章由计算机程序翻译,如有差异,请以英文原文为准。


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
