Harisankar Sadasivan, Milos Maric, Eric Dawson, Vishanth Iyer, Johnny Israeli, Satish Narayanasamy
{"title":"Accelerating Minimap2 for Accurate Long Read Alignment on GPUs.","authors":"Harisankar Sadasivan, Milos Maric, Eric Dawson, Vishanth Iyer, Johnny Israeli, Satish Narayanasamy","doi":"10.26502/jbb.2642-91280067","DOIUrl":null,"url":null,"abstract":"<p><p>Long read sequencing technology is becoming increasingly popular for Precision Medicine applications like Whole Genome Sequencing (WGS) and microbial abundance estimation. Minimap2 is the state-of-the-art aligner and mapper used by the leading long read sequencing technologies, today. However, Minimap2 on CPUs is very slow for long noisy reads. ~60-70% of the run-time on a CPU comes from the highly sequential chaining step in Minimap2. On the other hand, most Point-of-Care computational workflows in long read sequencing use Graphics Processing Units (GPUs). We present minimap2-accelerated (mm2-ax), a heterogeneous design for sequence mapping and alignment where minimap2's compute intensive chaining step is sped up on the GPU and demonstrate its time and cost benefits. We extract better intra-read parallelism from chaining without losing mapping accuracy by forward transforming Minimap2's chaining algorithm. Moreover, we better utilize the high memory available on modern cloud instances apart from better workload balancing, data locality and minimal branch divergence on the GPU. We show mm2-ax on an NVIDIA A100 GPU improves the chaining step with 5.41 - 2.57X speedup and 4.07 - 1.93X speedup : costup over the fastest version of Minimap2, mm2-fast, benchmarked on a Google Cloud Platform instance of 30 SIMD cores.</p>","PeriodicalId":15066,"journal":{"name":"Journal of Biotechnology and Biomedicine","volume":"6 1","pages":"13-23"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10018915/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biotechnology and Biomedicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.26502/jbb.2642-91280067","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/20 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
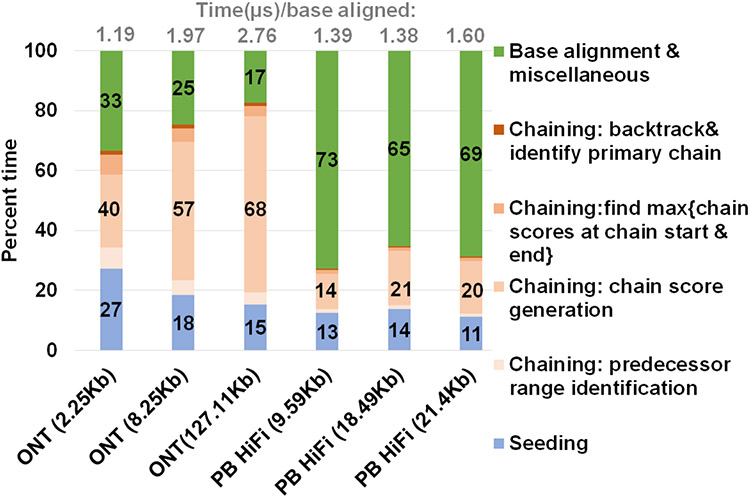
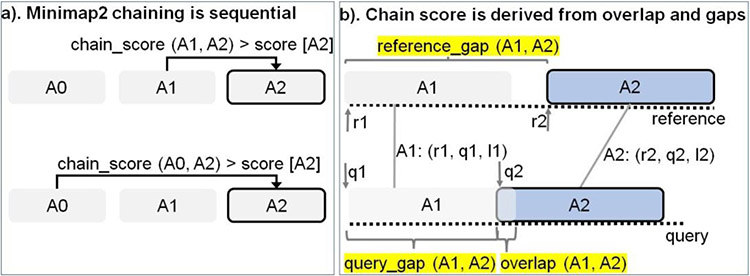
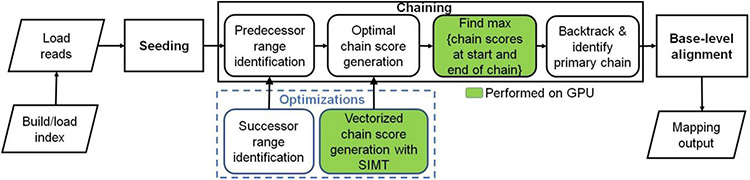
Long read sequencing technology is becoming increasingly popular for Precision Medicine applications like Whole Genome Sequencing (WGS) and microbial abundance estimation. Minimap2 is the state-of-the-art aligner and mapper used by the leading long read sequencing technologies, today. However, Minimap2 on CPUs is very slow for long noisy reads. ~60-70% of the run-time on a CPU comes from the highly sequential chaining step in Minimap2. On the other hand, most Point-of-Care computational workflows in long read sequencing use Graphics Processing Units (GPUs). We present minimap2-accelerated (mm2-ax), a heterogeneous design for sequence mapping and alignment where minimap2's compute intensive chaining step is sped up on the GPU and demonstrate its time and cost benefits. We extract better intra-read parallelism from chaining without losing mapping accuracy by forward transforming Minimap2's chaining algorithm. Moreover, we better utilize the high memory available on modern cloud instances apart from better workload balancing, data locality and minimal branch divergence on the GPU. We show mm2-ax on an NVIDIA A100 GPU improves the chaining step with 5.41 - 2.57X speedup and 4.07 - 1.93X speedup : costup over the fastest version of Minimap2, mm2-fast, benchmarked on a Google Cloud Platform instance of 30 SIMD cores.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
