Kevin Xie, Samuel W Terman, Ryan S Gallagher, Chloe E Hill, Kathryn A Davis, Brian Litt, Dan Roth, Colin A Ellis
{"title":"将经过微调的转换语言模型推广到新的临床环境中。","authors":"Kevin Xie, Samuel W Terman, Ryan S Gallagher, Chloe E Hill, Kathryn A Davis, Brian Litt, Dan Roth, Colin A Ellis","doi":"10.1093/jamiaopen/ooad070","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>We have previously developed a natural language processing pipeline using clinical notes written by epilepsy specialists to extract seizure freedom, seizure frequency text, and date of last seizure text for patients with epilepsy. It is important to understand how our methods generalize to new care contexts.</p><p><strong>Materials and methods: </strong>We evaluated our pipeline on unseen notes from nonepilepsy-specialist neurologists and non-neurologists without any additional algorithm training. We tested the pipeline out-of-institution using epilepsy specialist notes from an outside medical center with only minor preprocessing adaptations. We examined reasons for discrepancies in performance in new contexts by measuring physical and semantic similarities between documents.</p><p><strong>Results: </strong>Our ability to classify patient seizure freedom decreased by at least 0.12 agreement when moving from epilepsy specialists to nonspecialists or other institutions. On notes from our institution, textual overlap between the extracted outcomes and the gold standard annotations attained from manual chart review decreased by at least 0.11 F<sub>1</sub> when an answer existed but did not change when no answer existed; here our models generalized on notes from the outside institution, losing at most 0.02 agreement. We analyzed textual differences and found that syntactic and semantic differences in both clinically relevant sentences and surrounding contexts significantly influenced model performance.</p><p><strong>Discussion and conclusion: </strong>Model generalization performance decreased on notes from nonspecialists; out-of-institution generalization on epilepsy specialist notes required small changes to preprocessing but was especially good for seizure frequency text and date of last seizure text, opening opportunities for multicenter collaborations using these outcomes.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"6 3","pages":"ooad070"},"PeriodicalIF":3.4000,"publicationDate":"2023-08-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10432353/pdf/","citationCount":"0","resultStr":"{\"title\":\"Generalization of finetuned transformer language models to new clinical contexts.\",\"authors\":\"Kevin Xie, Samuel W Terman, Ryan S Gallagher, Chloe E Hill, Kathryn A Davis, Brian Litt, Dan Roth, Colin A Ellis\",\"doi\":\"10.1093/jamiaopen/ooad070\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>We have previously developed a natural language processing pipeline using clinical notes written by epilepsy specialists to extract seizure freedom, seizure frequency text, and date of last seizure text for patients with epilepsy. It is important to understand how our methods generalize to new care contexts.</p><p><strong>Materials and methods: </strong>We evaluated our pipeline on unseen notes from nonepilepsy-specialist neurologists and non-neurologists without any additional algorithm training. We tested the pipeline out-of-institution using epilepsy specialist notes from an outside medical center with only minor preprocessing adaptations. We examined reasons for discrepancies in performance in new contexts by measuring physical and semantic similarities between documents.</p><p><strong>Results: </strong>Our ability to classify patient seizure freedom decreased by at least 0.12 agreement when moving from epilepsy specialists to nonspecialists or other institutions. On notes from our institution, textual overlap between the extracted outcomes and the gold standard annotations attained from manual chart review decreased by at least 0.11 F<sub>1</sub> when an answer existed but did not change when no answer existed; here our models generalized on notes from the outside institution, losing at most 0.02 agreement. We analyzed textual differences and found that syntactic and semantic differences in both clinically relevant sentences and surrounding contexts significantly influenced model performance.</p><p><strong>Discussion and conclusion: </strong>Model generalization performance decreased on notes from nonspecialists; out-of-institution generalization on epilepsy specialist notes required small changes to preprocessing but was especially good for seizure frequency text and date of last seizure text, opening opportunities for multicenter collaborations using these outcomes.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"6 3\",\"pages\":\"ooad070\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2023-08-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10432353/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooad070\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/10/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooad070","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/10/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Generalization of finetuned transformer language models to new clinical contexts.
Objective: We have previously developed a natural language processing pipeline using clinical notes written by epilepsy specialists to extract seizure freedom, seizure frequency text, and date of last seizure text for patients with epilepsy. It is important to understand how our methods generalize to new care contexts.
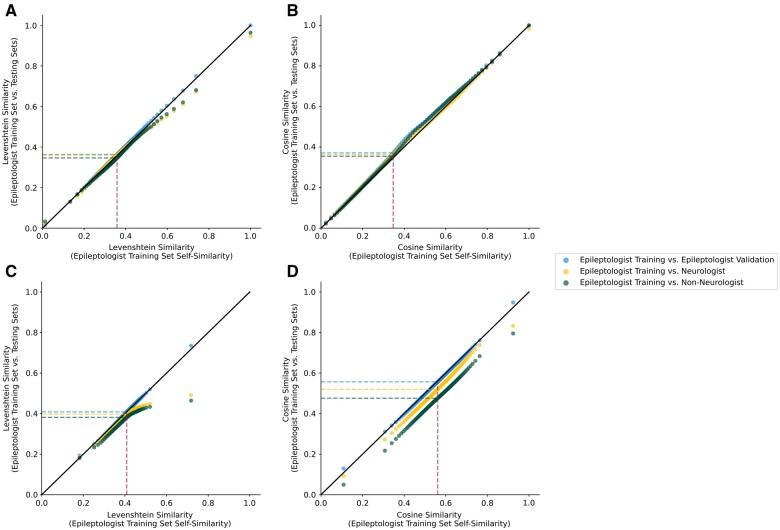
Materials and methods: We evaluated our pipeline on unseen notes from nonepilepsy-specialist neurologists and non-neurologists without any additional algorithm training. We tested the pipeline out-of-institution using epilepsy specialist notes from an outside medical center with only minor preprocessing adaptations. We examined reasons for discrepancies in performance in new contexts by measuring physical and semantic similarities between documents.
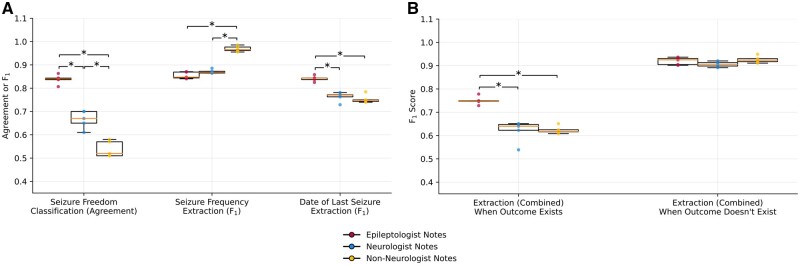
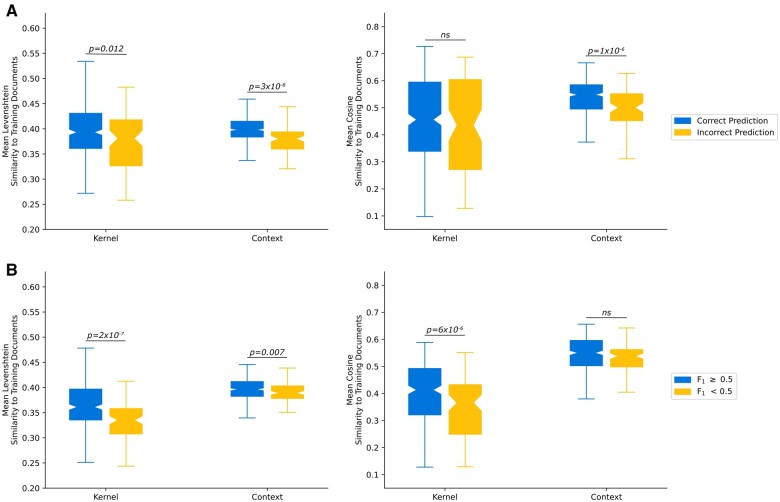
Results: Our ability to classify patient seizure freedom decreased by at least 0.12 agreement when moving from epilepsy specialists to nonspecialists or other institutions. On notes from our institution, textual overlap between the extracted outcomes and the gold standard annotations attained from manual chart review decreased by at least 0.11 F1 when an answer existed but did not change when no answer existed; here our models generalized on notes from the outside institution, losing at most 0.02 agreement. We analyzed textual differences and found that syntactic and semantic differences in both clinically relevant sentences and surrounding contexts significantly influenced model performance.
Discussion and conclusion: Model generalization performance decreased on notes from nonspecialists; out-of-institution generalization on epilepsy specialist notes required small changes to preprocessing but was especially good for seizure frequency text and date of last seizure text, opening opportunities for multicenter collaborations using these outcomes.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
