Hanming Zhai, Xiaojun Lv, Zhiwen Hou, Xin Tong, Fanliang Bu
{"title":"MLNet:一个多级多模态命名实体识别体系结构。","authors":"Hanming Zhai, Xiaojun Lv, Zhiwen Hou, Xin Tong, Fanliang Bu","doi":"10.3389/fnbot.2023.1181143","DOIUrl":null,"url":null,"abstract":"<p><p>In the field of human-computer interaction, accurate identification of talking objects can help robots to accomplish subsequent tasks such as decision-making or recommendation; therefore, object determination is of great interest as a pre-requisite task. Whether it is named entity recognition (NER) in natural language processing (NLP) work or object detection (OD) task in the computer vision (CV) field, the essence is to achieve object recognition. Currently, multimodal approaches are widely used in basic image recognition and natural language processing tasks. This multimodal architecture can perform entity recognition tasks more accurately, but when faced with short texts and images containing more noise, we find that there is still room for optimization in the image-text-based multimodal named entity recognition (MNER) architecture. In this study, we propose a new multi-level multimodal named entity recognition architecture, which is a network capable of extracting useful visual information for boosting semantic understanding and subsequently improving entity identification efficacy. Specifically, we first performed image and text encoding separately and then built a symmetric neural network architecture based on Transformer for multimodal feature fusion. We utilized a gating mechanism to filter visual information that is significantly related to the textual content, in order to enhance text understanding and achieve semantic disambiguation. Furthermore, we incorporated character-level vector encoding to reduce text noise. Finally, we employed Conditional Random Fields for label classification task. Experiments on the Twitter dataset show that our model works to increase the accuracy of the MNER task.</p>","PeriodicalId":12628,"journal":{"name":"Frontiers in Neurorobotics","volume":"17 ","pages":"1181143"},"PeriodicalIF":2.6000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10319056/pdf/","citationCount":"0","resultStr":"{\"title\":\"MLNet: a multi-level multimodal named entity recognition architecture.\",\"authors\":\"Hanming Zhai, Xiaojun Lv, Zhiwen Hou, Xin Tong, Fanliang Bu\",\"doi\":\"10.3389/fnbot.2023.1181143\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In the field of human-computer interaction, accurate identification of talking objects can help robots to accomplish subsequent tasks such as decision-making or recommendation; therefore, object determination is of great interest as a pre-requisite task. Whether it is named entity recognition (NER) in natural language processing (NLP) work or object detection (OD) task in the computer vision (CV) field, the essence is to achieve object recognition. Currently, multimodal approaches are widely used in basic image recognition and natural language processing tasks. This multimodal architecture can perform entity recognition tasks more accurately, but when faced with short texts and images containing more noise, we find that there is still room for optimization in the image-text-based multimodal named entity recognition (MNER) architecture. In this study, we propose a new multi-level multimodal named entity recognition architecture, which is a network capable of extracting useful visual information for boosting semantic understanding and subsequently improving entity identification efficacy. Specifically, we first performed image and text encoding separately and then built a symmetric neural network architecture based on Transformer for multimodal feature fusion. We utilized a gating mechanism to filter visual information that is significantly related to the textual content, in order to enhance text understanding and achieve semantic disambiguation. Furthermore, we incorporated character-level vector encoding to reduce text noise. Finally, we employed Conditional Random Fields for label classification task. Experiments on the Twitter dataset show that our model works to increase the accuracy of the MNER task.</p>\",\"PeriodicalId\":12628,\"journal\":{\"name\":\"Frontiers in Neurorobotics\",\"volume\":\"17 \",\"pages\":\"1181143\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10319056/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Neurorobotics\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.3389/fnbot.2023.1181143\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Neurorobotics","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.3389/fnbot.2023.1181143","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
MLNet: a multi-level multimodal named entity recognition architecture.
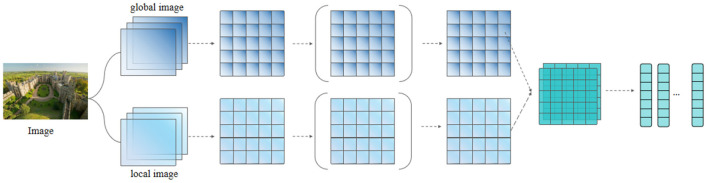
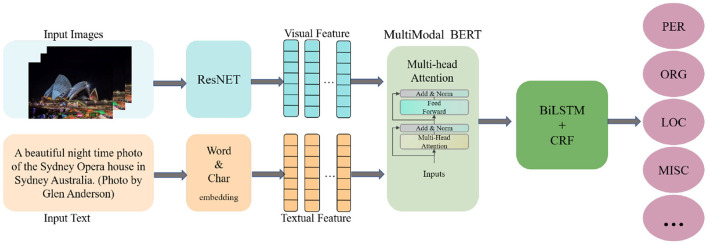
In the field of human-computer interaction, accurate identification of talking objects can help robots to accomplish subsequent tasks such as decision-making or recommendation; therefore, object determination is of great interest as a pre-requisite task. Whether it is named entity recognition (NER) in natural language processing (NLP) work or object detection (OD) task in the computer vision (CV) field, the essence is to achieve object recognition. Currently, multimodal approaches are widely used in basic image recognition and natural language processing tasks. This multimodal architecture can perform entity recognition tasks more accurately, but when faced with short texts and images containing more noise, we find that there is still room for optimization in the image-text-based multimodal named entity recognition (MNER) architecture. In this study, we propose a new multi-level multimodal named entity recognition architecture, which is a network capable of extracting useful visual information for boosting semantic understanding and subsequently improving entity identification efficacy. Specifically, we first performed image and text encoding separately and then built a symmetric neural network architecture based on Transformer for multimodal feature fusion. We utilized a gating mechanism to filter visual information that is significantly related to the textual content, in order to enhance text understanding and achieve semantic disambiguation. Furthermore, we incorporated character-level vector encoding to reduce text noise. Finally, we employed Conditional Random Fields for label classification task. Experiments on the Twitter dataset show that our model works to increase the accuracy of the MNER task.
期刊介绍:
Frontiers in Neurorobotics publishes rigorously peer-reviewed research in the science and technology of embodied autonomous neural systems. Specialty Chief Editors Alois C. Knoll and Florian Röhrbein at the Technische Universität München are supported by an outstanding Editorial Board of international experts. This multidisciplinary open-access journal is at the forefront of disseminating and communicating scientific knowledge and impactful discoveries to researchers, academics and the public worldwide.
Neural systems include brain-inspired algorithms (e.g. connectionist networks), computational models of biological neural networks (e.g. artificial spiking neural nets, large-scale simulations of neural microcircuits) and actual biological systems (e.g. in vivo and in vitro neural nets). The focus of the journal is the embodiment of such neural systems in artificial software and hardware devices, machines, robots or any other form of physical actuation. This also includes prosthetic devices, brain machine interfaces, wearable systems, micro-machines, furniture, home appliances, as well as systems for managing micro and macro infrastructures. Frontiers in Neurorobotics also aims to publish radically new tools and methods to study plasticity and development of autonomous self-learning systems that are capable of acquiring knowledge in an open-ended manner. Models complemented with experimental studies revealing self-organizing principles of embodied neural systems are welcome. Our journal also publishes on the micro and macro engineering and mechatronics of robotic devices driven by neural systems, as well as studies on the impact that such systems will have on our daily life.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
