{"title":"用监督话题模型探索考生对构建的回答项目的反应。","authors":"Seohyun Kim, Zhenqiu Lu, Allan S. Cohen","doi":"10.1111/bmsp.12319","DOIUrl":null,"url":null,"abstract":"<p>Textual data are increasingly common in test data as many assessments include constructed response (CR) items as indicators of participants' understanding. The development of techniques based on natural language processing has made it possible for researchers to rapidly analyse large sets of textual data. One family of statistical techniques for this purpose are probabilistic topic models. Topic modelling is a technique for detecting the latent topic structure in a collection of documents and has been widely used to analyse texts in a variety of areas. The detected topics can reveal primary themes in the documents, and the relative use of topics can be useful in investigating the variability of the documents. Supervised latent Dirichlet allocation (SLDA) is a popular topic model in that family that jointly models textual data and paired responses such as could occur with participants' textual answers to CR items and their rubric-based scores. SLDA has an assumption of a homogeneous relationship between textual data and paired responses across all documents. This approach, while useful for some purposes, may not be satisfied for situations in which a population has subgroups that have different relationships. In this study, we introduce a new supervised topic model that incorporates finite-mixture modelling into the SLDA. This new model can detect latent groups of participants that have different relationships between their textual responses and associated scores. The model is illustrated with an example from an analysis of a set of textual responses and paired scores from a middle grades assessment of science inquiry knowledge. A simulation study is presented to investigate the performance of the proposed model under practical testing conditions.</p>","PeriodicalId":55322,"journal":{"name":"British Journal of Mathematical & Statistical Psychology","volume":"77 1","pages":"130-150"},"PeriodicalIF":1.8000,"publicationDate":"2023-09-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bmsp.12319","citationCount":"0","resultStr":"{\"title\":\"Exploring examinees' responses to constructed response items with a supervised topic model\",\"authors\":\"Seohyun Kim, Zhenqiu Lu, Allan S. Cohen\",\"doi\":\"10.1111/bmsp.12319\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Textual data are increasingly common in test data as many assessments include constructed response (CR) items as indicators of participants' understanding. The development of techniques based on natural language processing has made it possible for researchers to rapidly analyse large sets of textual data. One family of statistical techniques for this purpose are probabilistic topic models. Topic modelling is a technique for detecting the latent topic structure in a collection of documents and has been widely used to analyse texts in a variety of areas. The detected topics can reveal primary themes in the documents, and the relative use of topics can be useful in investigating the variability of the documents. Supervised latent Dirichlet allocation (SLDA) is a popular topic model in that family that jointly models textual data and paired responses such as could occur with participants' textual answers to CR items and their rubric-based scores. SLDA has an assumption of a homogeneous relationship between textual data and paired responses across all documents. This approach, while useful for some purposes, may not be satisfied for situations in which a population has subgroups that have different relationships. In this study, we introduce a new supervised topic model that incorporates finite-mixture modelling into the SLDA. This new model can detect latent groups of participants that have different relationships between their textual responses and associated scores. The model is illustrated with an example from an analysis of a set of textual responses and paired scores from a middle grades assessment of science inquiry knowledge. A simulation study is presented to investigate the performance of the proposed model under practical testing conditions.</p>\",\"PeriodicalId\":55322,\"journal\":{\"name\":\"British Journal of Mathematical & Statistical Psychology\",\"volume\":\"77 1\",\"pages\":\"130-150\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-09-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bmsp.12319\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"British Journal of Mathematical & Statistical Psychology\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://bpspsychub.onlinelibrary.wiley.com/doi/10.1111/bmsp.12319\",\"RegionNum\":3,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"British Journal of Mathematical & Statistical Psychology","FirstCategoryId":"102","ListUrlMain":"https://bpspsychub.onlinelibrary.wiley.com/doi/10.1111/bmsp.12319","RegionNum":3,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Exploring examinees' responses to constructed response items with a supervised topic model
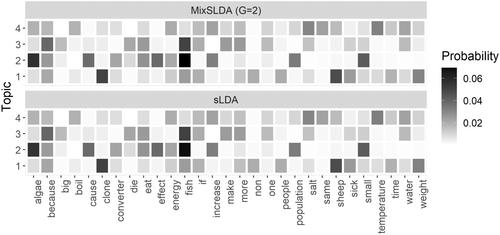
Textual data are increasingly common in test data as many assessments include constructed response (CR) items as indicators of participants' understanding. The development of techniques based on natural language processing has made it possible for researchers to rapidly analyse large sets of textual data. One family of statistical techniques for this purpose are probabilistic topic models. Topic modelling is a technique for detecting the latent topic structure in a collection of documents and has been widely used to analyse texts in a variety of areas. The detected topics can reveal primary themes in the documents, and the relative use of topics can be useful in investigating the variability of the documents. Supervised latent Dirichlet allocation (SLDA) is a popular topic model in that family that jointly models textual data and paired responses such as could occur with participants' textual answers to CR items and their rubric-based scores. SLDA has an assumption of a homogeneous relationship between textual data and paired responses across all documents. This approach, while useful for some purposes, may not be satisfied for situations in which a population has subgroups that have different relationships. In this study, we introduce a new supervised topic model that incorporates finite-mixture modelling into the SLDA. This new model can detect latent groups of participants that have different relationships between their textual responses and associated scores. The model is illustrated with an example from an analysis of a set of textual responses and paired scores from a middle grades assessment of science inquiry knowledge. A simulation study is presented to investigate the performance of the proposed model under practical testing conditions.
期刊介绍:
The British Journal of Mathematical and Statistical Psychology publishes articles relating to areas of psychology which have a greater mathematical or statistical aspect of their argument than is usually acceptable to other journals including:
• mathematical psychology
• statistics
• psychometrics
• decision making
• psychophysics
• classification
• relevant areas of mathematics, computing and computer software
These include articles that address substantitive psychological issues or that develop and extend techniques useful to psychologists. New models for psychological processes, new approaches to existing data, critiques of existing models and improved algorithms for estimating the parameters of a model are examples of articles which may be favoured.




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
