{"title":"基于特征重要性的UMAP可视化聚合物空间解释。","authors":"Takuya Ehiro","doi":"10.1002/minf.202300061","DOIUrl":null,"url":null,"abstract":"<p><p>Dimensionality reduction (DR) techniques are used for various purposes such as exploratory data analysis. A commonly employed linear DR technique is principal component analysis (PCA), which is one of the most popular methods for DR. Owing to its linear nature, PCA enables the determination of axes in a low-dimensional space and the calculation of corresponding loading vectors. However, PCA cannot necessarily extract important features of non-linearly distributed data. This study presents a technique aimed at aiding the interpretation of data reduced through non-linear DR methods. In the proposed method, non-linear dimensionally reduced data was clustered via a density-based clustering method. Thereafter, the obtained cluster labels were classified by random forest (RF) classifiers. Further, feature importance (FI) of RF classifiers and Spearman's rank correlation coefficients between predictive probabilities to obtained clusters and original feature values were utilized for characterizing the visualized dimensionally reduced data. The results revealed that the proposed method can provide the interpretable FI-based images of the handwritten digits dataset. Moreover, the proposed method was also applied to the polymer dataset. The study found that incorporating signed FI was advantageous in achieving a meaningful interpretation. Furthermore, Gaussian process regression was utilized to produce intuitive FI-based heatmaps on a 2-dimensional space for greater ease of understanding. Additionally, to enhance the interpretability of the obtained clusters, a feature selection technique called Boruta was applied. The Boruta feature selection method worked effectively to interpret the obtained clusters with limited and commonly important features. Additionally, the study suggested that computing FI solely from substructure-based descriptors could further enhance the interpretability of the results. Finally, the automation of the proposed method was investigated, and through maximizing the target score based on the quality of both the DR and clustering, indicative results were automatically obtained for both the handwritten digits and polymer datasets.</p>","PeriodicalId":18853,"journal":{"name":"Molecular Informatics","volume":"42 8-9","pages":"e2300061"},"PeriodicalIF":2.8000,"publicationDate":"2023-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Feature importance-based interpretation of UMAP-visualized polymer space.\",\"authors\":\"Takuya Ehiro\",\"doi\":\"10.1002/minf.202300061\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Dimensionality reduction (DR) techniques are used for various purposes such as exploratory data analysis. A commonly employed linear DR technique is principal component analysis (PCA), which is one of the most popular methods for DR. Owing to its linear nature, PCA enables the determination of axes in a low-dimensional space and the calculation of corresponding loading vectors. However, PCA cannot necessarily extract important features of non-linearly distributed data. This study presents a technique aimed at aiding the interpretation of data reduced through non-linear DR methods. In the proposed method, non-linear dimensionally reduced data was clustered via a density-based clustering method. Thereafter, the obtained cluster labels were classified by random forest (RF) classifiers. Further, feature importance (FI) of RF classifiers and Spearman's rank correlation coefficients between predictive probabilities to obtained clusters and original feature values were utilized for characterizing the visualized dimensionally reduced data. The results revealed that the proposed method can provide the interpretable FI-based images of the handwritten digits dataset. Moreover, the proposed method was also applied to the polymer dataset. The study found that incorporating signed FI was advantageous in achieving a meaningful interpretation. Furthermore, Gaussian process regression was utilized to produce intuitive FI-based heatmaps on a 2-dimensional space for greater ease of understanding. Additionally, to enhance the interpretability of the obtained clusters, a feature selection technique called Boruta was applied. The Boruta feature selection method worked effectively to interpret the obtained clusters with limited and commonly important features. Additionally, the study suggested that computing FI solely from substructure-based descriptors could further enhance the interpretability of the results. Finally, the automation of the proposed method was investigated, and through maximizing the target score based on the quality of both the DR and clustering, indicative results were automatically obtained for both the handwritten digits and polymer datasets.</p>\",\"PeriodicalId\":18853,\"journal\":{\"name\":\"Molecular Informatics\",\"volume\":\"42 8-9\",\"pages\":\"e2300061\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2023-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Molecular Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1002/minf.202300061\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/6/16 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"CHEMISTRY, MEDICINAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1002/minf.202300061","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/6/16 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
Feature importance-based interpretation of UMAP-visualized polymer space.
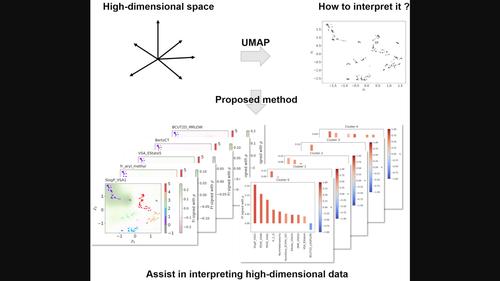
Dimensionality reduction (DR) techniques are used for various purposes such as exploratory data analysis. A commonly employed linear DR technique is principal component analysis (PCA), which is one of the most popular methods for DR. Owing to its linear nature, PCA enables the determination of axes in a low-dimensional space and the calculation of corresponding loading vectors. However, PCA cannot necessarily extract important features of non-linearly distributed data. This study presents a technique aimed at aiding the interpretation of data reduced through non-linear DR methods. In the proposed method, non-linear dimensionally reduced data was clustered via a density-based clustering method. Thereafter, the obtained cluster labels were classified by random forest (RF) classifiers. Further, feature importance (FI) of RF classifiers and Spearman's rank correlation coefficients between predictive probabilities to obtained clusters and original feature values were utilized for characterizing the visualized dimensionally reduced data. The results revealed that the proposed method can provide the interpretable FI-based images of the handwritten digits dataset. Moreover, the proposed method was also applied to the polymer dataset. The study found that incorporating signed FI was advantageous in achieving a meaningful interpretation. Furthermore, Gaussian process regression was utilized to produce intuitive FI-based heatmaps on a 2-dimensional space for greater ease of understanding. Additionally, to enhance the interpretability of the obtained clusters, a feature selection technique called Boruta was applied. The Boruta feature selection method worked effectively to interpret the obtained clusters with limited and commonly important features. Additionally, the study suggested that computing FI solely from substructure-based descriptors could further enhance the interpretability of the results. Finally, the automation of the proposed method was investigated, and through maximizing the target score based on the quality of both the DR and clustering, indicative results were automatically obtained for both the handwritten digits and polymer datasets.
期刊介绍:
Molecular Informatics is a peer-reviewed, international forum for publication of high-quality, interdisciplinary research on all molecular aspects of bio/cheminformatics and computer-assisted molecular design. Molecular Informatics succeeded QSAR & Combinatorial Science in 2010.
Molecular Informatics presents methodological innovations that will lead to a deeper understanding of ligand-receptor interactions, macromolecular complexes, molecular networks, design concepts and processes that demonstrate how ideas and design concepts lead to molecules with a desired structure or function, preferably including experimental validation.
The journal''s scope includes but is not limited to the fields of drug discovery and chemical biology, protein and nucleic acid engineering and design, the design of nanomolecular structures, strategies for modeling of macromolecular assemblies, molecular networks and systems, pharmaco- and chemogenomics, computer-assisted screening strategies, as well as novel technologies for the de novo design of biologically active molecules. As a unique feature Molecular Informatics publishes so-called "Methods Corner" review-type articles which feature important technological concepts and advances within the scope of the journal.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
