Justin T Reese, Daniel Danis, J Harry Caufield, Tudor Groza, Elena Casiraghi, Giorgio Valentini, Christopher J Mungall, Peter N Robinson
{"title":"大型语言模型在临床诊断中的局限性。","authors":"Justin T Reese, Daniel Danis, J Harry Caufield, Tudor Groza, Elena Casiraghi, Giorgio Valentini, Christopher J Mungall, Peter N Robinson","doi":"10.1101/2023.07.13.23292613","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Large Language Models such as GPT-4 previously have been applied to differential diagnostic challenges based on published case reports. Published case reports have a sophisticated narrative style that is not readily available from typical electronic health records (EHR). Furthermore, even if such a narrative were available in EHRs, privacy requirements would preclude sending it outside the hospital firewall. We therefore tested a method for parsing clinical texts to extract ontology terms and programmatically generating prompts that by design are free of protected health information.</p><p><strong>Materials and methods: </strong>We investigated different methods to prepare prompts from 75 recently published case reports. We transformed the original narratives by extracting structured terms representing phenotypic abnormalities, comorbidities, treatments, and laboratory tests and creating prompts programmatically.</p><p><strong>Results: </strong>Performance of all of these approaches was modest, with the correct diagnosis ranked first in only 5.3-17.6% of cases. The performance of the prompts created from structured data was substantially worse than that of the original narrative texts, even if additional information was added following manual review of term extraction. Moreover, different versions of GPT-4 demonstrated substantially different performance on this task.</p><p><strong>Discussion: </strong>The sensitivity of the performance to the form of the prompt and the instability of results over two GPT-4 versions represent important current limitations to the use of GPT-4 to support diagnosis in real-life clinical settings.</p><p><strong>Conclusion: </strong>Research is needed to identify the best methods for creating prompts from typically available clinical data to support differential diagnostics.</p>","PeriodicalId":18659,"journal":{"name":"medRxiv : the preprint server for health sciences","volume":" ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-02-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10370243/pdf/","citationCount":"0","resultStr":"{\"title\":\"On the limitations of large language models in clinical diagnosis.\",\"authors\":\"Justin T Reese, Daniel Danis, J Harry Caufield, Tudor Groza, Elena Casiraghi, Giorgio Valentini, Christopher J Mungall, Peter N Robinson\",\"doi\":\"10.1101/2023.07.13.23292613\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>Large Language Models such as GPT-4 previously have been applied to differential diagnostic challenges based on published case reports. Published case reports have a sophisticated narrative style that is not readily available from typical electronic health records (EHR). Furthermore, even if such a narrative were available in EHRs, privacy requirements would preclude sending it outside the hospital firewall. We therefore tested a method for parsing clinical texts to extract ontology terms and programmatically generating prompts that by design are free of protected health information.</p><p><strong>Materials and methods: </strong>We investigated different methods to prepare prompts from 75 recently published case reports. We transformed the original narratives by extracting structured terms representing phenotypic abnormalities, comorbidities, treatments, and laboratory tests and creating prompts programmatically.</p><p><strong>Results: </strong>Performance of all of these approaches was modest, with the correct diagnosis ranked first in only 5.3-17.6% of cases. The performance of the prompts created from structured data was substantially worse than that of the original narrative texts, even if additional information was added following manual review of term extraction. Moreover, different versions of GPT-4 demonstrated substantially different performance on this task.</p><p><strong>Discussion: </strong>The sensitivity of the performance to the form of the prompt and the instability of results over two GPT-4 versions represent important current limitations to the use of GPT-4 to support diagnosis in real-life clinical settings.</p><p><strong>Conclusion: </strong>Research is needed to identify the best methods for creating prompts from typically available clinical data to support differential diagnostics.</p>\",\"PeriodicalId\":18659,\"journal\":{\"name\":\"medRxiv : the preprint server for health sciences\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-02-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10370243/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"medRxiv : the preprint server for health sciences\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1101/2023.07.13.23292613\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"medRxiv : the preprint server for health sciences","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1101/2023.07.13.23292613","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
On the limitations of large language models in clinical diagnosis.
Objective: Large Language Models such as GPT-4 previously have been applied to differential diagnostic challenges based on published case reports. Published case reports have a sophisticated narrative style that is not readily available from typical electronic health records (EHR). Furthermore, even if such a narrative were available in EHRs, privacy requirements would preclude sending it outside the hospital firewall. We therefore tested a method for parsing clinical texts to extract ontology terms and programmatically generating prompts that by design are free of protected health information.
Materials and methods: We investigated different methods to prepare prompts from 75 recently published case reports. We transformed the original narratives by extracting structured terms representing phenotypic abnormalities, comorbidities, treatments, and laboratory tests and creating prompts programmatically.
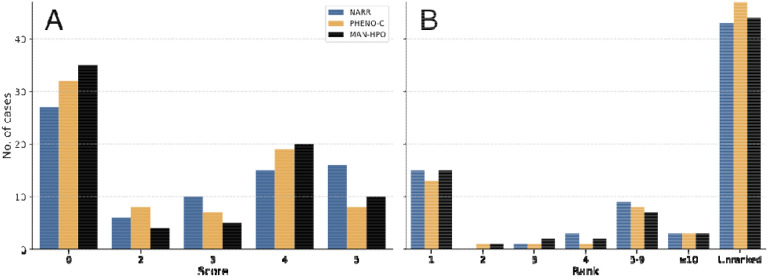
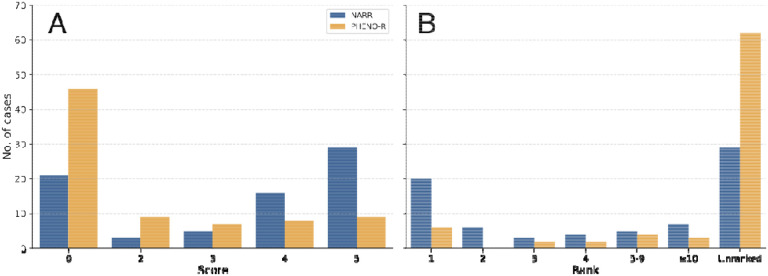
Results: Performance of all of these approaches was modest, with the correct diagnosis ranked first in only 5.3-17.6% of cases. The performance of the prompts created from structured data was substantially worse than that of the original narrative texts, even if additional information was added following manual review of term extraction. Moreover, different versions of GPT-4 demonstrated substantially different performance on this task.
Discussion: The sensitivity of the performance to the form of the prompt and the instability of results over two GPT-4 versions represent important current limitations to the use of GPT-4 to support diagnosis in real-life clinical settings.
Conclusion: Research is needed to identify the best methods for creating prompts from typically available clinical data to support differential diagnostics.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
