{"title":"护理记录文件编码切换自动语音识别:系统开发与评估。","authors":"Shih-Yen Hou, Ya-Lun Wu, Kai-Ching Chen, Ting-An Chang, Yi-Min Hsu, Su-Jung Chuang, Ying Chang, Kai-Cheng Hsu","doi":"10.2196/37562","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Taiwan has insufficient nursing resources due to the high turnover rate of health care providers. Therefore, reducing the heavy workload of these employees is essential. Herein, speech transcription, which has various potential clinical applications, was employed for the documentation of nursing records. The requirement of including only one speaker per transcription facilitated data collection and system development. Moreover, authorization from patients was unnecessary.</p><p><strong>Objective: </strong>The aim of this study was to construct a speech recognition system for nursing records such that health care providers can complete nursing records without typing or with only a few edits.</p><p><strong>Methods: </strong>Nursing records in Taiwan are mainly written in Mandarin, with technical terms and abbreviations presented in both Mandarin and English. Therefore, the training set consisted of English code-switching information. Next, transfer learning (TL) and meta-TL (MTL) methods, which perform favorably in code-switching scenarios, were applied.</p><p><strong>Results: </strong>As of September 2021, the China Medical University Hospital Artificial Intelligence Speech (CMaiSpeech) data set was established by manually annotating approximately 100 hours of recordings from 525 speakers. The word error rate (WER) of the benchmark model of syllable-based TL was 29.54% in code-switching. The WER of the proposed model of syllable-based MTL was 22.20% in code-switching. The test set comprised 17,247 words. Moreover, in a clinical case, the proposed model of syllable-based MTL yielded a WER of 31.06% in code-switching. The clinical test set contained 1159 words.</p><p><strong>Conclusions: </strong>This paper has two main contributions. First, the CMaiSpeech data set-a Mandarin-English corpus-has been established. Health care providers in Taiwan are often compelled to use a mixture of Mandarin and English in nursing records. Second, an automatic speech recognition system for nursing record document conversion was proposed. The proposed system can shorten the work handover time and further reduce the workload of health care providers.</p>","PeriodicalId":73556,"journal":{"name":"JMIR nursing","volume":"5 1","pages":"e37562"},"PeriodicalIF":4.0000,"publicationDate":"2022-12-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9773023/pdf/","citationCount":"0","resultStr":"{\"title\":\"Code-Switching Automatic Speech Recognition for Nursing Record Documentation: System Development and Evaluation.\",\"authors\":\"Shih-Yen Hou, Ya-Lun Wu, Kai-Ching Chen, Ting-An Chang, Yi-Min Hsu, Su-Jung Chuang, Ying Chang, Kai-Cheng Hsu\",\"doi\":\"10.2196/37562\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Taiwan has insufficient nursing resources due to the high turnover rate of health care providers. Therefore, reducing the heavy workload of these employees is essential. Herein, speech transcription, which has various potential clinical applications, was employed for the documentation of nursing records. The requirement of including only one speaker per transcription facilitated data collection and system development. Moreover, authorization from patients was unnecessary.</p><p><strong>Objective: </strong>The aim of this study was to construct a speech recognition system for nursing records such that health care providers can complete nursing records without typing or with only a few edits.</p><p><strong>Methods: </strong>Nursing records in Taiwan are mainly written in Mandarin, with technical terms and abbreviations presented in both Mandarin and English. Therefore, the training set consisted of English code-switching information. Next, transfer learning (TL) and meta-TL (MTL) methods, which perform favorably in code-switching scenarios, were applied.</p><p><strong>Results: </strong>As of September 2021, the China Medical University Hospital Artificial Intelligence Speech (CMaiSpeech) data set was established by manually annotating approximately 100 hours of recordings from 525 speakers. The word error rate (WER) of the benchmark model of syllable-based TL was 29.54% in code-switching. The WER of the proposed model of syllable-based MTL was 22.20% in code-switching. The test set comprised 17,247 words. Moreover, in a clinical case, the proposed model of syllable-based MTL yielded a WER of 31.06% in code-switching. The clinical test set contained 1159 words.</p><p><strong>Conclusions: </strong>This paper has two main contributions. First, the CMaiSpeech data set-a Mandarin-English corpus-has been established. Health care providers in Taiwan are often compelled to use a mixture of Mandarin and English in nursing records. Second, an automatic speech recognition system for nursing record document conversion was proposed. The proposed system can shorten the work handover time and further reduce the workload of health care providers.</p>\",\"PeriodicalId\":73556,\"journal\":{\"name\":\"JMIR nursing\",\"volume\":\"5 1\",\"pages\":\"e37562\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2022-12-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9773023/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR nursing\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/37562\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR nursing","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/37562","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Code-Switching Automatic Speech Recognition for Nursing Record Documentation: System Development and Evaluation.
Background: Taiwan has insufficient nursing resources due to the high turnover rate of health care providers. Therefore, reducing the heavy workload of these employees is essential. Herein, speech transcription, which has various potential clinical applications, was employed for the documentation of nursing records. The requirement of including only one speaker per transcription facilitated data collection and system development. Moreover, authorization from patients was unnecessary.
Objective: The aim of this study was to construct a speech recognition system for nursing records such that health care providers can complete nursing records without typing or with only a few edits.
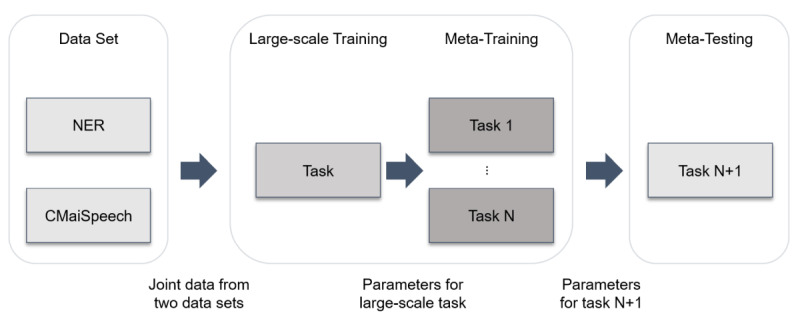
Methods: Nursing records in Taiwan are mainly written in Mandarin, with technical terms and abbreviations presented in both Mandarin and English. Therefore, the training set consisted of English code-switching information. Next, transfer learning (TL) and meta-TL (MTL) methods, which perform favorably in code-switching scenarios, were applied.
Results: As of September 2021, the China Medical University Hospital Artificial Intelligence Speech (CMaiSpeech) data set was established by manually annotating approximately 100 hours of recordings from 525 speakers. The word error rate (WER) of the benchmark model of syllable-based TL was 29.54% in code-switching. The WER of the proposed model of syllable-based MTL was 22.20% in code-switching. The test set comprised 17,247 words. Moreover, in a clinical case, the proposed model of syllable-based MTL yielded a WER of 31.06% in code-switching. The clinical test set contained 1159 words.
Conclusions: This paper has two main contributions. First, the CMaiSpeech data set-a Mandarin-English corpus-has been established. Health care providers in Taiwan are often compelled to use a mixture of Mandarin and English in nursing records. Second, an automatic speech recognition system for nursing record document conversion was proposed. The proposed system can shorten the work handover time and further reduce the workload of health care providers.




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
