Corinna Lorenz, Xinyu Hao, Tomas Tomka, Linus Rüttimann, Richard H R Hahnloser
{"title":"从平面嵌入中交互式提取不同的发声单元,无需事先进行声音分割。","authors":"Corinna Lorenz, Xinyu Hao, Tomas Tomka, Linus Rüttimann, Richard H R Hahnloser","doi":"10.3389/fbinf.2022.966066","DOIUrl":null,"url":null,"abstract":"<p><p>Annotating and proofreading data sets of complex natural behaviors such as vocalizations are tedious tasks because instances of a given behavior need to be correctly segmented from background noise and must be classified with minimal false positive error rate. Low-dimensional embeddings have proven very useful for this task because they can provide a visual overview of a data set in which distinct behaviors appear in different clusters. However, low-dimensional embeddings introduce errors because they fail to preserve distances; and embeddings represent only objects of fixed dimensionality, which conflicts with vocalizations that have variable dimensions stemming from their variable durations. To mitigate these issues, we introduce a semi-supervised, analytical method for simultaneous segmentation and clustering of vocalizations. We define a given vocalization type by specifying pairs of high-density regions in the embedding plane of sound spectrograms, one region associated with vocalization onsets and the other with offsets. We demonstrate our two-neighborhood (2N) extraction method on the task of clustering adult zebra finch vocalizations embedded with UMAP. We show that 2N extraction allows the identification of short and long vocal renditions from continuous data streams without initially committing to a particular segmentation of the data. Also, 2N extraction achieves much lower false positive error rate than comparable approaches based on a single defining region. Along with our method, we present a graphical user interface (GUI) for visualizing and annotating data.</p>","PeriodicalId":73066,"journal":{"name":"Frontiers in bioinformatics","volume":null,"pages":null},"PeriodicalIF":2.8000,"publicationDate":"2023-01-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9880044/pdf/","citationCount":"0","resultStr":"{\"title\":\"Interactive extraction of diverse vocal units from a planar embedding without the need for prior sound segmentation.\",\"authors\":\"Corinna Lorenz, Xinyu Hao, Tomas Tomka, Linus Rüttimann, Richard H R Hahnloser\",\"doi\":\"10.3389/fbinf.2022.966066\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Annotating and proofreading data sets of complex natural behaviors such as vocalizations are tedious tasks because instances of a given behavior need to be correctly segmented from background noise and must be classified with minimal false positive error rate. Low-dimensional embeddings have proven very useful for this task because they can provide a visual overview of a data set in which distinct behaviors appear in different clusters. However, low-dimensional embeddings introduce errors because they fail to preserve distances; and embeddings represent only objects of fixed dimensionality, which conflicts with vocalizations that have variable dimensions stemming from their variable durations. To mitigate these issues, we introduce a semi-supervised, analytical method for simultaneous segmentation and clustering of vocalizations. We define a given vocalization type by specifying pairs of high-density regions in the embedding plane of sound spectrograms, one region associated with vocalization onsets and the other with offsets. We demonstrate our two-neighborhood (2N) extraction method on the task of clustering adult zebra finch vocalizations embedded with UMAP. We show that 2N extraction allows the identification of short and long vocal renditions from continuous data streams without initially committing to a particular segmentation of the data. Also, 2N extraction achieves much lower false positive error rate than comparable approaches based on a single defining region. Along with our method, we present a graphical user interface (GUI) for visualizing and annotating data.</p>\",\"PeriodicalId\":73066,\"journal\":{\"name\":\"Frontiers in bioinformatics\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2023-01-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9880044/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in bioinformatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fbinf.2022.966066\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fbinf.2022.966066","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Interactive extraction of diverse vocal units from a planar embedding without the need for prior sound segmentation.
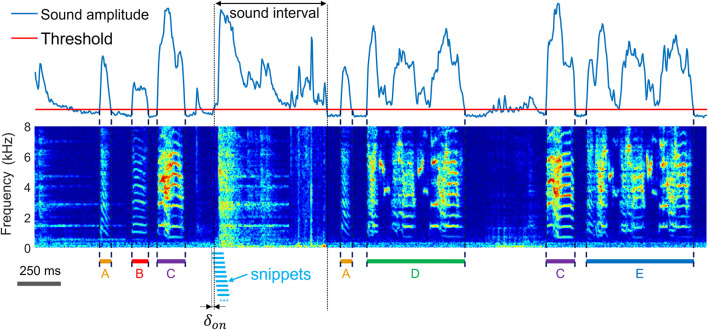
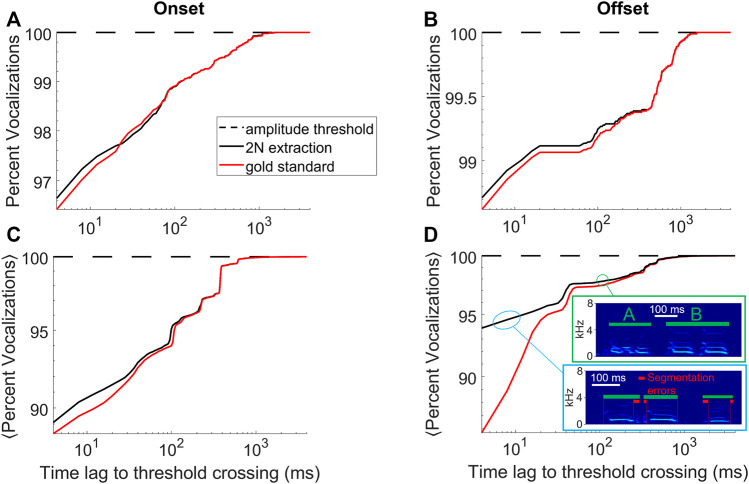
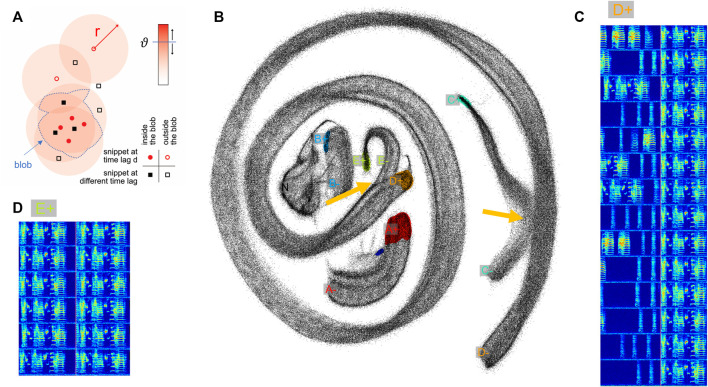
Annotating and proofreading data sets of complex natural behaviors such as vocalizations are tedious tasks because instances of a given behavior need to be correctly segmented from background noise and must be classified with minimal false positive error rate. Low-dimensional embeddings have proven very useful for this task because they can provide a visual overview of a data set in which distinct behaviors appear in different clusters. However, low-dimensional embeddings introduce errors because they fail to preserve distances; and embeddings represent only objects of fixed dimensionality, which conflicts with vocalizations that have variable dimensions stemming from their variable durations. To mitigate these issues, we introduce a semi-supervised, analytical method for simultaneous segmentation and clustering of vocalizations. We define a given vocalization type by specifying pairs of high-density regions in the embedding plane of sound spectrograms, one region associated with vocalization onsets and the other with offsets. We demonstrate our two-neighborhood (2N) extraction method on the task of clustering adult zebra finch vocalizations embedded with UMAP. We show that 2N extraction allows the identification of short and long vocal renditions from continuous data streams without initially committing to a particular segmentation of the data. Also, 2N extraction achieves much lower false positive error rate than comparable approaches based on a single defining region. Along with our method, we present a graphical user interface (GUI) for visualizing and annotating data.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
