Moritz Herrmann, Daniyal Kazempour, Fabian Scheipl, Peer Kröger
{"title":"通过拓扑流形学习增强聚类分析","authors":"Moritz Herrmann, Daniyal Kazempour, Fabian Scheipl, Peer Kröger","doi":"10.1007/s10618-023-00980-2","DOIUrl":null,"url":null,"abstract":"Abstract We discuss topological aspects of cluster analysis and show that inferring the topological structure of a dataset before clustering it can considerably enhance cluster detection: we show that clustering embedding vectors representing the inherent structure of a dataset instead of the observed feature vectors themselves is highly beneficial. To demonstrate, we combine manifold learning method UMAP for inferring the topological structure with density-based clustering method DBSCAN. Synthetic and real data results show that this both simplifies and improves clustering in a diverse set of low- and high-dimensional problems including clusters of varying density and/or entangled shapes. Our approach simplifies clustering because topological pre-processing consistently reduces parameter sensitivity of DBSCAN. Clustering the resulting embeddings with DBSCAN can then even outperform complex methods such as SPECTACL and ClusterGAN. Finally, our investigation suggests that the crucial issue in clustering does not appear to be the nominal dimension of the data or how many irrelevant features it contains, but rather how separable the clusters are in the ambient observation space they are embedded in, which is usually the (high-dimensional) Euclidean space defined by the features of the data. The approach is successful because it performs the cluster analysis after projecting the data into a more suitable space that is optimized for separability, in some sense.","PeriodicalId":55183,"journal":{"name":"Data Mining and Knowledge Discovery","volume":"96 1","pages":"0"},"PeriodicalIF":4.3000,"publicationDate":"2023-09-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhancing cluster analysis via topological manifold learning\",\"authors\":\"Moritz Herrmann, Daniyal Kazempour, Fabian Scheipl, Peer Kröger\",\"doi\":\"10.1007/s10618-023-00980-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Abstract We discuss topological aspects of cluster analysis and show that inferring the topological structure of a dataset before clustering it can considerably enhance cluster detection: we show that clustering embedding vectors representing the inherent structure of a dataset instead of the observed feature vectors themselves is highly beneficial. To demonstrate, we combine manifold learning method UMAP for inferring the topological structure with density-based clustering method DBSCAN. Synthetic and real data results show that this both simplifies and improves clustering in a diverse set of low- and high-dimensional problems including clusters of varying density and/or entangled shapes. Our approach simplifies clustering because topological pre-processing consistently reduces parameter sensitivity of DBSCAN. Clustering the resulting embeddings with DBSCAN can then even outperform complex methods such as SPECTACL and ClusterGAN. Finally, our investigation suggests that the crucial issue in clustering does not appear to be the nominal dimension of the data or how many irrelevant features it contains, but rather how separable the clusters are in the ambient observation space they are embedded in, which is usually the (high-dimensional) Euclidean space defined by the features of the data. The approach is successful because it performs the cluster analysis after projecting the data into a more suitable space that is optimized for separability, in some sense.\",\"PeriodicalId\":55183,\"journal\":{\"name\":\"Data Mining and Knowledge Discovery\",\"volume\":\"96 1\",\"pages\":\"0\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2023-09-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Data Mining and Knowledge Discovery\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s10618-023-00980-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data Mining and Knowledge Discovery","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10618-023-00980-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Enhancing cluster analysis via topological manifold learning
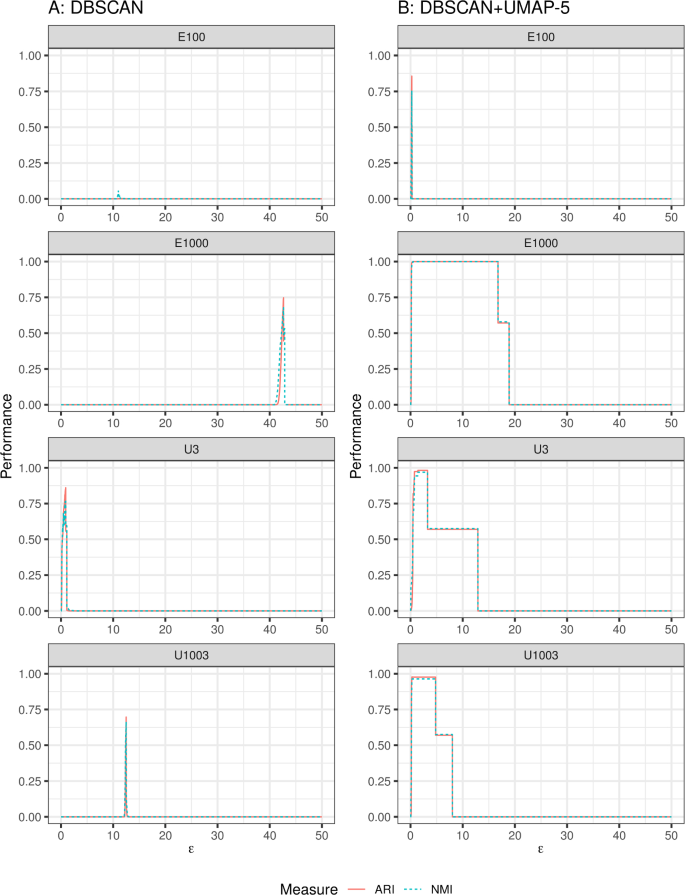
Abstract We discuss topological aspects of cluster analysis and show that inferring the topological structure of a dataset before clustering it can considerably enhance cluster detection: we show that clustering embedding vectors representing the inherent structure of a dataset instead of the observed feature vectors themselves is highly beneficial. To demonstrate, we combine manifold learning method UMAP for inferring the topological structure with density-based clustering method DBSCAN. Synthetic and real data results show that this both simplifies and improves clustering in a diverse set of low- and high-dimensional problems including clusters of varying density and/or entangled shapes. Our approach simplifies clustering because topological pre-processing consistently reduces parameter sensitivity of DBSCAN. Clustering the resulting embeddings with DBSCAN can then even outperform complex methods such as SPECTACL and ClusterGAN. Finally, our investigation suggests that the crucial issue in clustering does not appear to be the nominal dimension of the data or how many irrelevant features it contains, but rather how separable the clusters are in the ambient observation space they are embedded in, which is usually the (high-dimensional) Euclidean space defined by the features of the data. The approach is successful because it performs the cluster analysis after projecting the data into a more suitable space that is optimized for separability, in some sense.
期刊介绍:
Advances in data gathering, storage, and distribution have created a need for computational tools and techniques to aid in data analysis. Data Mining and Knowledge Discovery in Databases (KDD) is a rapidly growing area of research and application that builds on techniques and theories from many fields, including statistics, databases, pattern recognition and learning, data visualization, uncertainty modelling, data warehousing and OLAP, optimization, and high performance computing.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
