{"title":"评定量表中参数法的可靠性:模拟研究","authors":"Harald Kindermann","doi":"10.1002/appl.202300054","DOIUrl":null,"url":null,"abstract":"<p>A recurring question is whether rating scales should be considered metrically scaled or merely ordinally scaled. This has direct implications for the permissible statistical procedures for significance testing. Based on the results of a simulation study, it is shown that the use of parametric procedures for rating scales has distinct advantages over the nonparametric alternatives. It is also shown that the parametric procedures are robust to violations of the assumption of normality, which only result in a modest loss of power compared with continuous variables. This loss should be taken into account when calculating the optimal sample size. The results suggest that sample sizes about 25% larger should be chosen for discrete rating scales than for continuous variables.</p>","PeriodicalId":100109,"journal":{"name":"Applied Research","volume":"3 3","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-09-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/appl.202300054","citationCount":"0","resultStr":"{\"title\":\"The reliability of parametric methods in the case of rating scales: A simulation study\",\"authors\":\"Harald Kindermann\",\"doi\":\"10.1002/appl.202300054\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>A recurring question is whether rating scales should be considered metrically scaled or merely ordinally scaled. This has direct implications for the permissible statistical procedures for significance testing. Based on the results of a simulation study, it is shown that the use of parametric procedures for rating scales has distinct advantages over the nonparametric alternatives. It is also shown that the parametric procedures are robust to violations of the assumption of normality, which only result in a modest loss of power compared with continuous variables. This loss should be taken into account when calculating the optimal sample size. The results suggest that sample sizes about 25% larger should be chosen for discrete rating scales than for continuous variables.</p>\",\"PeriodicalId\":100109,\"journal\":{\"name\":\"Applied Research\",\"volume\":\"3 3\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-09-21\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/appl.202300054\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applied Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/appl.202300054\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied Research","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/appl.202300054","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
The reliability of parametric methods in the case of rating scales: A simulation study
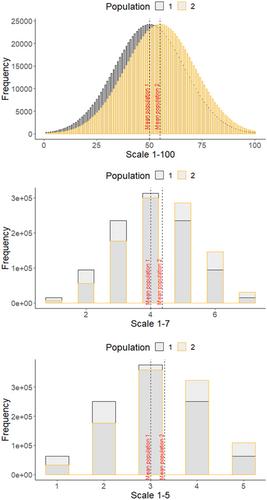
A recurring question is whether rating scales should be considered metrically scaled or merely ordinally scaled. This has direct implications for the permissible statistical procedures for significance testing. Based on the results of a simulation study, it is shown that the use of parametric procedures for rating scales has distinct advantages over the nonparametric alternatives. It is also shown that the parametric procedures are robust to violations of the assumption of normality, which only result in a modest loss of power compared with continuous variables. This loss should be taken into account when calculating the optimal sample size. The results suggest that sample sizes about 25% larger should be chosen for discrete rating scales than for continuous variables.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
