Carl Preiksaitis MD, Christopher Nash MD, EdM, Michael Gottlieb MD, Teresa M. Chan MD, MHPE, Al'ai Alvarez MD, Adaira Landry MD
{"title":"大脑与机器人:区分由人类和人工智能撰写的推荐信","authors":"Carl Preiksaitis MD, Christopher Nash MD, EdM, Michael Gottlieb MD, Teresa M. Chan MD, MHPE, Al'ai Alvarez MD, Adaira Landry MD","doi":"10.1002/aet2.10924","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Objectives</h3>\n \n <p>Letters of recommendation (LORs) are essential within academic medicine, affecting a number of important decisions regarding advancement, yet these letters take significant amounts of time and labor to prepare. The use of generative artificial intelligence (AI) tools, such as ChatGPT, are gaining popularity for a variety of academic writing tasks and offer an innovative solution to relieve the burden of letter writing. It is yet to be determined if ChatGPT could aid in crafting LORs, particularly in high-stakes contexts like faculty promotion. To determine the feasibility of this process and whether there is a significant difference between AI and human-authored letters, we conducted a study aimed at determining whether academic physicians can distinguish between the two.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>A quasi-experimental study was conducted using a single-blind design. Academic physicians with experience in reviewing LORs were presented with LORs for promotion to associate professor, written by either humans or AI. Participants reviewed LORs and identified the authorship. Statistical analysis was performed to determine accuracy in distinguishing between human and AI-authored LORs. Additionally, the perceived quality and persuasiveness of the LORs were compared based on suspected and actual authorship.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>A total of 32 participants completed letter review. The mean accuracy of distinguishing between human- versus AI-authored LORs was 59.4%. The reviewer's certainty and time spent deliberating did not significantly impact accuracy. LORs suspected to be human-authored were rated more favorably in terms of quality and persuasiveness. A difference in gender-biased language was observed in our letters: human-authored letters contained significantly more female-associated words, while the majority of AI-authored letters tended to use more male-associated words.</p>\n </section>\n \n <section>\n \n <h3> Conclusions</h3>\n \n <p>Participants were unable to reliably differentiate between human- and AI-authored LORs for promotion. AI may be able to generate LORs and relieve the burden of letter writing for academicians. New strategies, policies, and guidelines are needed to balance the benefits of AI while preserving integrity and fairness in academic promotion decisions.</p>\n </section>\n </div>","PeriodicalId":37032,"journal":{"name":"AEM Education and Training","volume":"7 6","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2023-11-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aet2.10924","citationCount":"0","resultStr":"{\"title\":\"Brain versus bot: Distinguishing letters of recommendation authored by humans compared with artificial intelligence\",\"authors\":\"Carl Preiksaitis MD, Christopher Nash MD, EdM, Michael Gottlieb MD, Teresa M. Chan MD, MHPE, Al'ai Alvarez MD, Adaira Landry MD\",\"doi\":\"10.1002/aet2.10924\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Objectives</h3>\\n \\n <p>Letters of recommendation (LORs) are essential within academic medicine, affecting a number of important decisions regarding advancement, yet these letters take significant amounts of time and labor to prepare. The use of generative artificial intelligence (AI) tools, such as ChatGPT, are gaining popularity for a variety of academic writing tasks and offer an innovative solution to relieve the burden of letter writing. It is yet to be determined if ChatGPT could aid in crafting LORs, particularly in high-stakes contexts like faculty promotion. To determine the feasibility of this process and whether there is a significant difference between AI and human-authored letters, we conducted a study aimed at determining whether academic physicians can distinguish between the two.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>A quasi-experimental study was conducted using a single-blind design. Academic physicians with experience in reviewing LORs were presented with LORs for promotion to associate professor, written by either humans or AI. Participants reviewed LORs and identified the authorship. Statistical analysis was performed to determine accuracy in distinguishing between human and AI-authored LORs. Additionally, the perceived quality and persuasiveness of the LORs were compared based on suspected and actual authorship.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>A total of 32 participants completed letter review. The mean accuracy of distinguishing between human- versus AI-authored LORs was 59.4%. The reviewer's certainty and time spent deliberating did not significantly impact accuracy. LORs suspected to be human-authored were rated more favorably in terms of quality and persuasiveness. A difference in gender-biased language was observed in our letters: human-authored letters contained significantly more female-associated words, while the majority of AI-authored letters tended to use more male-associated words.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Conclusions</h3>\\n \\n <p>Participants were unable to reliably differentiate between human- and AI-authored LORs for promotion. AI may be able to generate LORs and relieve the burden of letter writing for academicians. New strategies, policies, and guidelines are needed to balance the benefits of AI while preserving integrity and fairness in academic promotion decisions.</p>\\n </section>\\n </div>\",\"PeriodicalId\":37032,\"journal\":{\"name\":\"AEM Education and Training\",\"volume\":\"7 6\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-11-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/aet2.10924\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"AEM Education and Training\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/aet2.10924\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"EDUCATION, SCIENTIFIC DISCIPLINES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"AEM Education and Training","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/aet2.10924","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
Brain versus bot: Distinguishing letters of recommendation authored by humans compared with artificial intelligence
Objectives
Letters of recommendation (LORs) are essential within academic medicine, affecting a number of important decisions regarding advancement, yet these letters take significant amounts of time and labor to prepare. The use of generative artificial intelligence (AI) tools, such as ChatGPT, are gaining popularity for a variety of academic writing tasks and offer an innovative solution to relieve the burden of letter writing. It is yet to be determined if ChatGPT could aid in crafting LORs, particularly in high-stakes contexts like faculty promotion. To determine the feasibility of this process and whether there is a significant difference between AI and human-authored letters, we conducted a study aimed at determining whether academic physicians can distinguish between the two.
Methods
A quasi-experimental study was conducted using a single-blind design. Academic physicians with experience in reviewing LORs were presented with LORs for promotion to associate professor, written by either humans or AI. Participants reviewed LORs and identified the authorship. Statistical analysis was performed to determine accuracy in distinguishing between human and AI-authored LORs. Additionally, the perceived quality and persuasiveness of the LORs were compared based on suspected and actual authorship.
Results
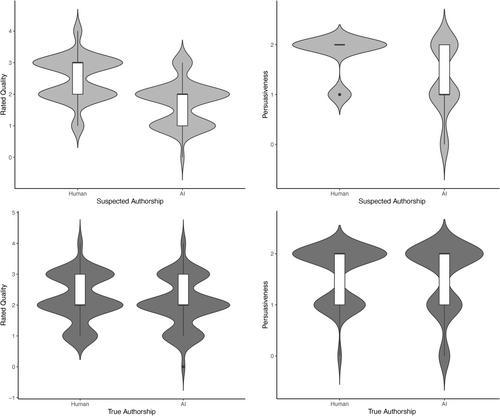
A total of 32 participants completed letter review. The mean accuracy of distinguishing between human- versus AI-authored LORs was 59.4%. The reviewer's certainty and time spent deliberating did not significantly impact accuracy. LORs suspected to be human-authored were rated more favorably in terms of quality and persuasiveness. A difference in gender-biased language was observed in our letters: human-authored letters contained significantly more female-associated words, while the majority of AI-authored letters tended to use more male-associated words.
Conclusions
Participants were unable to reliably differentiate between human- and AI-authored LORs for promotion. AI may be able to generate LORs and relieve the burden of letter writing for academicians. New strategies, policies, and guidelines are needed to balance the benefits of AI while preserving integrity and fairness in academic promotion decisions.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
