{"title":"学习总结和回答关于虚拟机器人过去行为的问题","authors":"Chad DeChant, Iretiayo Akinola, Daniel Bauer","doi":"10.1007/s10514-023-10134-4","DOIUrl":null,"url":null,"abstract":"<div><p>When robots perform long action sequences, users will want to easily and reliably find out what they have done. We therefore demonstrate the task of learning to summarize and answer questions about a robot agent’s past actions using natural language alone. A single system with a large language model at its core is trained to both summarize and answer questions about action sequences given ego-centric video frames of a virtual robot and a question prompt. To enable training of question answering, we develop a method to automatically generate English-language questions and answers about objects, actions, and the temporal order in which actions occurred during episodes of robot action in the virtual environment. Training one model to both summarize and answer questions enables zero-shot transfer of representations of objects learned through question answering to improved action summarization. \n</p></div>","PeriodicalId":55409,"journal":{"name":"Autonomous Robots","volume":"47 8","pages":"1103 - 1118"},"PeriodicalIF":4.3000,"publicationDate":"2023-11-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s10514-023-10134-4.pdf","citationCount":"0","resultStr":"{\"title\":\"Learning to summarize and answer questions about a virtual robot’s past actions\",\"authors\":\"Chad DeChant, Iretiayo Akinola, Daniel Bauer\",\"doi\":\"10.1007/s10514-023-10134-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>When robots perform long action sequences, users will want to easily and reliably find out what they have done. We therefore demonstrate the task of learning to summarize and answer questions about a robot agent’s past actions using natural language alone. A single system with a large language model at its core is trained to both summarize and answer questions about action sequences given ego-centric video frames of a virtual robot and a question prompt. To enable training of question answering, we develop a method to automatically generate English-language questions and answers about objects, actions, and the temporal order in which actions occurred during episodes of robot action in the virtual environment. Training one model to both summarize and answer questions enables zero-shot transfer of representations of objects learned through question answering to improved action summarization. \\n</p></div>\",\"PeriodicalId\":55409,\"journal\":{\"name\":\"Autonomous Robots\",\"volume\":\"47 8\",\"pages\":\"1103 - 1118\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2023-11-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s10514-023-10134-4.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Autonomous Robots\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10514-023-10134-4\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Autonomous Robots","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10514-023-10134-4","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Learning to summarize and answer questions about a virtual robot’s past actions
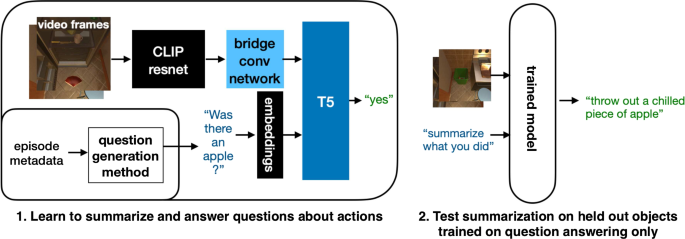
When robots perform long action sequences, users will want to easily and reliably find out what they have done. We therefore demonstrate the task of learning to summarize and answer questions about a robot agent’s past actions using natural language alone. A single system with a large language model at its core is trained to both summarize and answer questions about action sequences given ego-centric video frames of a virtual robot and a question prompt. To enable training of question answering, we develop a method to automatically generate English-language questions and answers about objects, actions, and the temporal order in which actions occurred during episodes of robot action in the virtual environment. Training one model to both summarize and answer questions enables zero-shot transfer of representations of objects learned through question answering to improved action summarization.
期刊介绍:
Autonomous Robots reports on the theory and applications of robotic systems capable of some degree of self-sufficiency. It features papers that include performance data on actual robots in the real world. Coverage includes: control of autonomous robots · real-time vision · autonomous wheeled and tracked vehicles · legged vehicles · computational architectures for autonomous systems · distributed architectures for learning, control and adaptation · studies of autonomous robot systems · sensor fusion · theory of autonomous systems · terrain mapping and recognition · self-calibration and self-repair for robots · self-reproducing intelligent structures · genetic algorithms as models for robot development.
The focus is on the ability to move and be self-sufficient, not on whether the system is an imitation of biology. Of course, biological models for robotic systems are of major interest to the journal since living systems are prototypes for autonomous behavior.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
