Ruipeng Tang, Narendra Kumar Aridas, Mohamad Sofian Abu Talip
{"title":"基于改进型 Spark 组件的农田环境监测数据处理方法设计。","authors":"Ruipeng Tang, Narendra Kumar Aridas, Mohamad Sofian Abu Talip","doi":"10.3389/fdata.2023.1282352","DOIUrl":null,"url":null,"abstract":"<p><p>With the popularization of big data technology, agricultural data processing systems have become more intelligent. In this study, a data processing method for farmland environmental monitoring based on improved Spark components is designed. It introduces the FAST-Join (Join critical filtering sampling partition optimization) algorithm in the Spark component for equivalence association query optimization to improve the operating efficiency of the Spark component and cluster. The experimental results show that the amount of data written and read in Shuffle by Spark optimized by the FAST-join algorithm only accounts for 0.958 and 1.384% of the original data volume on average, and the calculation speed is 202.11% faster than the original. The average data processing time and occupied memory size of the Spark cluster are reduced by 128.22 and 76.75% compared with the originals. It also compared the cluster performance of the FAST-join and Equi-join algorithms. The Spark cluster optimized by the FAST-join algorithm reduced the processing time and occupied memory size by an average of 68.74 and 37.80% compared with the Equi-join algorithm, which shows that the FAST-join algorithm can effectively improve the efficiency of inter-data table querying and cluster computing.</p>","PeriodicalId":52859,"journal":{"name":"Frontiers in Big Data","volume":"6 ","pages":"1282352"},"PeriodicalIF":2.4000,"publicationDate":"2023-11-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10694358/pdf/","citationCount":"0","resultStr":"{\"title\":\"Design of a data processing method for the farmland environmental monitoring based on improved Spark components.\",\"authors\":\"Ruipeng Tang, Narendra Kumar Aridas, Mohamad Sofian Abu Talip\",\"doi\":\"10.3389/fdata.2023.1282352\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>With the popularization of big data technology, agricultural data processing systems have become more intelligent. In this study, a data processing method for farmland environmental monitoring based on improved Spark components is designed. It introduces the FAST-Join (Join critical filtering sampling partition optimization) algorithm in the Spark component for equivalence association query optimization to improve the operating efficiency of the Spark component and cluster. The experimental results show that the amount of data written and read in Shuffle by Spark optimized by the FAST-join algorithm only accounts for 0.958 and 1.384% of the original data volume on average, and the calculation speed is 202.11% faster than the original. The average data processing time and occupied memory size of the Spark cluster are reduced by 128.22 and 76.75% compared with the originals. It also compared the cluster performance of the FAST-join and Equi-join algorithms. The Spark cluster optimized by the FAST-join algorithm reduced the processing time and occupied memory size by an average of 68.74 and 37.80% compared with the Equi-join algorithm, which shows that the FAST-join algorithm can effectively improve the efficiency of inter-data table querying and cluster computing.</p>\",\"PeriodicalId\":52859,\"journal\":{\"name\":\"Frontiers in Big Data\",\"volume\":\"6 \",\"pages\":\"1282352\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2023-11-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10694358/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Big Data\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fdata.2023.1282352\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Big Data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdata.2023.1282352","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Design of a data processing method for the farmland environmental monitoring based on improved Spark components.
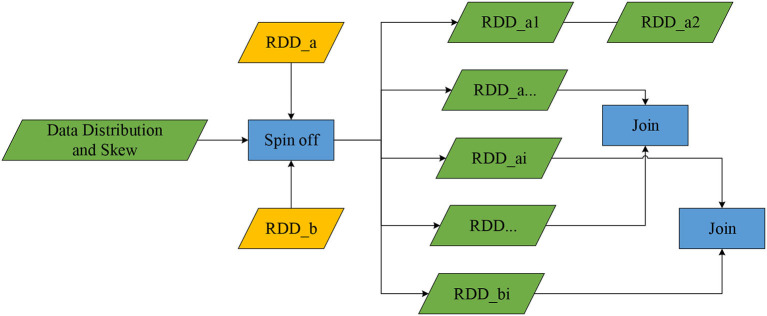
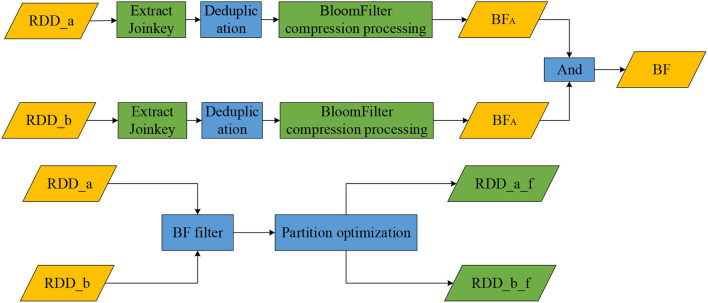
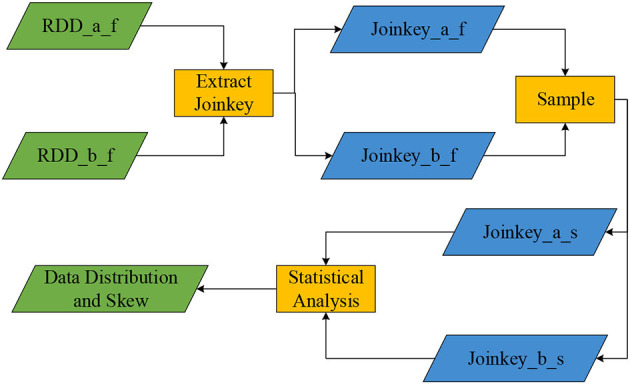
With the popularization of big data technology, agricultural data processing systems have become more intelligent. In this study, a data processing method for farmland environmental monitoring based on improved Spark components is designed. It introduces the FAST-Join (Join critical filtering sampling partition optimization) algorithm in the Spark component for equivalence association query optimization to improve the operating efficiency of the Spark component and cluster. The experimental results show that the amount of data written and read in Shuffle by Spark optimized by the FAST-join algorithm only accounts for 0.958 and 1.384% of the original data volume on average, and the calculation speed is 202.11% faster than the original. The average data processing time and occupied memory size of the Spark cluster are reduced by 128.22 and 76.75% compared with the originals. It also compared the cluster performance of the FAST-join and Equi-join algorithms. The Spark cluster optimized by the FAST-join algorithm reduced the processing time and occupied memory size by an average of 68.74 and 37.80% compared with the Equi-join algorithm, which shows that the FAST-join algorithm can effectively improve the efficiency of inter-data table querying and cluster computing.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
