{"title":"多任务gpu中的集群感知调度","authors":"Xia Zhao, Huiquan Wang, Anwen Huang, Dongsheng Wang, Guangda Zhang","doi":"10.1007/s11241-023-09409-x","DOIUrl":null,"url":null,"abstract":"<p>The streaming multiprocessor (SM) count in GPUs continues to increase to provide high computing power. To construct a scalable crossbar network that connects the SMs to the LLC slices and memory controllers, a cluster structure is exploited in GPUs where a group of SMs shares a network port. Unfortunately, current GPU spatial multitasking is unaware of this underlying network-on-chip infrastructure which poses the challenges and also the opportunities for the performance. In this paper, we observe that compared to the cluster-unaware multitasking, considering the cluster structure, the SM partition within a cluster and also the injecting policy of sharing the network port can bring significant performance improvement. Next, we propose a low-cost online profiling and scheduling policy that consists of two steps. The cluster-aware scheduling first determines the best SM partition within a cluster and then finds the proper injecting policy between the two co-executing applications. Both steps are achieved in online profiling which only incurs limited runtime overhead. The evaluation results show that for all workloads, our cluster-aware multitasking increases the system throughput by 12.9% on average (and up to 76.5%).\n</p>","PeriodicalId":54507,"journal":{"name":"Real-Time Systems","volume":"205 1","pages":""},"PeriodicalIF":1.3000,"publicationDate":"2023-11-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Cluster-aware scheduling in multitasking GPUs\",\"authors\":\"Xia Zhao, Huiquan Wang, Anwen Huang, Dongsheng Wang, Guangda Zhang\",\"doi\":\"10.1007/s11241-023-09409-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The streaming multiprocessor (SM) count in GPUs continues to increase to provide high computing power. To construct a scalable crossbar network that connects the SMs to the LLC slices and memory controllers, a cluster structure is exploited in GPUs where a group of SMs shares a network port. Unfortunately, current GPU spatial multitasking is unaware of this underlying network-on-chip infrastructure which poses the challenges and also the opportunities for the performance. In this paper, we observe that compared to the cluster-unaware multitasking, considering the cluster structure, the SM partition within a cluster and also the injecting policy of sharing the network port can bring significant performance improvement. Next, we propose a low-cost online profiling and scheduling policy that consists of two steps. The cluster-aware scheduling first determines the best SM partition within a cluster and then finds the proper injecting policy between the two co-executing applications. Both steps are achieved in online profiling which only incurs limited runtime overhead. The evaluation results show that for all workloads, our cluster-aware multitasking increases the system throughput by 12.9% on average (and up to 76.5%).\\n</p>\",\"PeriodicalId\":54507,\"journal\":{\"name\":\"Real-Time Systems\",\"volume\":\"205 1\",\"pages\":\"\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2023-11-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Real-Time Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11241-023-09409-x\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Real-Time Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11241-023-09409-x","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
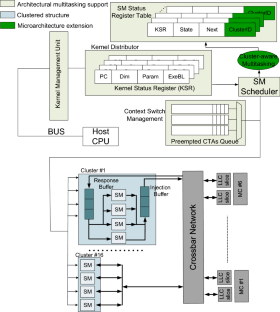
The streaming multiprocessor (SM) count in GPUs continues to increase to provide high computing power. To construct a scalable crossbar network that connects the SMs to the LLC slices and memory controllers, a cluster structure is exploited in GPUs where a group of SMs shares a network port. Unfortunately, current GPU spatial multitasking is unaware of this underlying network-on-chip infrastructure which poses the challenges and also the opportunities for the performance. In this paper, we observe that compared to the cluster-unaware multitasking, considering the cluster structure, the SM partition within a cluster and also the injecting policy of sharing the network port can bring significant performance improvement. Next, we propose a low-cost online profiling and scheduling policy that consists of two steps. The cluster-aware scheduling first determines the best SM partition within a cluster and then finds the proper injecting policy between the two co-executing applications. Both steps are achieved in online profiling which only incurs limited runtime overhead. The evaluation results show that for all workloads, our cluster-aware multitasking increases the system throughput by 12.9% on average (and up to 76.5%).
期刊介绍:
Papers published in Real-Time Systems cover, among others, the following topics: requirements engineering, specification and verification techniques, design methods and tools, programming languages, operating systems, scheduling algorithms, architecture, hardware and interfacing, dependability and safety, distributed and other novel architectures, wired and wireless communications, wireless sensor systems, distributed databases, artificial intelligence techniques, expert systems, and application case studies. Applications are found in command and control systems, process control, automated manufacturing, flight control, avionics, space avionics and defense systems, shipborne systems, vision and robotics, pervasive and ubiquitous computing, and in an abundance of embedded systems.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
