{"title":"基于确定性梯度的避鞍点方法","authors":"L. M. Kreusser, S. J. Osher, B. Wang","doi":"10.1017/s0956792522000316","DOIUrl":null,"url":null,"abstract":"<p>Loss functions with a large number of saddle points are one of the major obstacles for training modern machine learning (ML) models efficiently. First-order methods such as gradient descent (GD) are usually the methods of choice for training ML models. However, these methods converge to saddle points for certain choices of initial guesses. In this paper, we propose a modification of the recently proposed Laplacian smoothing gradient descent (LSGD) [Osher et al., arXiv:1806.06317], called modified LSGD (mLSGD), and demonstrate its potential to avoid saddle points without sacrificing the convergence rate. Our analysis is based on the attraction region, formed by all starting points for which the considered numerical scheme converges to a saddle point. We investigate the attraction region’s dimension both analytically and numerically. For a canonical class of quadratic functions, we show that the dimension of the attraction region for mLSGD is <span>\n<span>\n<img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20230705121909977-0335:S0956792522000316:S0956792522000316_inline1.png\"/>\n<span data-mathjax-type=\"texmath\"><span>\n$\\lfloor (n-1)/2\\rfloor$\n</span></span>\n</span>\n</span>, and hence it is significantly smaller than that of GD whose dimension is <span>\n<span>\n<img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20230705121909977-0335:S0956792522000316:S0956792522000316_inline2.png\"/>\n<span data-mathjax-type=\"texmath\"><span>\n$n-1$\n</span></span>\n</span>\n</span>.</p>","PeriodicalId":51046,"journal":{"name":"European Journal of Applied Mathematics","volume":"22 1","pages":""},"PeriodicalIF":1.1000,"publicationDate":"2022-11-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A deterministic gradient-based approach to avoid saddle points\",\"authors\":\"L. M. Kreusser, S. J. Osher, B. Wang\",\"doi\":\"10.1017/s0956792522000316\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Loss functions with a large number of saddle points are one of the major obstacles for training modern machine learning (ML) models efficiently. First-order methods such as gradient descent (GD) are usually the methods of choice for training ML models. However, these methods converge to saddle points for certain choices of initial guesses. In this paper, we propose a modification of the recently proposed Laplacian smoothing gradient descent (LSGD) [Osher et al., arXiv:1806.06317], called modified LSGD (mLSGD), and demonstrate its potential to avoid saddle points without sacrificing the convergence rate. Our analysis is based on the attraction region, formed by all starting points for which the considered numerical scheme converges to a saddle point. We investigate the attraction region’s dimension both analytically and numerically. For a canonical class of quadratic functions, we show that the dimension of the attraction region for mLSGD is <span>\\n<span>\\n<img data-mimesubtype=\\\"png\\\" data-type=\\\"\\\" src=\\\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20230705121909977-0335:S0956792522000316:S0956792522000316_inline1.png\\\"/>\\n<span data-mathjax-type=\\\"texmath\\\"><span>\\n$\\\\lfloor (n-1)/2\\\\rfloor$\\n</span></span>\\n</span>\\n</span>, and hence it is significantly smaller than that of GD whose dimension is <span>\\n<span>\\n<img data-mimesubtype=\\\"png\\\" data-type=\\\"\\\" src=\\\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20230705121909977-0335:S0956792522000316:S0956792522000316_inline2.png\\\"/>\\n<span data-mathjax-type=\\\"texmath\\\"><span>\\n$n-1$\\n</span></span>\\n</span>\\n</span>.</p>\",\"PeriodicalId\":51046,\"journal\":{\"name\":\"European Journal of Applied Mathematics\",\"volume\":\"22 1\",\"pages\":\"\"},\"PeriodicalIF\":1.1000,\"publicationDate\":\"2022-11-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"European Journal of Applied Mathematics\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://doi.org/10.1017/s0956792522000316\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICS, APPLIED\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Journal of Applied Mathematics","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1017/s0956792522000316","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICS, APPLIED","Score":null,"Total":0}
引用次数: 0
摘要
具有大量鞍点的损失函数是有效训练现代机器学习(ML)模型的主要障碍之一。梯度下降(GD)等一阶方法通常是训练ML模型的首选方法。然而,对于初始猜测的某些选择,这些方法收敛到鞍点。在本文中,我们对最近提出的拉普拉斯平滑梯度下降(LSGD) [Osher et al., arXiv:1806.06317]提出了一种修正,称为修正LSGD (mLSGD),并证明了其在不牺牲收敛速度的情况下避免鞍点的潜力。我们的分析是基于引力区域的,引力区域由所考虑的数值方案收敛于鞍点的所有起点组成。我们用解析法和数值法研究了引力区域的维数。对于一类典型的二次函数,我们证明了mLSGD的吸引域的维数为$\lfloor (n-1)/2\rfloor$,因此它明显小于维数为$n-1$的GD的吸引域。
A deterministic gradient-based approach to avoid saddle points
Loss functions with a large number of saddle points are one of the major obstacles for training modern machine learning (ML) models efficiently. First-order methods such as gradient descent (GD) are usually the methods of choice for training ML models. However, these methods converge to saddle points for certain choices of initial guesses. In this paper, we propose a modification of the recently proposed Laplacian smoothing gradient descent (LSGD) [Osher et al., arXiv:1806.06317], called modified LSGD (mLSGD), and demonstrate its potential to avoid saddle points without sacrificing the convergence rate. Our analysis is based on the attraction region, formed by all starting points for which the considered numerical scheme converges to a saddle point. We investigate the attraction region’s dimension both analytically and numerically. For a canonical class of quadratic functions, we show that the dimension of the attraction region for mLSGD is
$\lfloor (n-1)/2\rfloor$
, and hence it is significantly smaller than that of GD whose dimension is
$n-1$
.
期刊介绍:
Since 2008 EJAM surveys have been expanded to cover Applied and Industrial Mathematics. Coverage of the journal has been strengthened in probabilistic applications, while still focusing on those areas of applied mathematics inspired by real-world applications, and at the same time fostering the development of theoretical methods with a broad range of applicability. Survey papers contain reviews of emerging areas of mathematics, either in core areas or with relevance to users in industry and other disciplines. Research papers may be in any area of applied mathematics, with special emphasis on new mathematical ideas, relevant to modelling and analysis in modern science and technology, and the development of interesting mathematical methods of wide applicability.
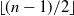 $\lfloor (n-1)/2\rfloor$
, and hence it is significantly smaller than that of GD whose dimension is
$\lfloor (n-1)/2\rfloor$
, and hence it is significantly smaller than that of GD whose dimension is
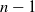 $n-1$
.
$n-1$
.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
