{"title":"更正 \"机器接管:用于发散性思维任务自动评分的各种监督学习方法的比较\"","authors":"","doi":"10.1002/jocb.627","DOIUrl":null,"url":null,"abstract":"<p>Buczak, P., Huang, H., Forthmann, B., & Doebler, P. (2023). The machines take over: A comparison of various supervised learning approaches for automated scoring of divergent thinking tasks. <i>The Journal of Creative Behavior</i>, <i>57</i>, 17–36. https://doi.org/10.1002/jocb.559\n </p><p>Due to an error in our code for the data preprocessing, we only utilized the word embeddings (WEs) of the last word in sentences instead of aggregating all WEs. This affected the use of WEs as model features and resulted in incomplete data usage. Our program code has been fixed and we have rerun our simulations.</p><p>We apologize for this error.</p><p>To highlight the most important differences between the findings reported in Buczak et al. (2023) and the corrected findings, Figure 1 shows the changes in terms of RMSE for the three learners on the Hofelich-Mohr et al. (2016) data set when applied in the setting of our first simulation study using two different semantic spaces. Overall, support vector regression (SVR), extreme gradient boosting (XGB), and random forest (RF) models profited greatly from the updated WEs whenever these were directly included as features. As the “Meta” feature set did not contain WEs in any form, the corresponding models and their results remained unaffected by the change. For the “Meta- + WE-based” feature set, however, the model's performance declined slightly. Regarding the learners, the updated WEs mostly led to a noticeable jump in performance for SVR when using a low-dimensional semantic space (i.e., 50 or 100 dimensions). In these cases, SVR even outperformed XGB and RF. However, SVR suffered when using high-dimensional semantic spaces. Apart from SVR, only subtle differences emerged regarding the choice of semantic space for XGB and RF.</p><p>Similar patterns of change were observed in the results for the Silvia et al. (2008) data, and when looking at correlations instead of the prediction RMSE for both data sets (figures were excluded for the sake of brevity). For the cross-sample prediction setup in our second simulation study, this mostly held up as well. However, when training on Hofelich-Mohr et al. (2016) and predicting Silvia et al. (2008), the performance of SVR increased with increasing semantic space dimensionality when studying the RMSE. For correlation scores, SVR's performance, again, suffered when a semantic space of high dimensionality was used.</p><p>As for the models using the WEs directly, the improved performance was to be expected since the aggregated WEs of all words capture more information about the answer than the WEs of a single word. However, the reasons behind the performance decrease for the models using WE-based features seem less clear-cut. Perhaps, WE-based features such as cosine similarity, WE norm, and the number of high-loading WEs degraded slightly in quality because we added word vectors from single words, including words almost unrelated to the idea described.</p><p>Although the respective feature sets were differently affected by the updated WEs, the overall order of performances achieved by the feature sets remained mostly unchanged. However, including further features alongside WEs does not necessarily enhance model performance as before. For the Silvia et al. (2008) data, models with the combined feature set achieved slightly lower performance than models with only WEs as features. Thus, one should consider the data at hand when deciding whether the WEs need to be complemented by further features.</p><p>The fact that for our initial analysis using the WEs of an answer's last word already substantially improved the performance could be explained by the nature of the DT task answers encountered in the data we used. As can be seen in Figure 2, answers were often comprised of single words or short phrases likely to contain the answer's key information in its last word. Thus, the initial models using only the WEs of an answer's last word already performed quite well in this case.</p><p>In terms of feature importance, the updated results revealed some changes regarding the importance order. However, the partial dependency plots (PDP) for the features stimulus similarity and number of words displayed the trend initially reported. In our updated results, we have provided additional PDPs for the WE norm and the number of high-loading WE component features.</p><p>Regarding the significant performance differences of SVR concerning the dimensionality of the semantic space, we posit that the root of the issue lies in the fact that the SVR fitted in this case utilizes radial basis function kernels. It has been repeatedly stressed in the support vector literature that kernel choice matters, especially in high-dimensional settings, and that dimension reduction techniques are advisable.</p><p>Even though SVR partly outperformed XGB and RF slightly for low-dimensional semantic spaces, we still stand by our initial recommendation of XGB and RF as they displayed less sensitivity to the choice of the semantic space. If, however, SVR is to be used, reducing the dimensionality of WEs, for example, via principal components analysis, remains a viable option. Furthermore, our recommendation of using additive word composition over padding is even strengthened as the new results mostly closed the predictive performance gap present in our initial analysis. As an additional result from the correction process, we observed that typical English language responses to alternate uses tasks often place a noun central for the idea conveyed at the end of a sentence, and hence, the WEs of the last word proved to be surprisingly predictive. Apart from these aspects, the original discussion remains unaffected.</p>","PeriodicalId":39915,"journal":{"name":"Journal of Creative Behavior","volume":"58 3","pages":"530-532"},"PeriodicalIF":3.0000,"publicationDate":"2023-12-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/jocb.627","citationCount":"0","resultStr":"{\"title\":\"Correction to “The Machines Take over: A Comparison of Various Supervised Learning Approaches for Automated Scoring of Divergent Thinking Tasks”\",\"authors\":\"\",\"doi\":\"10.1002/jocb.627\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Buczak, P., Huang, H., Forthmann, B., & Doebler, P. (2023). The machines take over: A comparison of various supervised learning approaches for automated scoring of divergent thinking tasks. <i>The Journal of Creative Behavior</i>, <i>57</i>, 17–36. https://doi.org/10.1002/jocb.559\\n </p><p>Due to an error in our code for the data preprocessing, we only utilized the word embeddings (WEs) of the last word in sentences instead of aggregating all WEs. This affected the use of WEs as model features and resulted in incomplete data usage. Our program code has been fixed and we have rerun our simulations.</p><p>We apologize for this error.</p><p>To highlight the most important differences between the findings reported in Buczak et al. (2023) and the corrected findings, Figure 1 shows the changes in terms of RMSE for the three learners on the Hofelich-Mohr et al. (2016) data set when applied in the setting of our first simulation study using two different semantic spaces. Overall, support vector regression (SVR), extreme gradient boosting (XGB), and random forest (RF) models profited greatly from the updated WEs whenever these were directly included as features. As the “Meta” feature set did not contain WEs in any form, the corresponding models and their results remained unaffected by the change. For the “Meta- + WE-based” feature set, however, the model's performance declined slightly. Regarding the learners, the updated WEs mostly led to a noticeable jump in performance for SVR when using a low-dimensional semantic space (i.e., 50 or 100 dimensions). In these cases, SVR even outperformed XGB and RF. However, SVR suffered when using high-dimensional semantic spaces. Apart from SVR, only subtle differences emerged regarding the choice of semantic space for XGB and RF.</p><p>Similar patterns of change were observed in the results for the Silvia et al. (2008) data, and when looking at correlations instead of the prediction RMSE for both data sets (figures were excluded for the sake of brevity). For the cross-sample prediction setup in our second simulation study, this mostly held up as well. However, when training on Hofelich-Mohr et al. (2016) and predicting Silvia et al. (2008), the performance of SVR increased with increasing semantic space dimensionality when studying the RMSE. For correlation scores, SVR's performance, again, suffered when a semantic space of high dimensionality was used.</p><p>As for the models using the WEs directly, the improved performance was to be expected since the aggregated WEs of all words capture more information about the answer than the WEs of a single word. However, the reasons behind the performance decrease for the models using WE-based features seem less clear-cut. Perhaps, WE-based features such as cosine similarity, WE norm, and the number of high-loading WEs degraded slightly in quality because we added word vectors from single words, including words almost unrelated to the idea described.</p><p>Although the respective feature sets were differently affected by the updated WEs, the overall order of performances achieved by the feature sets remained mostly unchanged. However, including further features alongside WEs does not necessarily enhance model performance as before. For the Silvia et al. (2008) data, models with the combined feature set achieved slightly lower performance than models with only WEs as features. Thus, one should consider the data at hand when deciding whether the WEs need to be complemented by further features.</p><p>The fact that for our initial analysis using the WEs of an answer's last word already substantially improved the performance could be explained by the nature of the DT task answers encountered in the data we used. As can be seen in Figure 2, answers were often comprised of single words or short phrases likely to contain the answer's key information in its last word. Thus, the initial models using only the WEs of an answer's last word already performed quite well in this case.</p><p>In terms of feature importance, the updated results revealed some changes regarding the importance order. However, the partial dependency plots (PDP) for the features stimulus similarity and number of words displayed the trend initially reported. In our updated results, we have provided additional PDPs for the WE norm and the number of high-loading WE component features.</p><p>Regarding the significant performance differences of SVR concerning the dimensionality of the semantic space, we posit that the root of the issue lies in the fact that the SVR fitted in this case utilizes radial basis function kernels. It has been repeatedly stressed in the support vector literature that kernel choice matters, especially in high-dimensional settings, and that dimension reduction techniques are advisable.</p><p>Even though SVR partly outperformed XGB and RF slightly for low-dimensional semantic spaces, we still stand by our initial recommendation of XGB and RF as they displayed less sensitivity to the choice of the semantic space. If, however, SVR is to be used, reducing the dimensionality of WEs, for example, via principal components analysis, remains a viable option. Furthermore, our recommendation of using additive word composition over padding is even strengthened as the new results mostly closed the predictive performance gap present in our initial analysis. As an additional result from the correction process, we observed that typical English language responses to alternate uses tasks often place a noun central for the idea conveyed at the end of a sentence, and hence, the WEs of the last word proved to be surprisingly predictive. Apart from these aspects, the original discussion remains unaffected.</p>\",\"PeriodicalId\":39915,\"journal\":{\"name\":\"Journal of Creative Behavior\",\"volume\":\"58 3\",\"pages\":\"530-532\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2023-12-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/jocb.627\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Creative Behavior\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/jocb.627\",\"RegionNum\":2,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"PSYCHOLOGY, EDUCATIONAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Creative Behavior","FirstCategoryId":"102","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/jocb.627","RegionNum":2,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PSYCHOLOGY, EDUCATIONAL","Score":null,"Total":0}
Correction to “The Machines Take over: A Comparison of Various Supervised Learning Approaches for Automated Scoring of Divergent Thinking Tasks”
Buczak, P., Huang, H., Forthmann, B., & Doebler, P. (2023). The machines take over: A comparison of various supervised learning approaches for automated scoring of divergent thinking tasks. The Journal of Creative Behavior, 57, 17–36. https://doi.org/10.1002/jocb.559
Due to an error in our code for the data preprocessing, we only utilized the word embeddings (WEs) of the last word in sentences instead of aggregating all WEs. This affected the use of WEs as model features and resulted in incomplete data usage. Our program code has been fixed and we have rerun our simulations.
We apologize for this error.
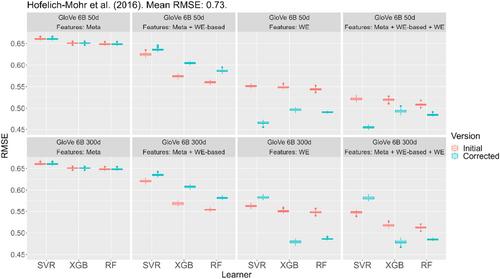
To highlight the most important differences between the findings reported in Buczak et al. (2023) and the corrected findings, Figure 1 shows the changes in terms of RMSE for the three learners on the Hofelich-Mohr et al. (2016) data set when applied in the setting of our first simulation study using two different semantic spaces. Overall, support vector regression (SVR), extreme gradient boosting (XGB), and random forest (RF) models profited greatly from the updated WEs whenever these were directly included as features. As the “Meta” feature set did not contain WEs in any form, the corresponding models and their results remained unaffected by the change. For the “Meta- + WE-based” feature set, however, the model's performance declined slightly. Regarding the learners, the updated WEs mostly led to a noticeable jump in performance for SVR when using a low-dimensional semantic space (i.e., 50 or 100 dimensions). In these cases, SVR even outperformed XGB and RF. However, SVR suffered when using high-dimensional semantic spaces. Apart from SVR, only subtle differences emerged regarding the choice of semantic space for XGB and RF.
Similar patterns of change were observed in the results for the Silvia et al. (2008) data, and when looking at correlations instead of the prediction RMSE for both data sets (figures were excluded for the sake of brevity). For the cross-sample prediction setup in our second simulation study, this mostly held up as well. However, when training on Hofelich-Mohr et al. (2016) and predicting Silvia et al. (2008), the performance of SVR increased with increasing semantic space dimensionality when studying the RMSE. For correlation scores, SVR's performance, again, suffered when a semantic space of high dimensionality was used.
As for the models using the WEs directly, the improved performance was to be expected since the aggregated WEs of all words capture more information about the answer than the WEs of a single word. However, the reasons behind the performance decrease for the models using WE-based features seem less clear-cut. Perhaps, WE-based features such as cosine similarity, WE norm, and the number of high-loading WEs degraded slightly in quality because we added word vectors from single words, including words almost unrelated to the idea described.
Although the respective feature sets were differently affected by the updated WEs, the overall order of performances achieved by the feature sets remained mostly unchanged. However, including further features alongside WEs does not necessarily enhance model performance as before. For the Silvia et al. (2008) data, models with the combined feature set achieved slightly lower performance than models with only WEs as features. Thus, one should consider the data at hand when deciding whether the WEs need to be complemented by further features.
The fact that for our initial analysis using the WEs of an answer's last word already substantially improved the performance could be explained by the nature of the DT task answers encountered in the data we used. As can be seen in Figure 2, answers were often comprised of single words or short phrases likely to contain the answer's key information in its last word. Thus, the initial models using only the WEs of an answer's last word already performed quite well in this case.
In terms of feature importance, the updated results revealed some changes regarding the importance order. However, the partial dependency plots (PDP) for the features stimulus similarity and number of words displayed the trend initially reported. In our updated results, we have provided additional PDPs for the WE norm and the number of high-loading WE component features.
Regarding the significant performance differences of SVR concerning the dimensionality of the semantic space, we posit that the root of the issue lies in the fact that the SVR fitted in this case utilizes radial basis function kernels. It has been repeatedly stressed in the support vector literature that kernel choice matters, especially in high-dimensional settings, and that dimension reduction techniques are advisable.
Even though SVR partly outperformed XGB and RF slightly for low-dimensional semantic spaces, we still stand by our initial recommendation of XGB and RF as they displayed less sensitivity to the choice of the semantic space. If, however, SVR is to be used, reducing the dimensionality of WEs, for example, via principal components analysis, remains a viable option. Furthermore, our recommendation of using additive word composition over padding is even strengthened as the new results mostly closed the predictive performance gap present in our initial analysis. As an additional result from the correction process, we observed that typical English language responses to alternate uses tasks often place a noun central for the idea conveyed at the end of a sentence, and hence, the WEs of the last word proved to be surprisingly predictive. Apart from these aspects, the original discussion remains unaffected.
期刊介绍:
The Journal of Creative Behavior is our quarterly academic journal citing the most current research in creative thinking. For nearly four decades JCB has been the benchmark scientific periodical in the field. It provides up to date cutting-edge ideas about creativity in education, psychology, business, arts and more.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
