{"title":"在视觉单词的内隐加工过程中寻求印刷品统计属性的神经表征","authors":"Jianyi Liu, Tengwen Fan, Yan Chen, Jingjing Zhao","doi":"10.1038/s41539-023-00209-3","DOIUrl":null,"url":null,"abstract":"<p>Statistical learning (SL) plays a key role in literacy acquisition. Studies have increasingly revealed the influence of distributional statistical properties of words on visual word processing, including the effects of word frequency (lexical level) and mappings between orthography, phonology, and semantics (sub-lexical level). However, there has been scant evidence to directly confirm that the statistical properties contained in print can be directly characterized by neural activities. Using time-resolved representational similarity analysis (RSA), the present study examined neural representations of different types of statistical properties in visual word processing. From the perspective of predictive coding, an equal probability sequence with low built-in prediction precision and three oddball sequences with high built-in prediction precision were designed with consistent and three types of inconsistent (orthographically inconsistent, orthography-to-phonology inconsistent, and orthography-to-semantics inconsistent) Chinese characters as visual stimuli. In the three oddball sequences, consistent characters were set as the standard stimuli (probability of occurrence <i>p</i> = 0.75) and three types of inconsistent characters were set as deviant stimuli (<i>p</i> = 0.25), respectively. In the equal probability sequence, the same consistent and inconsistent characters were presented randomly with identical occurrence probability (<i>p</i> = 0.25). Significant neural representation activities of word frequency were observed in the equal probability sequence. By contrast, neural representations of sub-lexical statistics only emerged in oddball sequences where short-term predictions were shaped. These findings reveal that the statistical properties learned from long-term print environment continues to play a role in current word processing mechanisms and these mechanisms can be modulated by short-term predictions.</p>","PeriodicalId":48503,"journal":{"name":"npj Science of Learning","volume":"5 1","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2023-12-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Seeking the neural representation of statistical properties in print during implicit processing of visual words\",\"authors\":\"Jianyi Liu, Tengwen Fan, Yan Chen, Jingjing Zhao\",\"doi\":\"10.1038/s41539-023-00209-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Statistical learning (SL) plays a key role in literacy acquisition. Studies have increasingly revealed the influence of distributional statistical properties of words on visual word processing, including the effects of word frequency (lexical level) and mappings between orthography, phonology, and semantics (sub-lexical level). However, there has been scant evidence to directly confirm that the statistical properties contained in print can be directly characterized by neural activities. Using time-resolved representational similarity analysis (RSA), the present study examined neural representations of different types of statistical properties in visual word processing. From the perspective of predictive coding, an equal probability sequence with low built-in prediction precision and three oddball sequences with high built-in prediction precision were designed with consistent and three types of inconsistent (orthographically inconsistent, orthography-to-phonology inconsistent, and orthography-to-semantics inconsistent) Chinese characters as visual stimuli. In the three oddball sequences, consistent characters were set as the standard stimuli (probability of occurrence <i>p</i> = 0.75) and three types of inconsistent characters were set as deviant stimuli (<i>p</i> = 0.25), respectively. In the equal probability sequence, the same consistent and inconsistent characters were presented randomly with identical occurrence probability (<i>p</i> = 0.25). Significant neural representation activities of word frequency were observed in the equal probability sequence. By contrast, neural representations of sub-lexical statistics only emerged in oddball sequences where short-term predictions were shaped. These findings reveal that the statistical properties learned from long-term print environment continues to play a role in current word processing mechanisms and these mechanisms can be modulated by short-term predictions.</p>\",\"PeriodicalId\":48503,\"journal\":{\"name\":\"npj Science of Learning\",\"volume\":\"5 1\",\"pages\":\"\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2023-12-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"npj Science of Learning\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://doi.org/10.1038/s41539-023-00209-3\",\"RegionNum\":1,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION & EDUCATIONAL RESEARCH\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"npj Science of Learning","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.1038/s41539-023-00209-3","RegionNum":1,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION & EDUCATIONAL RESEARCH","Score":null,"Total":0}
引用次数: 0
摘要
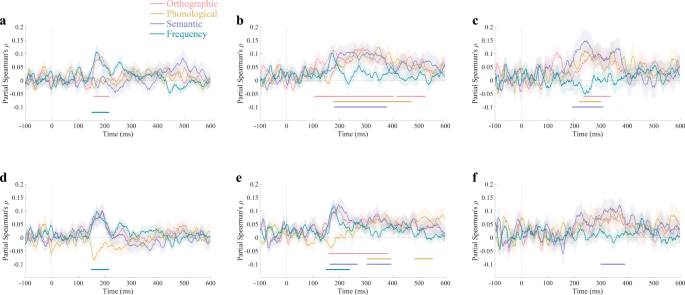
统计学习(SL)在识字学习中起着关键作用。越来越多的研究揭示了单词的分布统计属性对视觉单词处理的影响,包括单词频率(词法层面)以及正字法、语音学和语义学(次词法层面)之间映射的影响。然而,很少有证据能直接证实印刷品中包含的统计属性可以直接用神经活动来表征。本研究利用时间分辨表征相似性分析(RSA),考察了视觉文字处理中不同类型统计属性的神经表征。从预测编码的角度出发,我们设计了一个内建预测精度较低的等概率序列和三个内建预测精度较高的奇数序列,以一致和三种不一致(正字法不一致、正字法与语音不一致和正字法与语义不一致)的汉字作为视觉刺激。在三个奇数序列中,一致的汉字被设定为标准刺激(出现概率 p = 0.75),三种不一致的汉字被设定为偏差刺激(p = 0.25)。在等概率序列中,相同的一致字符和不一致字符以相同的出现概率随机出现(p = 0.25)。在等概率序列中,可以观察到明显的词频神经表征活动。相比之下,只有在形成短期预测的奇数序列中才会出现次词汇统计的神经表征。这些研究结果表明,从长期印刷环境中学到的统计特性在当前的文字处理机制中继续发挥作用,而且这些机制可以受到短期预测的调节。
Seeking the neural representation of statistical properties in print during implicit processing of visual words
Statistical learning (SL) plays a key role in literacy acquisition. Studies have increasingly revealed the influence of distributional statistical properties of words on visual word processing, including the effects of word frequency (lexical level) and mappings between orthography, phonology, and semantics (sub-lexical level). However, there has been scant evidence to directly confirm that the statistical properties contained in print can be directly characterized by neural activities. Using time-resolved representational similarity analysis (RSA), the present study examined neural representations of different types of statistical properties in visual word processing. From the perspective of predictive coding, an equal probability sequence with low built-in prediction precision and three oddball sequences with high built-in prediction precision were designed with consistent and three types of inconsistent (orthographically inconsistent, orthography-to-phonology inconsistent, and orthography-to-semantics inconsistent) Chinese characters as visual stimuli. In the three oddball sequences, consistent characters were set as the standard stimuli (probability of occurrence p = 0.75) and three types of inconsistent characters were set as deviant stimuli (p = 0.25), respectively. In the equal probability sequence, the same consistent and inconsistent characters were presented randomly with identical occurrence probability (p = 0.25). Significant neural representation activities of word frequency were observed in the equal probability sequence. By contrast, neural representations of sub-lexical statistics only emerged in oddball sequences where short-term predictions were shaped. These findings reveal that the statistical properties learned from long-term print environment continues to play a role in current word processing mechanisms and these mechanisms can be modulated by short-term predictions.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
