{"title":"临床抑郁症自动诊断系统综述","authors":"Kaining Mao, Yuqi Wu, Jie Chen","doi":"10.1038/s44184-023-00040-z","DOIUrl":null,"url":null,"abstract":"Assessing mental health disorders and determining treatment can be difficult for a number of reasons, including access to healthcare providers. Assessments and treatments may not be continuous and can be limited by the unpredictable nature of psychiatric symptoms. Machine-learning models using data collected in a clinical setting can improve diagnosis and treatment. Studies have used speech, text, and facial expression analysis to identify depression. Still, more research is needed to address challenges such as the need for multimodality machine-learning models for clinical use. We conducted a review of studies from the past decade that utilized speech, text, and facial expression analysis to detect depression, as defined by the Diagnostic and Statistical Manual of Mental Disorders (DSM-5), using the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) guideline. We provide information on the number of participants, techniques used to assess clinical outcomes, speech-eliciting tasks, machine-learning algorithms, metrics, and other important discoveries for each study. A total of 544 studies were examined, 264 of which satisfied the inclusion criteria. A database has been created containing the query results and a summary of how different features are used to detect depression. While machine learning shows its potential to enhance mental health disorder evaluations, some obstacles must be overcome, especially the requirement for more transparent machine-learning models for clinical purposes. Considering the variety of datasets, feature extraction techniques, and metrics used in this field, guidelines have been provided to collect data and train machine-learning models to guarantee reproducibility and generalizability across different contexts.","PeriodicalId":74321,"journal":{"name":"Npj mental health research","volume":" ","pages":"1-17"},"PeriodicalIF":9.1000,"publicationDate":"2023-11-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s44184-023-00040-z.pdf","citationCount":"0","resultStr":"{\"title\":\"A systematic review on automated clinical depression diagnosis\",\"authors\":\"Kaining Mao, Yuqi Wu, Jie Chen\",\"doi\":\"10.1038/s44184-023-00040-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Assessing mental health disorders and determining treatment can be difficult for a number of reasons, including access to healthcare providers. Assessments and treatments may not be continuous and can be limited by the unpredictable nature of psychiatric symptoms. Machine-learning models using data collected in a clinical setting can improve diagnosis and treatment. Studies have used speech, text, and facial expression analysis to identify depression. Still, more research is needed to address challenges such as the need for multimodality machine-learning models for clinical use. We conducted a review of studies from the past decade that utilized speech, text, and facial expression analysis to detect depression, as defined by the Diagnostic and Statistical Manual of Mental Disorders (DSM-5), using the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) guideline. We provide information on the number of participants, techniques used to assess clinical outcomes, speech-eliciting tasks, machine-learning algorithms, metrics, and other important discoveries for each study. A total of 544 studies were examined, 264 of which satisfied the inclusion criteria. A database has been created containing the query results and a summary of how different features are used to detect depression. While machine learning shows its potential to enhance mental health disorder evaluations, some obstacles must be overcome, especially the requirement for more transparent machine-learning models for clinical purposes. Considering the variety of datasets, feature extraction techniques, and metrics used in this field, guidelines have been provided to collect data and train machine-learning models to guarantee reproducibility and generalizability across different contexts.\",\"PeriodicalId\":74321,\"journal\":{\"name\":\"Npj mental health research\",\"volume\":\" \",\"pages\":\"1-17\"},\"PeriodicalIF\":9.1000,\"publicationDate\":\"2023-11-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s44184-023-00040-z.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Npj mental health research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.nature.com/articles/s44184-023-00040-z\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Npj mental health research","FirstCategoryId":"1085","ListUrlMain":"https://www.nature.com/articles/s44184-023-00040-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
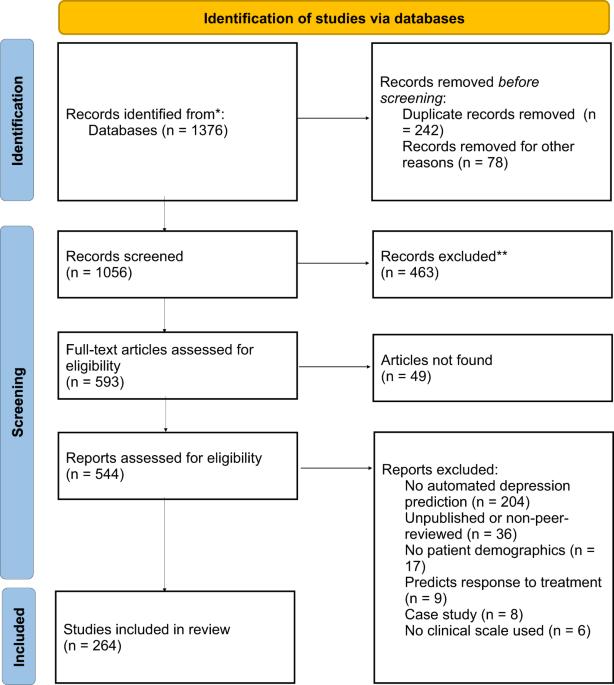
由于多种原因,包括难以获得医疗服务提供者的帮助,评估精神疾病和确定治疗方法可能很困难。评估和治疗可能不具有连续性,而且会受到精神症状不可预知性的限制。使用在临床环境中收集的数据建立机器学习模型可以改善诊断和治疗。已有研究利用语音、文本和面部表情分析来识别抑郁症。然而,我们仍需要更多的研究来应对挑战,例如临床使用多模态机器学习模型的需求。我们采用《系统综述与元分析首选报告项目》(Preferred Reporting Items for Systematic Reviews and Meta-Analysis,PRISMA)指南,对过去十年利用语音、文本和面部表情分析检测《精神疾病诊断与统计手册》(DSM-5)所定义的抑郁症的研究进行了综述。我们提供了每项研究的参与人数、用于评估临床结果的技术、语音诱导任务、机器学习算法、指标和其他重要发现等信息。共审查了 544 项研究,其中 264 项符合纳入标准。我们创建了一个数据库,其中包含查询结果以及如何利用不同特征检测抑郁症的总结。虽然机器学习在加强心理健康障碍评估方面显示出了潜力,但仍有一些障碍必须克服,尤其是要求用于临床目的的机器学习模型更加透明。考虑到这一领域使用的数据集、特征提取技术和衡量标准多种多样,我们提供了收集数据和训练机器学习模型的指南,以保证在不同情况下的可重复性和通用性。
A systematic review on automated clinical depression diagnosis
Assessing mental health disorders and determining treatment can be difficult for a number of reasons, including access to healthcare providers. Assessments and treatments may not be continuous and can be limited by the unpredictable nature of psychiatric symptoms. Machine-learning models using data collected in a clinical setting can improve diagnosis and treatment. Studies have used speech, text, and facial expression analysis to identify depression. Still, more research is needed to address challenges such as the need for multimodality machine-learning models for clinical use. We conducted a review of studies from the past decade that utilized speech, text, and facial expression analysis to detect depression, as defined by the Diagnostic and Statistical Manual of Mental Disorders (DSM-5), using the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) guideline. We provide information on the number of participants, techniques used to assess clinical outcomes, speech-eliciting tasks, machine-learning algorithms, metrics, and other important discoveries for each study. A total of 544 studies were examined, 264 of which satisfied the inclusion criteria. A database has been created containing the query results and a summary of how different features are used to detect depression. While machine learning shows its potential to enhance mental health disorder evaluations, some obstacles must be overcome, especially the requirement for more transparent machine-learning models for clinical purposes. Considering the variety of datasets, feature extraction techniques, and metrics used in this field, guidelines have been provided to collect data and train machine-learning models to guarantee reproducibility and generalizability across different contexts.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
