Yujia Peng, Joseph M Burling, Greta K Todorova, Catherine Neary, Frank E Pollick, Hongjing Lu
{"title":"突出显示和语义特征模式区分了监控录像专家和新手观众的注视。","authors":"Yujia Peng, Joseph M Burling, Greta K Todorova, Catherine Neary, Frank E Pollick, Hongjing Lu","doi":"10.3758/s13423-024-02454-y","DOIUrl":null,"url":null,"abstract":"<p><p>When viewing the actions of others, we not only see patterns of body movements, but we also \"see\" the intentions and social relations of people. Experienced forensic examiners - Closed Circuit Television (CCTV) operators - have been shown to convey superior performance in identifying and predicting hostile intentions from surveillance footage than novices. However, it remains largely unknown what visual content CCTV operators actively attend to, and whether CCTV operators develop different strategies for active information seeking from what novices do. Here, we conducted computational analysis for the gaze-centered stimuli captured by experienced CCTV operators and novices' eye movements when viewing the same surveillance footage. Low-level image features were extracted by a visual saliency model, whereas object-level semantic features were extracted by a deep convolutional neural network (DCNN), AlexNet, from gaze-centered regions. We found that the looking behavior of CCTV operators differs from novices by actively attending to visual contents with different patterns of saliency and semantic features. Expertise in selectively utilizing informative features at different levels of visual hierarchy may play an important role in facilitating the efficient detection of social relationships between agents and the prediction of harmful intentions.</p>","PeriodicalId":20763,"journal":{"name":"Psychonomic Bulletin & Review","volume":" ","pages":"1745-1758"},"PeriodicalIF":3.0000,"publicationDate":"2024-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11358171/pdf/","citationCount":"0","resultStr":"{\"title\":\"Patterns of saliency and semantic features distinguish gaze of expert and novice viewers of surveillance footage.\",\"authors\":\"Yujia Peng, Joseph M Burling, Greta K Todorova, Catherine Neary, Frank E Pollick, Hongjing Lu\",\"doi\":\"10.3758/s13423-024-02454-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>When viewing the actions of others, we not only see patterns of body movements, but we also \\\"see\\\" the intentions and social relations of people. Experienced forensic examiners - Closed Circuit Television (CCTV) operators - have been shown to convey superior performance in identifying and predicting hostile intentions from surveillance footage than novices. However, it remains largely unknown what visual content CCTV operators actively attend to, and whether CCTV operators develop different strategies for active information seeking from what novices do. Here, we conducted computational analysis for the gaze-centered stimuli captured by experienced CCTV operators and novices' eye movements when viewing the same surveillance footage. Low-level image features were extracted by a visual saliency model, whereas object-level semantic features were extracted by a deep convolutional neural network (DCNN), AlexNet, from gaze-centered regions. We found that the looking behavior of CCTV operators differs from novices by actively attending to visual contents with different patterns of saliency and semantic features. Expertise in selectively utilizing informative features at different levels of visual hierarchy may play an important role in facilitating the efficient detection of social relationships between agents and the prediction of harmful intentions.</p>\",\"PeriodicalId\":20763,\"journal\":{\"name\":\"Psychonomic Bulletin & Review\",\"volume\":\" \",\"pages\":\"1745-1758\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11358171/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Psychonomic Bulletin & Review\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://doi.org/10.3758/s13423-024-02454-y\",\"RegionNum\":3,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/25 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"PSYCHOLOGY, EXPERIMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Psychonomic Bulletin & Review","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.3758/s13423-024-02454-y","RegionNum":3,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/25 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"PSYCHOLOGY, EXPERIMENTAL","Score":null,"Total":0}
Patterns of saliency and semantic features distinguish gaze of expert and novice viewers of surveillance footage.
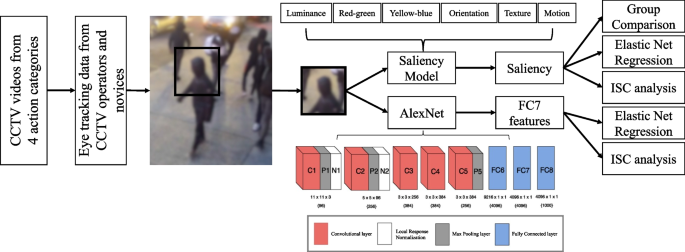
When viewing the actions of others, we not only see patterns of body movements, but we also "see" the intentions and social relations of people. Experienced forensic examiners - Closed Circuit Television (CCTV) operators - have been shown to convey superior performance in identifying and predicting hostile intentions from surveillance footage than novices. However, it remains largely unknown what visual content CCTV operators actively attend to, and whether CCTV operators develop different strategies for active information seeking from what novices do. Here, we conducted computational analysis for the gaze-centered stimuli captured by experienced CCTV operators and novices' eye movements when viewing the same surveillance footage. Low-level image features were extracted by a visual saliency model, whereas object-level semantic features were extracted by a deep convolutional neural network (DCNN), AlexNet, from gaze-centered regions. We found that the looking behavior of CCTV operators differs from novices by actively attending to visual contents with different patterns of saliency and semantic features. Expertise in selectively utilizing informative features at different levels of visual hierarchy may play an important role in facilitating the efficient detection of social relationships between agents and the prediction of harmful intentions.
期刊介绍:
The journal provides coverage spanning a broad spectrum of topics in all areas of experimental psychology. The journal is primarily dedicated to the publication of theory and review articles and brief reports of outstanding experimental work. Areas of coverage include cognitive psychology broadly construed, including but not limited to action, perception, & attention, language, learning & memory, reasoning & decision making, and social cognition. We welcome submissions that approach these issues from a variety of perspectives such as behavioral measurements, comparative psychology, development, evolutionary psychology, genetics, neuroscience, and quantitative/computational modeling. We particularly encourage integrative research that crosses traditional content and methodological boundaries.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
