Ariel Dadush, Rona Merdler-Rabinowicz, David Gorelik, Ariel Feiglin, Ilana Buchumenski, Lipika R Pal, Shay Ben-Aroya, Eytan Ruppin, Erez Y Levanon
{"title":"DNA 和 RNA 碱基编辑器可以纠正大多数致病性单核苷酸变异。","authors":"Ariel Dadush, Rona Merdler-Rabinowicz, David Gorelik, Ariel Feiglin, Ilana Buchumenski, Lipika R Pal, Shay Ben-Aroya, Eytan Ruppin, Erez Y Levanon","doi":"10.1038/s41525-024-00397-w","DOIUrl":null,"url":null,"abstract":"<p><p>The majority of human genetic diseases are caused by single nucleotide variants (SNVs) in the genome sequence. Excitingly, new genomic techniques known as base editing have opened efficient pathways to correct erroneous nucleotides. Due to reliance on deaminases, which have the capability to convert A to I(G) and C to U, the direct applicability of base editing might seem constrained in terms of the range of mutations that can be reverted. In this evaluation, we assess the potential of DNA and RNA base editing methods for treating human genetic diseases. Our findings indicate that 62% of pathogenic SNVs found within genes can be amended by base editing; 30% are G>A and T>C SNVs that can be corrected by DNA base editing, and most of them by RNA base editing as well, and 29% are C>T and A>G SNVs that can be corrected by DNA base editing directed to the complementary strand. For each, we also present several factors that affect applicability such as bystander and off-target occurrences. For cases where editing the mismatched nucleotide is not feasible, we introduce an approach that calculates the optimal substitution of the deleterious amino acid with a new amino acid, further expanding the scope of applicability. As personalized therapy is rapidly advancing, our demonstration that most SNVs can be treated by base editing is of high importance. The data provided will serve as a comprehensive resource for those seeking to design therapeutic base editors and study their potential in curing genetic diseases.</p>","PeriodicalId":19273,"journal":{"name":"NPJ Genomic Medicine","volume":"9 1","pages":"16"},"PeriodicalIF":4.7000,"publicationDate":"2024-02-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10897195/pdf/","citationCount":"0","resultStr":"{\"title\":\"DNA and RNA base editors can correct the majority of pathogenic single nucleotide variants.\",\"authors\":\"Ariel Dadush, Rona Merdler-Rabinowicz, David Gorelik, Ariel Feiglin, Ilana Buchumenski, Lipika R Pal, Shay Ben-Aroya, Eytan Ruppin, Erez Y Levanon\",\"doi\":\"10.1038/s41525-024-00397-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The majority of human genetic diseases are caused by single nucleotide variants (SNVs) in the genome sequence. Excitingly, new genomic techniques known as base editing have opened efficient pathways to correct erroneous nucleotides. Due to reliance on deaminases, which have the capability to convert A to I(G) and C to U, the direct applicability of base editing might seem constrained in terms of the range of mutations that can be reverted. In this evaluation, we assess the potential of DNA and RNA base editing methods for treating human genetic diseases. Our findings indicate that 62% of pathogenic SNVs found within genes can be amended by base editing; 30% are G>A and T>C SNVs that can be corrected by DNA base editing, and most of them by RNA base editing as well, and 29% are C>T and A>G SNVs that can be corrected by DNA base editing directed to the complementary strand. For each, we also present several factors that affect applicability such as bystander and off-target occurrences. For cases where editing the mismatched nucleotide is not feasible, we introduce an approach that calculates the optimal substitution of the deleterious amino acid with a new amino acid, further expanding the scope of applicability. As personalized therapy is rapidly advancing, our demonstration that most SNVs can be treated by base editing is of high importance. The data provided will serve as a comprehensive resource for those seeking to design therapeutic base editors and study their potential in curing genetic diseases.</p>\",\"PeriodicalId\":19273,\"journal\":{\"name\":\"NPJ Genomic Medicine\",\"volume\":\"9 1\",\"pages\":\"16\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2024-02-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10897195/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"NPJ Genomic Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1038/s41525-024-00397-w\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"GENETICS & HEREDITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"NPJ Genomic Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1038/s41525-024-00397-w","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
摘要
大多数人类遗传疾病都是由基因组序列中的单核苷酸变异(SNV)引起的。令人振奋的是,被称为碱基编辑的新基因组技术为纠正错误核苷酸开辟了有效途径。由于依赖脱氨酶将 A 转为 I(G)和将 C 转为 U,碱基编辑的直接适用性在可恢复的突变范围方面似乎受到了限制。在本评估中,我们评估了 DNA 和 RNA 碱基编辑方法治疗人类遗传疾病的潜力。我们的研究结果表明,基因中 62% 的致病性 SNV 可通过碱基编辑进行修正;30% 的 G>A 和 T>C SNV 可通过 DNA 碱基编辑进行修正,其中大部分也可通过 RNA 碱基编辑进行修正;29% 的 C>T 和 A>G SNV 可通过针对互补链的 DNA 碱基编辑进行修正。对于每种情况,我们还介绍了影响适用性的几个因素,如旁观者和脱靶现象。对于编辑错配核苷酸不可行的情况,我们介绍了一种计算有害氨基酸与新氨基酸最佳置换的方法,进一步扩大了适用范围。随着个性化治疗的快速发展,我们证明大多数 SNV 都可以通过碱基编辑来治疗,这一点非常重要。我们提供的数据将为那些寻求设计治疗性碱基编辑器和研究其治疗遗传疾病潜力的人提供全面的资源。
DNA and RNA base editors can correct the majority of pathogenic single nucleotide variants.
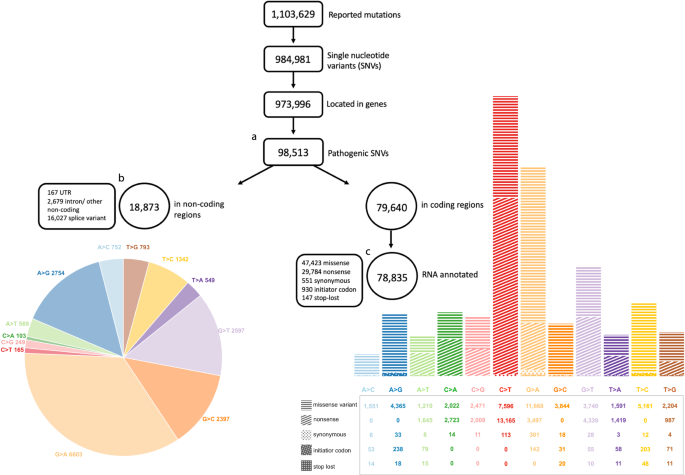
The majority of human genetic diseases are caused by single nucleotide variants (SNVs) in the genome sequence. Excitingly, new genomic techniques known as base editing have opened efficient pathways to correct erroneous nucleotides. Due to reliance on deaminases, which have the capability to convert A to I(G) and C to U, the direct applicability of base editing might seem constrained in terms of the range of mutations that can be reverted. In this evaluation, we assess the potential of DNA and RNA base editing methods for treating human genetic diseases. Our findings indicate that 62% of pathogenic SNVs found within genes can be amended by base editing; 30% are G>A and T>C SNVs that can be corrected by DNA base editing, and most of them by RNA base editing as well, and 29% are C>T and A>G SNVs that can be corrected by DNA base editing directed to the complementary strand. For each, we also present several factors that affect applicability such as bystander and off-target occurrences. For cases where editing the mismatched nucleotide is not feasible, we introduce an approach that calculates the optimal substitution of the deleterious amino acid with a new amino acid, further expanding the scope of applicability. As personalized therapy is rapidly advancing, our demonstration that most SNVs can be treated by base editing is of high importance. The data provided will serve as a comprehensive resource for those seeking to design therapeutic base editors and study their potential in curing genetic diseases.
NPJ Genomic MedicineBiochemistry, Genetics and Molecular Biology-Molecular Biology
CiteScore
9.40
自引率
1.90%
发文量
67
审稿时长
17 weeks
期刊介绍:
npj Genomic Medicine is an international, peer-reviewed journal dedicated to publishing the most important scientific advances in all aspects of genomics and its application in the practice of medicine.
The journal defines genomic medicine as "diagnosis, prognosis, prevention and/or treatment of disease and disorders of the mind and body, using approaches informed or enabled by knowledge of the genome and the molecules it encodes." Relevant and high-impact papers that encompass studies of individuals, families, or populations are considered for publication. An emphasis will include coupling detailed phenotype and genome sequencing information, both enabled by new technologies and informatics, to delineate the underlying aetiology of disease. Clinical recommendations and/or guidelines of how that data should be used in the clinical management of those patients in the study, and others, are also encouraged.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
