{"title":"ChatGPT 的记分卡是在多国进行一系列测试后得出的:生成式人工智能或大型语言模型的响应模式","authors":"Manojit Bhattacharya , Soumen Pal , Srijan Chatterjee , Abdulrahman Alshammari , Thamer H. Albekairi , Supriya Jagga , Elijah Ige Ohimain , Hatem Zayed , Siddappa N. Byrareddy , Sang-Soo Lee , Zhi-Hong Wen , Govindasamy Agoramoorthy , Prosun Bhattacharya , Chiranjib Chakraborty","doi":"10.1016/j.crbiot.2024.100194","DOIUrl":null,"url":null,"abstract":"<div><p>Recently, researchers have shown concern about the ChatGPT-derived answers. Here, we conducted a series of tests using ChatGPT by individual researcher at multi-country level to understand the pattern of its answer accuracy, reproducibility, answer length, plagiarism, and in-depth using two questionnaires (the first set with 15 MCQs and the second 15 KBQ). Among 15 MCQ-generated answers, 13 <span><math><mo>±</mo></math></span> 70 were correct (Median : 82.5; Coefficient variance : 4.85), 3 <span><math><mo>±</mo></math></span> 0.77 were incorrect (Median: 3, Coefficient variance: 25.81), and 1 to 10 were reproducible, and 11 to 15 were not. Among 15 KBQ, the length of each question (in words) is about 294.5 <span><math><mo>±</mo></math></span> 97.60 (mean range varies from 138.7 to 438.09), and the mean similarity index (in words) is about 29.53 <span><math><mo>±</mo></math></span> 11.40 (Coefficient variance: 38.62) for each question. The statistical models were also developed using analyzed parameters of answers. The study shows a pattern of ChatGPT-derive answers with correctness and incorrectness and urges for an error-free, next-generation LLM to avoid users’ misguidance.</p></div>","PeriodicalId":52676,"journal":{"name":"Current Research in Biotechnology","volume":"7 ","pages":"Article 100194"},"PeriodicalIF":6.7000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2590262824000200/pdfft?md5=c02e55a054a90a3e570a4fed3056ffaf&pid=1-s2.0-S2590262824000200-main.pdf","citationCount":"0","resultStr":"{\"title\":\"ChatGPT’s scorecard after the performance in a series of tests conducted at the multi-country level: A pattern of responses of generative artificial intelligence or large language models\",\"authors\":\"Manojit Bhattacharya , Soumen Pal , Srijan Chatterjee , Abdulrahman Alshammari , Thamer H. Albekairi , Supriya Jagga , Elijah Ige Ohimain , Hatem Zayed , Siddappa N. Byrareddy , Sang-Soo Lee , Zhi-Hong Wen , Govindasamy Agoramoorthy , Prosun Bhattacharya , Chiranjib Chakraborty\",\"doi\":\"10.1016/j.crbiot.2024.100194\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Recently, researchers have shown concern about the ChatGPT-derived answers. Here, we conducted a series of tests using ChatGPT by individual researcher at multi-country level to understand the pattern of its answer accuracy, reproducibility, answer length, plagiarism, and in-depth using two questionnaires (the first set with 15 MCQs and the second 15 KBQ). Among 15 MCQ-generated answers, 13 <span><math><mo>±</mo></math></span> 70 were correct (Median : 82.5; Coefficient variance : 4.85), 3 <span><math><mo>±</mo></math></span> 0.77 were incorrect (Median: 3, Coefficient variance: 25.81), and 1 to 10 were reproducible, and 11 to 15 were not. Among 15 KBQ, the length of each question (in words) is about 294.5 <span><math><mo>±</mo></math></span> 97.60 (mean range varies from 138.7 to 438.09), and the mean similarity index (in words) is about 29.53 <span><math><mo>±</mo></math></span> 11.40 (Coefficient variance: 38.62) for each question. The statistical models were also developed using analyzed parameters of answers. The study shows a pattern of ChatGPT-derive answers with correctness and incorrectness and urges for an error-free, next-generation LLM to avoid users’ misguidance.</p></div>\",\"PeriodicalId\":52676,\"journal\":{\"name\":\"Current Research in Biotechnology\",\"volume\":\"7 \",\"pages\":\"Article 100194\"},\"PeriodicalIF\":6.7000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2590262824000200/pdfft?md5=c02e55a054a90a3e570a4fed3056ffaf&pid=1-s2.0-S2590262824000200-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Current Research in Biotechnology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2590262824000200\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/3/2 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"BIOTECHNOLOGY & APPLIED MICROBIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Current Research in Biotechnology","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2590262824000200","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/3/2 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"BIOTECHNOLOGY & APPLIED MICROBIOLOGY","Score":null,"Total":0}
ChatGPT’s scorecard after the performance in a series of tests conducted at the multi-country level: A pattern of responses of generative artificial intelligence or large language models
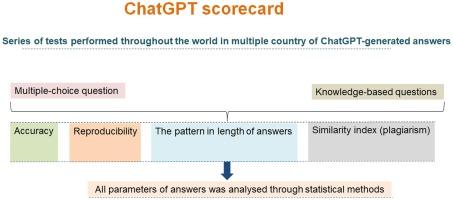
Recently, researchers have shown concern about the ChatGPT-derived answers. Here, we conducted a series of tests using ChatGPT by individual researcher at multi-country level to understand the pattern of its answer accuracy, reproducibility, answer length, plagiarism, and in-depth using two questionnaires (the first set with 15 MCQs and the second 15 KBQ). Among 15 MCQ-generated answers, 13 70 were correct (Median : 82.5; Coefficient variance : 4.85), 3 0.77 were incorrect (Median: 3, Coefficient variance: 25.81), and 1 to 10 were reproducible, and 11 to 15 were not. Among 15 KBQ, the length of each question (in words) is about 294.5 97.60 (mean range varies from 138.7 to 438.09), and the mean similarity index (in words) is about 29.53 11.40 (Coefficient variance: 38.62) for each question. The statistical models were also developed using analyzed parameters of answers. The study shows a pattern of ChatGPT-derive answers with correctness and incorrectness and urges for an error-free, next-generation LLM to avoid users’ misguidance.
期刊介绍:
Current Research in Biotechnology (CRBIOT) is a new primary research, gold open access journal from Elsevier. CRBIOT publishes original papers, reviews, and short communications (including viewpoints and perspectives) resulting from research in biotechnology and biotech-associated disciplines.
Current Research in Biotechnology is a peer-reviewed gold open access (OA) journal and upon acceptance all articles are permanently and freely available. It is a companion to the highly regarded review journal Current Opinion in Biotechnology (2018 CiteScore 8.450) and is part of the Current Opinion and Research (CO+RE) suite of journals. All CO+RE journals leverage the Current Opinion legacy-of editorial excellence, high-impact, and global reach-to ensure they are a widely read resource that is integral to scientists' workflow.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
