Mehrnoush Alizade, Rushabh Kheni, Stephen Price, Bryer C. Sousa, Danielle L. Cote, Rodica Neamtu
{"title":"纳米压痕绘图数据聚类方法比较研究","authors":"Mehrnoush Alizade, Rushabh Kheni, Stephen Price, Bryer C. Sousa, Danielle L. Cote, Rodica Neamtu","doi":"10.1007/s40192-024-00349-3","DOIUrl":null,"url":null,"abstract":"<p>Nanoindentation testing and instrumented indentation remain regularly utilized techniques for the assessment of multi-scale mechanical characteristics from load–displacement data analysis, which is central to twenty first century material characterization. The advent of high-resolution nanoindentation-based property mapping has, however, presented challenges in data interpretation, especially when applying proper clustering methodologies to quantify and interpret data as well as draw appropriate conclusions. In this research, we utilized the scikit-learn library in Python to assess the performance of various clustering algorithms, with a focus on nanoindentation-based hardness and elastic modulus measurements, and their synergistic effects. Clustering parameters were meticulously optimized, and in conjunction with domain expert recommendations, the total number of clusters was set to three. The evaluation was grounded in established clustering performance metrics such as the Davies–Bouldin Index, Calinski–Harabasz Index, and the Silhouette score, aiming to ascertain the optimal clustering approach. Among the eight evaluated clustering algorithms, K-means, Agglomerative and FCM emerged as the most effective, while the OPTICS algorithm consistently underperformed for the considered datasets. Augmenting this study, we introduce an intuitive interface, negating the necessity for prior coding or machine learning familiarity, and offering effortless model fine-tuning, visualization, and comparison. This innovation empowers material science and engineering experts, technical staff, and instrumentalists and facilitates the selection of ideal models across varied datasets. The insights and tools presented herein not only enrich material science and engineering research but also lay a robust foundation for sophisticated and dependable analyses in subsequent studies.</p>","PeriodicalId":13604,"journal":{"name":"Integrating Materials and Manufacturing Innovation","volume":"31 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-03-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A Comparative Study of Clustering Methods for Nanoindentation Mapping Data\",\"authors\":\"Mehrnoush Alizade, Rushabh Kheni, Stephen Price, Bryer C. Sousa, Danielle L. Cote, Rodica Neamtu\",\"doi\":\"10.1007/s40192-024-00349-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Nanoindentation testing and instrumented indentation remain regularly utilized techniques for the assessment of multi-scale mechanical characteristics from load–displacement data analysis, which is central to twenty first century material characterization. The advent of high-resolution nanoindentation-based property mapping has, however, presented challenges in data interpretation, especially when applying proper clustering methodologies to quantify and interpret data as well as draw appropriate conclusions. In this research, we utilized the scikit-learn library in Python to assess the performance of various clustering algorithms, with a focus on nanoindentation-based hardness and elastic modulus measurements, and their synergistic effects. Clustering parameters were meticulously optimized, and in conjunction with domain expert recommendations, the total number of clusters was set to three. The evaluation was grounded in established clustering performance metrics such as the Davies–Bouldin Index, Calinski–Harabasz Index, and the Silhouette score, aiming to ascertain the optimal clustering approach. Among the eight evaluated clustering algorithms, K-means, Agglomerative and FCM emerged as the most effective, while the OPTICS algorithm consistently underperformed for the considered datasets. Augmenting this study, we introduce an intuitive interface, negating the necessity for prior coding or machine learning familiarity, and offering effortless model fine-tuning, visualization, and comparison. This innovation empowers material science and engineering experts, technical staff, and instrumentalists and facilitates the selection of ideal models across varied datasets. The insights and tools presented herein not only enrich material science and engineering research but also lay a robust foundation for sophisticated and dependable analyses in subsequent studies.</p>\",\"PeriodicalId\":13604,\"journal\":{\"name\":\"Integrating Materials and Manufacturing Innovation\",\"volume\":\"31 1\",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-03-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Integrating Materials and Manufacturing Innovation\",\"FirstCategoryId\":\"88\",\"ListUrlMain\":\"https://doi.org/10.1007/s40192-024-00349-3\",\"RegionNum\":3,\"RegionCategory\":\"材料科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"ENGINEERING, MANUFACTURING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Integrating Materials and Manufacturing Innovation","FirstCategoryId":"88","ListUrlMain":"https://doi.org/10.1007/s40192-024-00349-3","RegionNum":3,"RegionCategory":"材料科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ENGINEERING, MANUFACTURING","Score":null,"Total":0}
A Comparative Study of Clustering Methods for Nanoindentation Mapping Data
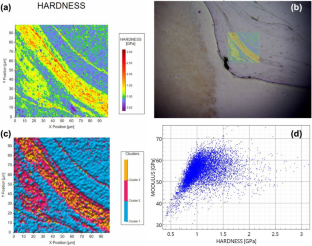
Nanoindentation testing and instrumented indentation remain regularly utilized techniques for the assessment of multi-scale mechanical characteristics from load–displacement data analysis, which is central to twenty first century material characterization. The advent of high-resolution nanoindentation-based property mapping has, however, presented challenges in data interpretation, especially when applying proper clustering methodologies to quantify and interpret data as well as draw appropriate conclusions. In this research, we utilized the scikit-learn library in Python to assess the performance of various clustering algorithms, with a focus on nanoindentation-based hardness and elastic modulus measurements, and their synergistic effects. Clustering parameters were meticulously optimized, and in conjunction with domain expert recommendations, the total number of clusters was set to three. The evaluation was grounded in established clustering performance metrics such as the Davies–Bouldin Index, Calinski–Harabasz Index, and the Silhouette score, aiming to ascertain the optimal clustering approach. Among the eight evaluated clustering algorithms, K-means, Agglomerative and FCM emerged as the most effective, while the OPTICS algorithm consistently underperformed for the considered datasets. Augmenting this study, we introduce an intuitive interface, negating the necessity for prior coding or machine learning familiarity, and offering effortless model fine-tuning, visualization, and comparison. This innovation empowers material science and engineering experts, technical staff, and instrumentalists and facilitates the selection of ideal models across varied datasets. The insights and tools presented herein not only enrich material science and engineering research but also lay a robust foundation for sophisticated and dependable analyses in subsequent studies.
期刊介绍:
The journal will publish: Research that supports building a model-based definition of materials and processes that is compatible with model-based engineering design processes and multidisciplinary design optimization; Descriptions of novel experimental or computational tools or data analysis techniques, and their application, that are to be used for ICME; Best practices in verification and validation of computational tools, sensitivity analysis, uncertainty quantification, and data management, as well as standards and protocols for software integration and exchange of data; In-depth descriptions of data, databases, and database tools; Detailed case studies on efforts, and their impact, that integrate experiment and computation to solve an enduring engineering problem in materials and manufacturing.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
