{"title":"仿人机器人导航的模仿行为强化学习:同步规划与控制","authors":"Xiaoying Wang, Tong Zhang","doi":"10.1007/s10514-024-10160-w","DOIUrl":null,"url":null,"abstract":"<div><p>Humanoid robots have strong adaptability to complex environments and possess human-like flexibility, enabling them to perform precise farming and harvesting tasks in varying depths of terrains. They serve as essential tools for agricultural intelligence. In this article, a novel method was proposed to improve the robustness of autonomous navigation for humanoid robots, which intercommunicates the data fusion of the footprint planning and control levels. In particular, a deep reinforcement learning model - Proximal Policy Optimization (PPO) that has been fine-tuned is introduced into this layer, before which heuristic trajectory was generated based on imitation learning. In the RL period, the KL divergence between the agent’s policy and imitative expert policy as a value penalty is added to the advantage function. As a proof of concept, our navigation policy is trained in a robotic simulator and then successfully applied to the physical robot <i>GTX</i> for indoor multi-mode navigation. The experimental results conclude that incorporating imitation learning imparts anthropomorphic attributes to robots and facilitates the generation of seamless footstep patterns. There is a significant improvement in ZMP trajectory in y-direction from the center by 21.56% is noticed. Additionally, this method improves dynamic locomotion stability, the body attitude angle falling between less than ± 5.5<span>\\(^\\circ \\)</span> compared to ± 48.4<span>\\(^\\circ \\)</span> with traditional algorithm. In general, navigation error is below 5 cm, which we verified in the experiments. It is thought that the outcome of the proposed framework presented in this article can provide a reference for researchers studying autonomous navigation applications of humanoid robots on uneven ground.\n</p></div>","PeriodicalId":55409,"journal":{"name":"Autonomous Robots","volume":"48 2-3","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2024-04-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Reinforcement learning with imitative behaviors for humanoid robots navigation: synchronous planning and control\",\"authors\":\"Xiaoying Wang, Tong Zhang\",\"doi\":\"10.1007/s10514-024-10160-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Humanoid robots have strong adaptability to complex environments and possess human-like flexibility, enabling them to perform precise farming and harvesting tasks in varying depths of terrains. They serve as essential tools for agricultural intelligence. In this article, a novel method was proposed to improve the robustness of autonomous navigation for humanoid robots, which intercommunicates the data fusion of the footprint planning and control levels. In particular, a deep reinforcement learning model - Proximal Policy Optimization (PPO) that has been fine-tuned is introduced into this layer, before which heuristic trajectory was generated based on imitation learning. In the RL period, the KL divergence between the agent’s policy and imitative expert policy as a value penalty is added to the advantage function. As a proof of concept, our navigation policy is trained in a robotic simulator and then successfully applied to the physical robot <i>GTX</i> for indoor multi-mode navigation. The experimental results conclude that incorporating imitation learning imparts anthropomorphic attributes to robots and facilitates the generation of seamless footstep patterns. There is a significant improvement in ZMP trajectory in y-direction from the center by 21.56% is noticed. Additionally, this method improves dynamic locomotion stability, the body attitude angle falling between less than ± 5.5<span>\\\\(^\\\\circ \\\\)</span> compared to ± 48.4<span>\\\\(^\\\\circ \\\\)</span> with traditional algorithm. In general, navigation error is below 5 cm, which we verified in the experiments. It is thought that the outcome of the proposed framework presented in this article can provide a reference for researchers studying autonomous navigation applications of humanoid robots on uneven ground.\\n</p></div>\",\"PeriodicalId\":55409,\"journal\":{\"name\":\"Autonomous Robots\",\"volume\":\"48 2-3\",\"pages\":\"\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2024-04-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Autonomous Robots\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10514-024-10160-w\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Autonomous Robots","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10514-024-10160-w","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Reinforcement learning with imitative behaviors for humanoid robots navigation: synchronous planning and control
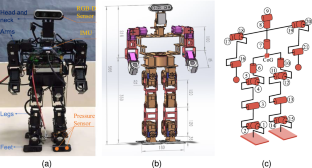
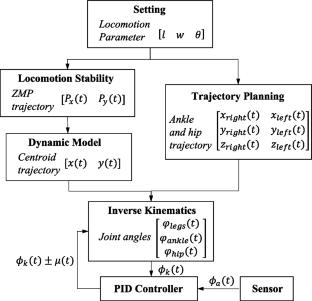
Humanoid robots have strong adaptability to complex environments and possess human-like flexibility, enabling them to perform precise farming and harvesting tasks in varying depths of terrains. They serve as essential tools for agricultural intelligence. In this article, a novel method was proposed to improve the robustness of autonomous navigation for humanoid robots, which intercommunicates the data fusion of the footprint planning and control levels. In particular, a deep reinforcement learning model - Proximal Policy Optimization (PPO) that has been fine-tuned is introduced into this layer, before which heuristic trajectory was generated based on imitation learning. In the RL period, the KL divergence between the agent’s policy and imitative expert policy as a value penalty is added to the advantage function. As a proof of concept, our navigation policy is trained in a robotic simulator and then successfully applied to the physical robot GTX for indoor multi-mode navigation. The experimental results conclude that incorporating imitation learning imparts anthropomorphic attributes to robots and facilitates the generation of seamless footstep patterns. There is a significant improvement in ZMP trajectory in y-direction from the center by 21.56% is noticed. Additionally, this method improves dynamic locomotion stability, the body attitude angle falling between less than ± 5.5\(^\circ \) compared to ± 48.4\(^\circ \) with traditional algorithm. In general, navigation error is below 5 cm, which we verified in the experiments. It is thought that the outcome of the proposed framework presented in this article can provide a reference for researchers studying autonomous navigation applications of humanoid robots on uneven ground.
期刊介绍:
Autonomous Robots reports on the theory and applications of robotic systems capable of some degree of self-sufficiency. It features papers that include performance data on actual robots in the real world. Coverage includes: control of autonomous robots · real-time vision · autonomous wheeled and tracked vehicles · legged vehicles · computational architectures for autonomous systems · distributed architectures for learning, control and adaptation · studies of autonomous robot systems · sensor fusion · theory of autonomous systems · terrain mapping and recognition · self-calibration and self-repair for robots · self-reproducing intelligent structures · genetic algorithms as models for robot development.
The focus is on the ability to move and be self-sufficient, not on whether the system is an imitation of biology. Of course, biological models for robotic systems are of major interest to the journal since living systems are prototypes for autonomous behavior.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
