{"title":"利用图形校正保护社交网络数据隐私","authors":"Amir Dehaki Toroghi, Javad Hamidzadeh","doi":"10.1007/s10115-024-02115-5","DOIUrl":null,"url":null,"abstract":"<p>Today, the rapid development of online social networks, as well as low costs, easy communication, and quick access with minimal facilities have made social networks an attractive and very influential phenomenon among people. The users of these networks tend to share their sensitive and private information with friends and acquaintances. This has caused the data of these networks to become a very important source of information about users, their interests, feelings, and activities. Analyzing this information can be very useful in predicting the behavior of users in dealing with various issues. But publishing this data for data mining can violate the privacy of users. As a result, data privacy protection of social networks has become an important and attractive research topic. In this context, various algorithms have been proposed, all of which meet privacy requirements by making changes in the information as well as the graph structure. But due to high processing costs and long execution times, these algorithms are not very appropriate for anonymizing big data. In this research, we improved the speed of data anonymization by using the number factorization technique to select and delete the best edges in the graph correction stage. We also used the chaotic krill herd algorithm to add edges, and considering the effect of all edges together on the structure of the graph, we selected edges and added them to the graph so that it preserved the graph’s utility. The evaluation results on the real-world datasets, show the efficiency of the proposed algorithm in comparison with the state-of-the-art methods to reduce the execution time and maintain the utility of the anonymous graph.</p>","PeriodicalId":54749,"journal":{"name":"Knowledge and Information Systems","volume":"28 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-04-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Protecting the privacy of social network data using graph correction\",\"authors\":\"Amir Dehaki Toroghi, Javad Hamidzadeh\",\"doi\":\"10.1007/s10115-024-02115-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Today, the rapid development of online social networks, as well as low costs, easy communication, and quick access with minimal facilities have made social networks an attractive and very influential phenomenon among people. The users of these networks tend to share their sensitive and private information with friends and acquaintances. This has caused the data of these networks to become a very important source of information about users, their interests, feelings, and activities. Analyzing this information can be very useful in predicting the behavior of users in dealing with various issues. But publishing this data for data mining can violate the privacy of users. As a result, data privacy protection of social networks has become an important and attractive research topic. In this context, various algorithms have been proposed, all of which meet privacy requirements by making changes in the information as well as the graph structure. But due to high processing costs and long execution times, these algorithms are not very appropriate for anonymizing big data. In this research, we improved the speed of data anonymization by using the number factorization technique to select and delete the best edges in the graph correction stage. We also used the chaotic krill herd algorithm to add edges, and considering the effect of all edges together on the structure of the graph, we selected edges and added them to the graph so that it preserved the graph’s utility. The evaluation results on the real-world datasets, show the efficiency of the proposed algorithm in comparison with the state-of-the-art methods to reduce the execution time and maintain the utility of the anonymous graph.</p>\",\"PeriodicalId\":54749,\"journal\":{\"name\":\"Knowledge and Information Systems\",\"volume\":\"28 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-04-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Knowledge and Information Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10115-024-02115-5\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge and Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10115-024-02115-5","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Protecting the privacy of social network data using graph correction
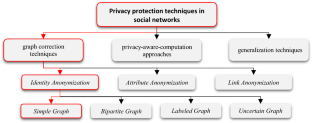
Today, the rapid development of online social networks, as well as low costs, easy communication, and quick access with minimal facilities have made social networks an attractive and very influential phenomenon among people. The users of these networks tend to share their sensitive and private information with friends and acquaintances. This has caused the data of these networks to become a very important source of information about users, their interests, feelings, and activities. Analyzing this information can be very useful in predicting the behavior of users in dealing with various issues. But publishing this data for data mining can violate the privacy of users. As a result, data privacy protection of social networks has become an important and attractive research topic. In this context, various algorithms have been proposed, all of which meet privacy requirements by making changes in the information as well as the graph structure. But due to high processing costs and long execution times, these algorithms are not very appropriate for anonymizing big data. In this research, we improved the speed of data anonymization by using the number factorization technique to select and delete the best edges in the graph correction stage. We also used the chaotic krill herd algorithm to add edges, and considering the effect of all edges together on the structure of the graph, we selected edges and added them to the graph so that it preserved the graph’s utility. The evaluation results on the real-world datasets, show the efficiency of the proposed algorithm in comparison with the state-of-the-art methods to reduce the execution time and maintain the utility of the anonymous graph.
期刊介绍:
Knowledge and Information Systems (KAIS) provides an international forum for researchers and professionals to share their knowledge and report new advances on all topics related to knowledge systems and advanced information systems. This monthly peer-reviewed archival journal publishes state-of-the-art research reports on emerging topics in KAIS, reviews of important techniques in related areas, and application papers of interest to a general readership.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
