Hongjian Gu, Wenxuan Zou, Keyang Cheng, Bin Wu, Humaira Abdul Ghafoor, Yongzhao Zhan
{"title":"通过深度复眼网络和姿势修复模块进行人员再识别","authors":"Hongjian Gu, Wenxuan Zou, Keyang Cheng, Bin Wu, Humaira Abdul Ghafoor, Yongzhao Zhan","doi":"10.1049/cvi2.12282","DOIUrl":null,"url":null,"abstract":"<p>Person re-identification is aimed at searching for specific target pedestrians from non-intersecting cameras. However, in real complex scenes, pedestrians are easily obscured, which makes the target pedestrian search task time-consuming and challenging. To address the problem of pedestrians' susceptibility to occlusion, a person re-identification via deep compound eye network (CEN) and pose repair module is proposed, which includes (1) A deep CEN based on multi-camera logical topology is proposed, which adopts graph convolution and a Gated Recurrent Unit to capture the temporal and spatial information of pedestrian walking and finally carries out pedestrian global matching through the Siamese network; (2) An integrated spatial-temporal information aggregation network is designed to facilitate pose repair. The target pedestrian features under the multi-level logic topology camera are utilised as auxiliary information to repair the occluded target pedestrian image, so as to reduce the impact of pedestrian mismatch due to pose changes; (3) A joint optimisation mechanism of CEN and pose repair network is introduced, where multi-camera logical topology inference provides auxiliary information and retrieval order for the pose repair network. The authors conducted experiments on multiple datasets, including Occluded-DukeMTMC, CUHK-SYSU, PRW, SLP, and UJS-reID. The results indicate that the authors’ method achieved significant performance across these datasets. Specifically, on the CUHK-SYSU dataset, the authors’ model achieved a top-1 accuracy of 89.1% and a mean Average Precision accuracy of 83.1% in the recognition of occluded individuals.</p>","PeriodicalId":56304,"journal":{"name":"IET Computer Vision","volume":"18 6","pages":"826-841"},"PeriodicalIF":1.5000,"publicationDate":"2024-04-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12282","citationCount":"0","resultStr":"{\"title\":\"Person re-identification via deep compound eye network and pose repair module\",\"authors\":\"Hongjian Gu, Wenxuan Zou, Keyang Cheng, Bin Wu, Humaira Abdul Ghafoor, Yongzhao Zhan\",\"doi\":\"10.1049/cvi2.12282\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Person re-identification is aimed at searching for specific target pedestrians from non-intersecting cameras. However, in real complex scenes, pedestrians are easily obscured, which makes the target pedestrian search task time-consuming and challenging. To address the problem of pedestrians' susceptibility to occlusion, a person re-identification via deep compound eye network (CEN) and pose repair module is proposed, which includes (1) A deep CEN based on multi-camera logical topology is proposed, which adopts graph convolution and a Gated Recurrent Unit to capture the temporal and spatial information of pedestrian walking and finally carries out pedestrian global matching through the Siamese network; (2) An integrated spatial-temporal information aggregation network is designed to facilitate pose repair. The target pedestrian features under the multi-level logic topology camera are utilised as auxiliary information to repair the occluded target pedestrian image, so as to reduce the impact of pedestrian mismatch due to pose changes; (3) A joint optimisation mechanism of CEN and pose repair network is introduced, where multi-camera logical topology inference provides auxiliary information and retrieval order for the pose repair network. The authors conducted experiments on multiple datasets, including Occluded-DukeMTMC, CUHK-SYSU, PRW, SLP, and UJS-reID. The results indicate that the authors’ method achieved significant performance across these datasets. Specifically, on the CUHK-SYSU dataset, the authors’ model achieved a top-1 accuracy of 89.1% and a mean Average Precision accuracy of 83.1% in the recognition of occluded individuals.</p>\",\"PeriodicalId\":56304,\"journal\":{\"name\":\"IET Computer Vision\",\"volume\":\"18 6\",\"pages\":\"826-841\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2024-04-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12282\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Computer Vision\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12282\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12282","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Person re-identification via deep compound eye network and pose repair module
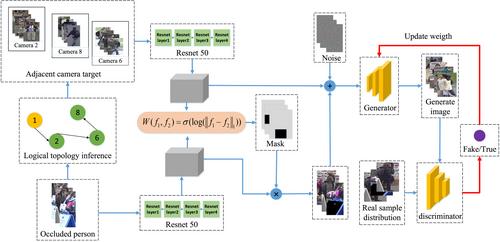
Person re-identification is aimed at searching for specific target pedestrians from non-intersecting cameras. However, in real complex scenes, pedestrians are easily obscured, which makes the target pedestrian search task time-consuming and challenging. To address the problem of pedestrians' susceptibility to occlusion, a person re-identification via deep compound eye network (CEN) and pose repair module is proposed, which includes (1) A deep CEN based on multi-camera logical topology is proposed, which adopts graph convolution and a Gated Recurrent Unit to capture the temporal and spatial information of pedestrian walking and finally carries out pedestrian global matching through the Siamese network; (2) An integrated spatial-temporal information aggregation network is designed to facilitate pose repair. The target pedestrian features under the multi-level logic topology camera are utilised as auxiliary information to repair the occluded target pedestrian image, so as to reduce the impact of pedestrian mismatch due to pose changes; (3) A joint optimisation mechanism of CEN and pose repair network is introduced, where multi-camera logical topology inference provides auxiliary information and retrieval order for the pose repair network. The authors conducted experiments on multiple datasets, including Occluded-DukeMTMC, CUHK-SYSU, PRW, SLP, and UJS-reID. The results indicate that the authors’ method achieved significant performance across these datasets. Specifically, on the CUHK-SYSU dataset, the authors’ model achieved a top-1 accuracy of 89.1% and a mean Average Precision accuracy of 83.1% in the recognition of occluded individuals.
期刊介绍:
IET Computer Vision seeks original research papers in a wide range of areas of computer vision. The vision of the journal is to publish the highest quality research work that is relevant and topical to the field, but not forgetting those works that aim to introduce new horizons and set the agenda for future avenues of research in computer vision.
IET Computer Vision welcomes submissions on the following topics:
Biologically and perceptually motivated approaches to low level vision (feature detection, etc.);
Perceptual grouping and organisation
Representation, analysis and matching of 2D and 3D shape
Shape-from-X
Object recognition
Image understanding
Learning with visual inputs
Motion analysis and object tracking
Multiview scene analysis
Cognitive approaches in low, mid and high level vision
Control in visual systems
Colour, reflectance and light
Statistical and probabilistic models
Face and gesture
Surveillance
Biometrics and security
Robotics
Vehicle guidance
Automatic model aquisition
Medical image analysis and understanding
Aerial scene analysis and remote sensing
Deep learning models in computer vision
Both methodological and applications orientated papers are welcome.
Manuscripts submitted are expected to include a detailed and analytical review of the literature and state-of-the-art exposition of the original proposed research and its methodology, its thorough experimental evaluation, and last but not least, comparative evaluation against relevant and state-of-the-art methods. Submissions not abiding by these minimum requirements may be returned to authors without being sent to review.
Special Issues Current Call for Papers:
Computer Vision for Smart Cameras and Camera Networks - https://digital-library.theiet.org/files/IET_CVI_SC.pdf
Computer Vision for the Creative Industries - https://digital-library.theiet.org/files/IET_CVI_CVCI.pdf



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
