{"title":"可解释人工智能中的可解释表征:从理论到实践","authors":"Kacper Sokol, Peter Flach","doi":"10.1007/s10618-024-01010-5","DOIUrl":null,"url":null,"abstract":"<p>Interpretable representations are the backbone of many explainers that target black-box predictive systems based on artificial intelligence and machine learning algorithms. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanatory insights. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, tweaking which allows to target a particular audience and use case. However, many explainers built upon interpretable representations overlook their merit and fall back on default solutions that often carry implicit assumptions, thereby degrading the explanatory power and reliability of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We demonstrate how they are operationalised for tabular, image and text data; discuss their assumptions, strengths and weaknesses; identify their core building blocks; and scrutinise their configuration and parameterisation. In particular, this in-depth analysis allows us to pinpoint their explanatory properties, desiderata and scope for (malicious) manipulation in the context of tabular data where a linear model is used to quantify the influence of interpretable concepts on a black-box prediction. Our findings lead to a range of recommendations for designing trustworthy interpretable representations; specifically, the benefits of class-aware (supervised) discretisation of tabular data, e.g., with decision trees, and sensitivity of image interpretable representations to segmentation granularity and occlusion colour.</p>","PeriodicalId":55183,"journal":{"name":"Data Mining and Knowledge Discovery","volume":"50 1","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2024-04-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Interpretable representations in explainable AI: from theory to practice\",\"authors\":\"Kacper Sokol, Peter Flach\",\"doi\":\"10.1007/s10618-024-01010-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Interpretable representations are the backbone of many explainers that target black-box predictive systems based on artificial intelligence and machine learning algorithms. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanatory insights. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, tweaking which allows to target a particular audience and use case. However, many explainers built upon interpretable representations overlook their merit and fall back on default solutions that often carry implicit assumptions, thereby degrading the explanatory power and reliability of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We demonstrate how they are operationalised for tabular, image and text data; discuss their assumptions, strengths and weaknesses; identify their core building blocks; and scrutinise their configuration and parameterisation. In particular, this in-depth analysis allows us to pinpoint their explanatory properties, desiderata and scope for (malicious) manipulation in the context of tabular data where a linear model is used to quantify the influence of interpretable concepts on a black-box prediction. Our findings lead to a range of recommendations for designing trustworthy interpretable representations; specifically, the benefits of class-aware (supervised) discretisation of tabular data, e.g., with decision trees, and sensitivity of image interpretable representations to segmentation granularity and occlusion colour.</p>\",\"PeriodicalId\":55183,\"journal\":{\"name\":\"Data Mining and Knowledge Discovery\",\"volume\":\"50 1\",\"pages\":\"\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2024-04-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Data Mining and Knowledge Discovery\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10618-024-01010-5\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data Mining and Knowledge Discovery","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10618-024-01010-5","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Interpretable representations in explainable AI: from theory to practice
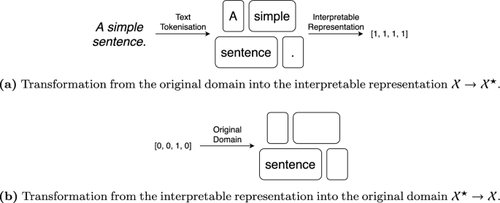
Interpretable representations are the backbone of many explainers that target black-box predictive systems based on artificial intelligence and machine learning algorithms. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanatory insights. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, tweaking which allows to target a particular audience and use case. However, many explainers built upon interpretable representations overlook their merit and fall back on default solutions that often carry implicit assumptions, thereby degrading the explanatory power and reliability of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We demonstrate how they are operationalised for tabular, image and text data; discuss their assumptions, strengths and weaknesses; identify their core building blocks; and scrutinise their configuration and parameterisation. In particular, this in-depth analysis allows us to pinpoint their explanatory properties, desiderata and scope for (malicious) manipulation in the context of tabular data where a linear model is used to quantify the influence of interpretable concepts on a black-box prediction. Our findings lead to a range of recommendations for designing trustworthy interpretable representations; specifically, the benefits of class-aware (supervised) discretisation of tabular data, e.g., with decision trees, and sensitivity of image interpretable representations to segmentation granularity and occlusion colour.
期刊介绍:
Advances in data gathering, storage, and distribution have created a need for computational tools and techniques to aid in data analysis. Data Mining and Knowledge Discovery in Databases (KDD) is a rapidly growing area of research and application that builds on techniques and theories from many fields, including statistics, databases, pattern recognition and learning, data visualization, uncertainty modelling, data warehousing and OLAP, optimization, and high performance computing.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
