Kristian Gonzalez Barman, Sascha Caron, Tom Claassen, Henk de Regt
{"title":"为人类和机器的科学理解建立基准","authors":"Kristian Gonzalez Barman, Sascha Caron, Tom Claassen, Henk de Regt","doi":"10.1007/s11023-024-09657-1","DOIUrl":null,"url":null,"abstract":"<p>Scientific understanding is a fundamental goal of science. However, there is currently no good way to measure the scientific understanding of agents, whether these be humans or Artificial Intelligence systems. Without a clear benchmark, it is challenging to evaluate and compare different levels of scientific understanding. In this paper, we propose a framework to create a benchmark for scientific understanding, utilizing tools from philosophy of science. We adopt a behavioral conception of understanding, according to which genuine understanding should be recognized as an ability to perform certain tasks. We extend this notion of scientific understanding by considering a set of questions that gauge different levels of scientific understanding, covering information retrieval, the capability to arrange information to produce an explanation, and the ability to infer how things would be different under different circumstances. We suggest building a Scientific Understanding Benchmark (SUB), formed by a set of these tests, allowing for the evaluation and comparison of scientific understanding. Benchmarking plays a crucial role in establishing trust, ensuring quality control, and providing a basis for performance evaluation. By aligning machine and human scientific understanding we can improve their utility, ultimately advancing scientific understanding and helping to discover new insights within machines.</p>","PeriodicalId":51133,"journal":{"name":"Minds and Machines","volume":"11 1","pages":""},"PeriodicalIF":3.4000,"publicationDate":"2024-04-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Towards a Benchmark for Scientific Understanding in Humans and Machines\",\"authors\":\"Kristian Gonzalez Barman, Sascha Caron, Tom Claassen, Henk de Regt\",\"doi\":\"10.1007/s11023-024-09657-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Scientific understanding is a fundamental goal of science. However, there is currently no good way to measure the scientific understanding of agents, whether these be humans or Artificial Intelligence systems. Without a clear benchmark, it is challenging to evaluate and compare different levels of scientific understanding. In this paper, we propose a framework to create a benchmark for scientific understanding, utilizing tools from philosophy of science. We adopt a behavioral conception of understanding, according to which genuine understanding should be recognized as an ability to perform certain tasks. We extend this notion of scientific understanding by considering a set of questions that gauge different levels of scientific understanding, covering information retrieval, the capability to arrange information to produce an explanation, and the ability to infer how things would be different under different circumstances. We suggest building a Scientific Understanding Benchmark (SUB), formed by a set of these tests, allowing for the evaluation and comparison of scientific understanding. Benchmarking plays a crucial role in establishing trust, ensuring quality control, and providing a basis for performance evaluation. By aligning machine and human scientific understanding we can improve their utility, ultimately advancing scientific understanding and helping to discover new insights within machines.</p>\",\"PeriodicalId\":51133,\"journal\":{\"name\":\"Minds and Machines\",\"volume\":\"11 1\",\"pages\":\"\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2024-04-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Minds and Machines\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11023-024-09657-1\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Minds and Machines","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11023-024-09657-1","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Towards a Benchmark for Scientific Understanding in Humans and Machines
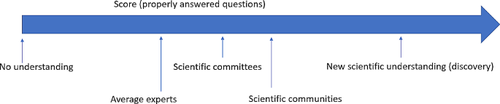
Scientific understanding is a fundamental goal of science. However, there is currently no good way to measure the scientific understanding of agents, whether these be humans or Artificial Intelligence systems. Without a clear benchmark, it is challenging to evaluate and compare different levels of scientific understanding. In this paper, we propose a framework to create a benchmark for scientific understanding, utilizing tools from philosophy of science. We adopt a behavioral conception of understanding, according to which genuine understanding should be recognized as an ability to perform certain tasks. We extend this notion of scientific understanding by considering a set of questions that gauge different levels of scientific understanding, covering information retrieval, the capability to arrange information to produce an explanation, and the ability to infer how things would be different under different circumstances. We suggest building a Scientific Understanding Benchmark (SUB), formed by a set of these tests, allowing for the evaluation and comparison of scientific understanding. Benchmarking plays a crucial role in establishing trust, ensuring quality control, and providing a basis for performance evaluation. By aligning machine and human scientific understanding we can improve their utility, ultimately advancing scientific understanding and helping to discover new insights within machines.
期刊介绍:
Minds and Machines, affiliated with the Society for Machines and Mentality, serves as a platform for fostering critical dialogue between the AI and philosophical communities. With a focus on problems of shared interest, the journal actively encourages discussions on the philosophical aspects of computer science.
Offering a global forum, Minds and Machines provides a space to debate and explore important and contentious issues within its editorial focus. The journal presents special editions dedicated to specific topics, invites critical responses to previously published works, and features review essays addressing current problem scenarios.
By facilitating a diverse range of perspectives, Minds and Machines encourages a reevaluation of the status quo and the development of new insights. Through this collaborative approach, the journal aims to bridge the gap between AI and philosophy, fostering a tradition of critique and ensuring these fields remain connected and relevant.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
