Saqib ul Sabha, Assif Assad, Sadaf Shafi, Nusrat Mohi Ud Din, Rayees Ahmad Dar, Muzafar Rasool Bhat
{"title":"Imbalcbl:利用小型不平衡数据集应对深度学习挑战","authors":"Saqib ul Sabha, Assif Assad, Sadaf Shafi, Nusrat Mohi Ud Din, Rayees Ahmad Dar, Muzafar Rasool Bhat","doi":"10.1007/s13198-024-02346-3","DOIUrl":null,"url":null,"abstract":"<p>Deep learning, while transformative for computer vision, frequently falters when confronted with small and imbalanced datasets. Despite substantial progress in this domain, prevailing models often underachieve under these constraints. Addressing this, we introduce an innovative contrast-based learning strategy for small and imbalanced data that significantly bolsters the proficiency of deep learning architectures on these challenging datasets. By ingeniously concatenating training images, the effective training dataset expands from <i>n</i> to <span>\\(n^2\\)</span>, affording richer data for model training, even when <i>n</i> is very small. Remarkably, our solution remains indifferent to specific loss functions or network architectures, endorsing its adaptability for diverse classification scenarios. Rigorously benchmarked against four benchmark datasets, our approach was juxtaposed with state-of-the-art oversampling paradigms. The empirical evidence underscores our method’s superior efficacy, outshining contemporaries across metrics like Balanced accuracy, F1 score, and Geometric mean. Noteworthy increments include 7–16% on the Covid-19 dataset, 4–20% for Honey bees, 1–6% on CIFAR-10, and 1–9% on FashionMNIST. In essence, our proposed method offers a potent remedy for the perennial issues stemming from scanty and skewed data in deep learning.</p>","PeriodicalId":14463,"journal":{"name":"International Journal of System Assurance Engineering and Management","volume":"88 1","pages":""},"PeriodicalIF":1.4000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Imbalcbl: addressing deep learning challenges with small and imbalanced datasets\",\"authors\":\"Saqib ul Sabha, Assif Assad, Sadaf Shafi, Nusrat Mohi Ud Din, Rayees Ahmad Dar, Muzafar Rasool Bhat\",\"doi\":\"10.1007/s13198-024-02346-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Deep learning, while transformative for computer vision, frequently falters when confronted with small and imbalanced datasets. Despite substantial progress in this domain, prevailing models often underachieve under these constraints. Addressing this, we introduce an innovative contrast-based learning strategy for small and imbalanced data that significantly bolsters the proficiency of deep learning architectures on these challenging datasets. By ingeniously concatenating training images, the effective training dataset expands from <i>n</i> to <span>\\\\(n^2\\\\)</span>, affording richer data for model training, even when <i>n</i> is very small. Remarkably, our solution remains indifferent to specific loss functions or network architectures, endorsing its adaptability for diverse classification scenarios. Rigorously benchmarked against four benchmark datasets, our approach was juxtaposed with state-of-the-art oversampling paradigms. The empirical evidence underscores our method’s superior efficacy, outshining contemporaries across metrics like Balanced accuracy, F1 score, and Geometric mean. Noteworthy increments include 7–16% on the Covid-19 dataset, 4–20% for Honey bees, 1–6% on CIFAR-10, and 1–9% on FashionMNIST. In essence, our proposed method offers a potent remedy for the perennial issues stemming from scanty and skewed data in deep learning.</p>\",\"PeriodicalId\":14463,\"journal\":{\"name\":\"International Journal of System Assurance Engineering and Management\",\"volume\":\"88 1\",\"pages\":\"\"},\"PeriodicalIF\":1.4000,\"publicationDate\":\"2024-05-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of System Assurance Engineering and Management\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s13198-024-02346-3\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ENGINEERING, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of System Assurance Engineering and Management","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s13198-024-02346-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENGINEERING, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
摘要
深度学习虽然对计算机视觉具有变革意义,但在面对小型和不平衡数据集时往往会出现问题。尽管在这一领域取得了长足进步,但现有模型在这些限制条件下往往表现不佳。为了解决这个问题,我们针对小数据和不平衡数据引入了一种基于对比度的创新学习策略,大大提高了深度学习架构在这些具有挑战性的数据集上的能力。通过巧妙地连接训练图像,有效的训练数据集从 n 扩展到 \(n^2\),即使 n 非常小,也能为模型训练提供更丰富的数据。值得注意的是,我们的解决方案对特定的损失函数或网络架构无动于衷,这证明了它对不同分类场景的适应性。根据四个基准数据集对我们的方法进行了严格的基准测试,并将其与最先进的超采样范例进行了对比。经验证明,我们的方法具有卓越的功效,在平衡准确率、F1 分数和几何平均数等指标上都优于同时代的方法。值得注意的是,Covid-19 数据集的准确率提高了 7-16%,蜜蜂的准确率提高了 4-20%,CIFAR-10 的准确率提高了 1-6%,FashionMNIST 的准确率提高了 1-9%。从本质上讲,我们提出的方法为深度学习中因数据稀少和偏斜而长期存在的问题提供了有效的解决方案。
Imbalcbl: addressing deep learning challenges with small and imbalanced datasets
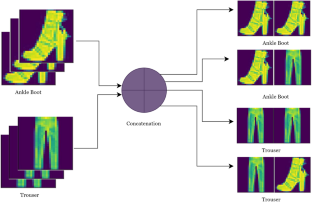
Deep learning, while transformative for computer vision, frequently falters when confronted with small and imbalanced datasets. Despite substantial progress in this domain, prevailing models often underachieve under these constraints. Addressing this, we introduce an innovative contrast-based learning strategy for small and imbalanced data that significantly bolsters the proficiency of deep learning architectures on these challenging datasets. By ingeniously concatenating training images, the effective training dataset expands from n to \(n^2\), affording richer data for model training, even when n is very small. Remarkably, our solution remains indifferent to specific loss functions or network architectures, endorsing its adaptability for diverse classification scenarios. Rigorously benchmarked against four benchmark datasets, our approach was juxtaposed with state-of-the-art oversampling paradigms. The empirical evidence underscores our method’s superior efficacy, outshining contemporaries across metrics like Balanced accuracy, F1 score, and Geometric mean. Noteworthy increments include 7–16% on the Covid-19 dataset, 4–20% for Honey bees, 1–6% on CIFAR-10, and 1–9% on FashionMNIST. In essence, our proposed method offers a potent remedy for the perennial issues stemming from scanty and skewed data in deep learning.
期刊介绍:
This Journal is established with a view to cater to increased awareness for high quality research in the seamless integration of heterogeneous technologies to formulate bankable solutions to the emergent complex engineering problems.
Assurance engineering could be thought of as relating to the provision of higher confidence in the reliable and secure implementation of a system’s critical characteristic features through the espousal of a holistic approach by using a wide variety of cross disciplinary tools and techniques. Successful realization of sustainable and dependable products, systems and services involves an extensive adoption of Reliability, Quality, Safety and Risk related procedures for achieving high assurancelevels of performance; also pivotal are the management issues related to risk and uncertainty that govern the practical constraints encountered in their deployment. It is our intention to provide a platform for the modeling and analysis of large engineering systems, among the other aforementioned allied goals of systems assurance engineering, leading to the enforcement of performance enhancement measures. Achieving a fine balance between theory and practice is the primary focus. The Journal only publishes high quality papers that have passed the rigorous peer review procedure of an archival scientific Journal. The aim is an increasing number of submissions, wide circulation and a high impact factor.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
