{"title":"利用注意力编码器和 LSTM 融合多种嵌入式编码,加强情感分析","authors":"Jitendra Soni, Kirti Mathur","doi":"10.1007/s10115-024-02102-w","DOIUrl":null,"url":null,"abstract":"<p>Different embeddings capture various linguistic aspects, such as syntactic, semantic, and contextual information. Taking into account the diverse linguistic facets, we propose a novel hybrid model. This model hinges on the amalgamation of multiple embeddings through an attention encoder, subsequently channeled into an LSTM framework for sentiment classification. Our approach entails the fusion of Paragraph2vec, ELMo, and BERT embeddings to extract contextual information, while FastText is adeptly employed to capture syntactic characteristics. Subsequently, these embeddings were fused with the embeddings obtained from the attention encoder which forms the final embeddings. LSTM model is used for predicting the final classification. We conducted experiments utilizing both the Twitter Sentiment140 and Twitter US Airline Sentiment datasets. Our fusion model’s performance was evaluated and compared against established models such as LSTM, Bi-directional LSTM, BERT and Att-Coder. The test results clearly demonstrate that our approach surpasses the baseline models in terms of performance.</p>","PeriodicalId":54749,"journal":{"name":"Knowledge and Information Systems","volume":"18 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-04-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhancing sentiment analysis via fusion of multiple embeddings using attention encoder with LSTM\",\"authors\":\"Jitendra Soni, Kirti Mathur\",\"doi\":\"10.1007/s10115-024-02102-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Different embeddings capture various linguistic aspects, such as syntactic, semantic, and contextual information. Taking into account the diverse linguistic facets, we propose a novel hybrid model. This model hinges on the amalgamation of multiple embeddings through an attention encoder, subsequently channeled into an LSTM framework for sentiment classification. Our approach entails the fusion of Paragraph2vec, ELMo, and BERT embeddings to extract contextual information, while FastText is adeptly employed to capture syntactic characteristics. Subsequently, these embeddings were fused with the embeddings obtained from the attention encoder which forms the final embeddings. LSTM model is used for predicting the final classification. We conducted experiments utilizing both the Twitter Sentiment140 and Twitter US Airline Sentiment datasets. Our fusion model’s performance was evaluated and compared against established models such as LSTM, Bi-directional LSTM, BERT and Att-Coder. The test results clearly demonstrate that our approach surpasses the baseline models in terms of performance.</p>\",\"PeriodicalId\":54749,\"journal\":{\"name\":\"Knowledge and Information Systems\",\"volume\":\"18 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-04-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Knowledge and Information Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10115-024-02102-w\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge and Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10115-024-02102-w","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Enhancing sentiment analysis via fusion of multiple embeddings using attention encoder with LSTM
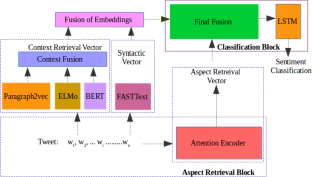
Different embeddings capture various linguistic aspects, such as syntactic, semantic, and contextual information. Taking into account the diverse linguistic facets, we propose a novel hybrid model. This model hinges on the amalgamation of multiple embeddings through an attention encoder, subsequently channeled into an LSTM framework for sentiment classification. Our approach entails the fusion of Paragraph2vec, ELMo, and BERT embeddings to extract contextual information, while FastText is adeptly employed to capture syntactic characteristics. Subsequently, these embeddings were fused with the embeddings obtained from the attention encoder which forms the final embeddings. LSTM model is used for predicting the final classification. We conducted experiments utilizing both the Twitter Sentiment140 and Twitter US Airline Sentiment datasets. Our fusion model’s performance was evaluated and compared against established models such as LSTM, Bi-directional LSTM, BERT and Att-Coder. The test results clearly demonstrate that our approach surpasses the baseline models in terms of performance.
期刊介绍:
Knowledge and Information Systems (KAIS) provides an international forum for researchers and professionals to share their knowledge and report new advances on all topics related to knowledge systems and advanced information systems. This monthly peer-reviewed archival journal publishes state-of-the-art research reports on emerging topics in KAIS, reviews of important techniques in related areas, and application papers of interest to a general readership.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
