{"title":"参数可识别性方法的导航:模型开发工作流程建议。","authors":"Martijn van Noort, Martijn Ruppert, Joost DeJongh, Eleonora Marostica, Rolien Bosch, Emir Mešić, Nelleke Snelder","doi":"10.1002/psp4.13148","DOIUrl":null,"url":null,"abstract":"<p>In pharmacometric modeling, it is often important to know whether the data is sufficiently rich to identify the parameters of a proposed model. While it may be possible to assess this based on the results of a model fit, it is often difficult to disentangle identifiability issues from other model fitting and numerical problems. Furthermore, it can be of value to ascertain identifiability beforehand. This paper compares four methods for parameter identifiability, namely Differential Algebra for Identifiability of SYstems (DAISY), the sensitivity matrix method (SMM), Aliasing, and the Fisher information matrix method (FIMM). We discuss the characteristics of the methods and apply them to a set of applications, consisting of frequently used PK model structures, with suitable dosing regimens and sampling times. These applications were selected to validate the methods and demonstrate their usefulness. While traditional identifiability analysis provides a categorical result [<i>PLoS One</i>, 6, 2011, e27755; <i>CPT Pharmacometrics Syst Pharmacol</i>, 8, 2019, 259; <i>Bioinformatics</i>, 30, 2014, 1440], we argue that in practice a continuous scale better reflects the limitations on the data and is more informative. The methods were generally consistent in their evaluation of the applications. The Fisher information matrix method seemed to provide the most consistent answers. All methods provided information on the parameters that were unidentifiable. Some of the results were unexpected, indicating identifiability issues where none were foreseen, but could be explained upon further analysis. This illustrated the usefulness of identifiability assessment.</p>","PeriodicalId":10774,"journal":{"name":"CPT: Pharmacometrics & Systems Pharmacology","volume":"13 7","pages":"1170-1179"},"PeriodicalIF":3.0000,"publicationDate":"2024-05-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/psp4.13148","citationCount":"0","resultStr":"{\"title\":\"Navigating the landscape of parameter identifiability methods: A workflow recommendation for model development\",\"authors\":\"Martijn van Noort, Martijn Ruppert, Joost DeJongh, Eleonora Marostica, Rolien Bosch, Emir Mešić, Nelleke Snelder\",\"doi\":\"10.1002/psp4.13148\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>In pharmacometric modeling, it is often important to know whether the data is sufficiently rich to identify the parameters of a proposed model. While it may be possible to assess this based on the results of a model fit, it is often difficult to disentangle identifiability issues from other model fitting and numerical problems. Furthermore, it can be of value to ascertain identifiability beforehand. This paper compares four methods for parameter identifiability, namely Differential Algebra for Identifiability of SYstems (DAISY), the sensitivity matrix method (SMM), Aliasing, and the Fisher information matrix method (FIMM). We discuss the characteristics of the methods and apply them to a set of applications, consisting of frequently used PK model structures, with suitable dosing regimens and sampling times. These applications were selected to validate the methods and demonstrate their usefulness. While traditional identifiability analysis provides a categorical result [<i>PLoS One</i>, 6, 2011, e27755; <i>CPT Pharmacometrics Syst Pharmacol</i>, 8, 2019, 259; <i>Bioinformatics</i>, 30, 2014, 1440], we argue that in practice a continuous scale better reflects the limitations on the data and is more informative. The methods were generally consistent in their evaluation of the applications. The Fisher information matrix method seemed to provide the most consistent answers. All methods provided information on the parameters that were unidentifiable. Some of the results were unexpected, indicating identifiability issues where none were foreseen, but could be explained upon further analysis. This illustrated the usefulness of identifiability assessment.</p>\",\"PeriodicalId\":10774,\"journal\":{\"name\":\"CPT: Pharmacometrics & Systems Pharmacology\",\"volume\":\"13 7\",\"pages\":\"1170-1179\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-05-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/psp4.13148\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"CPT: Pharmacometrics & Systems Pharmacology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://ascpt.onlinelibrary.wiley.com/doi/10.1002/psp4.13148\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"PHARMACOLOGY & PHARMACY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"CPT: Pharmacometrics & Systems Pharmacology","FirstCategoryId":"3","ListUrlMain":"https://ascpt.onlinelibrary.wiley.com/doi/10.1002/psp4.13148","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
Navigating the landscape of parameter identifiability methods: A workflow recommendation for model development
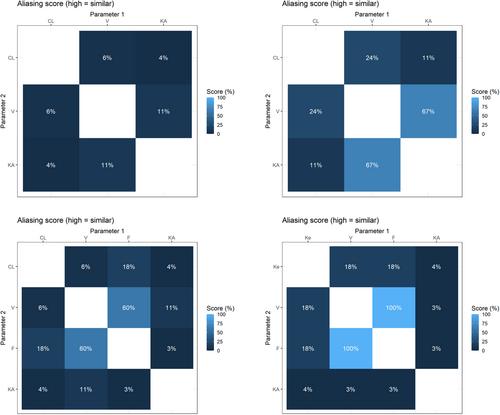
In pharmacometric modeling, it is often important to know whether the data is sufficiently rich to identify the parameters of a proposed model. While it may be possible to assess this based on the results of a model fit, it is often difficult to disentangle identifiability issues from other model fitting and numerical problems. Furthermore, it can be of value to ascertain identifiability beforehand. This paper compares four methods for parameter identifiability, namely Differential Algebra for Identifiability of SYstems (DAISY), the sensitivity matrix method (SMM), Aliasing, and the Fisher information matrix method (FIMM). We discuss the characteristics of the methods and apply them to a set of applications, consisting of frequently used PK model structures, with suitable dosing regimens and sampling times. These applications were selected to validate the methods and demonstrate their usefulness. While traditional identifiability analysis provides a categorical result [PLoS One, 6, 2011, e27755; CPT Pharmacometrics Syst Pharmacol, 8, 2019, 259; Bioinformatics, 30, 2014, 1440], we argue that in practice a continuous scale better reflects the limitations on the data and is more informative. The methods were generally consistent in their evaluation of the applications. The Fisher information matrix method seemed to provide the most consistent answers. All methods provided information on the parameters that were unidentifiable. Some of the results were unexpected, indicating identifiability issues where none were foreseen, but could be explained upon further analysis. This illustrated the usefulness of identifiability assessment.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
