James W. A. Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, Michael S. A. Graziano, Cristina Becchio
{"title":"测试大型语言模型和人类的思维理论。","authors":"James W. A. Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, Michael S. A. Graziano, Cristina Becchio","doi":"10.1038/s41562-024-01882-z","DOIUrl":null,"url":null,"abstract":"At the core of what defines us as humans is the concept of theory of mind: the ability to track other people’s mental states. The recent development of large language models (LLMs) such as ChatGPT has led to intense debate about the possibility that these models exhibit behaviour that is indistinguishable from human behaviour in theory of mind tasks. Here we compare human and LLM performance on a comprehensive battery of measurements that aim to measure different theory of mind abilities, from understanding false beliefs to interpreting indirect requests and recognizing irony and faux pas. We tested two families of LLMs (GPT and LLaMA2) repeatedly against these measures and compared their performance with those from a sample of 1,907 human participants. Across the battery of theory of mind tests, we found that GPT-4 models performed at, or even sometimes above, human levels at identifying indirect requests, false beliefs and misdirection, but struggled with detecting faux pas. Faux pas, however, was the only test where LLaMA2 outperformed humans. Follow-up manipulations of the belief likelihood revealed that the superiority of LLaMA2 was illusory, possibly reflecting a bias towards attributing ignorance. By contrast, the poor performance of GPT originated from a hyperconservative approach towards committing to conclusions rather than from a genuine failure of inference. These findings not only demonstrate that LLMs exhibit behaviour that is consistent with the outputs of mentalistic inference in humans but also highlight the importance of systematic testing to ensure a non-superficial comparison between human and artificial intelligences. Testing two families of large language models (LLMs) (GPT and LLaMA2) on a battery of measurements spanning different theory of mind abilities, Strachan et al. find that the performance of LLMs can mirror that of humans on most of these tasks. The authors explored potential reasons for this.","PeriodicalId":19074,"journal":{"name":"Nature Human Behaviour","volume":"8 7","pages":"1285-1295"},"PeriodicalIF":15.9000,"publicationDate":"2024-05-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11272575/pdf/","citationCount":"0","resultStr":"{\"title\":\"Testing theory of mind in large language models and humans\",\"authors\":\"James W. A. Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, Michael S. A. Graziano, Cristina Becchio\",\"doi\":\"10.1038/s41562-024-01882-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"At the core of what defines us as humans is the concept of theory of mind: the ability to track other people’s mental states. The recent development of large language models (LLMs) such as ChatGPT has led to intense debate about the possibility that these models exhibit behaviour that is indistinguishable from human behaviour in theory of mind tasks. Here we compare human and LLM performance on a comprehensive battery of measurements that aim to measure different theory of mind abilities, from understanding false beliefs to interpreting indirect requests and recognizing irony and faux pas. We tested two families of LLMs (GPT and LLaMA2) repeatedly against these measures and compared their performance with those from a sample of 1,907 human participants. Across the battery of theory of mind tests, we found that GPT-4 models performed at, or even sometimes above, human levels at identifying indirect requests, false beliefs and misdirection, but struggled with detecting faux pas. Faux pas, however, was the only test where LLaMA2 outperformed humans. Follow-up manipulations of the belief likelihood revealed that the superiority of LLaMA2 was illusory, possibly reflecting a bias towards attributing ignorance. By contrast, the poor performance of GPT originated from a hyperconservative approach towards committing to conclusions rather than from a genuine failure of inference. These findings not only demonstrate that LLMs exhibit behaviour that is consistent with the outputs of mentalistic inference in humans but also highlight the importance of systematic testing to ensure a non-superficial comparison between human and artificial intelligences. Testing two families of large language models (LLMs) (GPT and LLaMA2) on a battery of measurements spanning different theory of mind abilities, Strachan et al. find that the performance of LLMs can mirror that of humans on most of these tasks. The authors explored potential reasons for this.\",\"PeriodicalId\":19074,\"journal\":{\"name\":\"Nature Human Behaviour\",\"volume\":\"8 7\",\"pages\":\"1285-1295\"},\"PeriodicalIF\":15.9000,\"publicationDate\":\"2024-05-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11272575/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Human Behaviour\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://www.nature.com/articles/s41562-024-01882-z\",\"RegionNum\":1,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Human Behaviour","FirstCategoryId":"102","ListUrlMain":"https://www.nature.com/articles/s41562-024-01882-z","RegionNum":1,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Testing theory of mind in large language models and humans
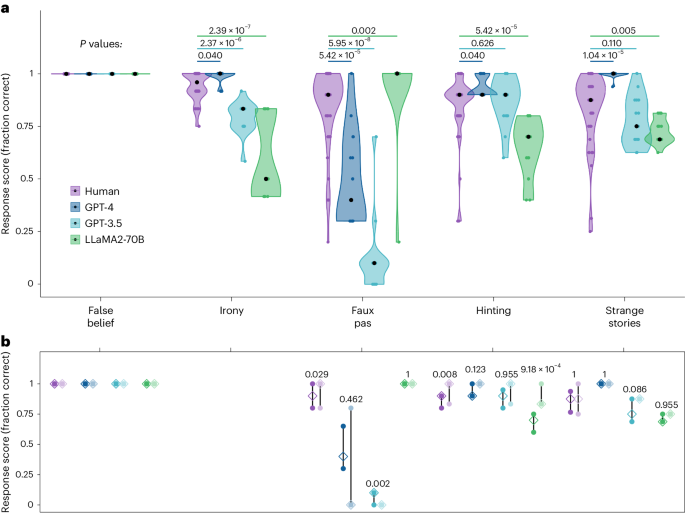
At the core of what defines us as humans is the concept of theory of mind: the ability to track other people’s mental states. The recent development of large language models (LLMs) such as ChatGPT has led to intense debate about the possibility that these models exhibit behaviour that is indistinguishable from human behaviour in theory of mind tasks. Here we compare human and LLM performance on a comprehensive battery of measurements that aim to measure different theory of mind abilities, from understanding false beliefs to interpreting indirect requests and recognizing irony and faux pas. We tested two families of LLMs (GPT and LLaMA2) repeatedly against these measures and compared their performance with those from a sample of 1,907 human participants. Across the battery of theory of mind tests, we found that GPT-4 models performed at, or even sometimes above, human levels at identifying indirect requests, false beliefs and misdirection, but struggled with detecting faux pas. Faux pas, however, was the only test where LLaMA2 outperformed humans. Follow-up manipulations of the belief likelihood revealed that the superiority of LLaMA2 was illusory, possibly reflecting a bias towards attributing ignorance. By contrast, the poor performance of GPT originated from a hyperconservative approach towards committing to conclusions rather than from a genuine failure of inference. These findings not only demonstrate that LLMs exhibit behaviour that is consistent with the outputs of mentalistic inference in humans but also highlight the importance of systematic testing to ensure a non-superficial comparison between human and artificial intelligences. Testing two families of large language models (LLMs) (GPT and LLaMA2) on a battery of measurements spanning different theory of mind abilities, Strachan et al. find that the performance of LLMs can mirror that of humans on most of these tasks. The authors explored potential reasons for this.
期刊介绍:
Nature Human Behaviour is a journal that focuses on publishing research of outstanding significance into any aspect of human behavior.The research can cover various areas such as psychological, biological, and social bases of human behavior.It also includes the study of origins, development, and disorders related to human behavior.The primary aim of the journal is to increase the visibility of research in the field and enhance its societal reach and impact.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
