Tobias Vornholt, Mojmír Mutný, Gregor W. Schmidt, Christian Schellhaas, Ryo Tachibana, Sven Panke, Thomas R. Ward, Andreas Krause, Markus Jeschek
{"title":"通过主动学习增强人工金属酶的序列-活性映射和进化","authors":"Tobias Vornholt, Mojmír Mutný, Gregor W. Schmidt, Christian Schellhaas, Ryo Tachibana, Sven Panke, Thomas R. Ward, Andreas Krause, Markus Jeschek","doi":"10.1021/acscentsci.4c00258","DOIUrl":null,"url":null,"abstract":"Tailored enzymes are crucial for the transition to a sustainable bioeconomy. However, enzyme engineering is laborious and failure-prone due to its reliance on serendipity. The efficiency and success rates of engineering campaigns may be improved by applying machine learning to map the sequence-activity landscape based on small experimental data sets. Yet, it often proves challenging to reliably model large sequence spaces while keeping the experimental effort tractable. To address this challenge, we present an integrated pipeline combining large-scale screening with active machine learning, which we applied to engineer an artificial metalloenzyme (ArM) catalyzing a new-to-nature hydroamination reaction. Combining lab automation and next-generation sequencing, we acquired sequence-activity data for several thousand ArM variants. We then used Gaussian process regression to model the activity landscape and guide further screening rounds. Critical characteristics of our pipeline include the cost-effective generation of information-rich data sets, the integration of an explorative round to improve the model’s performance, and the inclusion of experimental noise. Our approach led to an order-of-magnitude boost in the hit rate while making efficient use of experimental resources. Search strategies like this should find broad utility in enzyme engineering and accelerate the development of novel biocatalysts.","PeriodicalId":10,"journal":{"name":"ACS Central Science","volume":"12 1","pages":""},"PeriodicalIF":10.4000,"publicationDate":"2024-05-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhanced Sequence-Activity Mapping and Evolution of Artificial Metalloenzymes by Active Learning\",\"authors\":\"Tobias Vornholt, Mojmír Mutný, Gregor W. Schmidt, Christian Schellhaas, Ryo Tachibana, Sven Panke, Thomas R. Ward, Andreas Krause, Markus Jeschek\",\"doi\":\"10.1021/acscentsci.4c00258\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Tailored enzymes are crucial for the transition to a sustainable bioeconomy. However, enzyme engineering is laborious and failure-prone due to its reliance on serendipity. The efficiency and success rates of engineering campaigns may be improved by applying machine learning to map the sequence-activity landscape based on small experimental data sets. Yet, it often proves challenging to reliably model large sequence spaces while keeping the experimental effort tractable. To address this challenge, we present an integrated pipeline combining large-scale screening with active machine learning, which we applied to engineer an artificial metalloenzyme (ArM) catalyzing a new-to-nature hydroamination reaction. Combining lab automation and next-generation sequencing, we acquired sequence-activity data for several thousand ArM variants. We then used Gaussian process regression to model the activity landscape and guide further screening rounds. Critical characteristics of our pipeline include the cost-effective generation of information-rich data sets, the integration of an explorative round to improve the model’s performance, and the inclusion of experimental noise. Our approach led to an order-of-magnitude boost in the hit rate while making efficient use of experimental resources. Search strategies like this should find broad utility in enzyme engineering and accelerate the development of novel biocatalysts.\",\"PeriodicalId\":10,\"journal\":{\"name\":\"ACS Central Science\",\"volume\":\"12 1\",\"pages\":\"\"},\"PeriodicalIF\":10.4000,\"publicationDate\":\"2024-05-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"ACS Central Science\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://doi.org/10.1021/acscentsci.4c00258\",\"RegionNum\":1,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"ACS Central Science","FirstCategoryId":"92","ListUrlMain":"https://doi.org/10.1021/acscentsci.4c00258","RegionNum":1,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
摘要
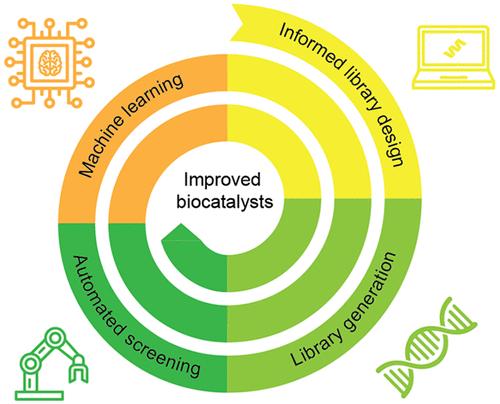
量身定制的酶对于向可持续生物经济过渡至关重要。然而,由于酶工程依赖于偶然性,因此既费力又容易失败。应用机器学习来绘制基于小型实验数据集的序列-活性图谱,可以提高工程活动的效率和成功率。然而,要在保持实验工作量可控的同时对大型序列空间进行可靠建模,往往具有挑战性。为了应对这一挑战,我们提出了一种将大规模筛选与主动机器学习相结合的集成管道,并将其应用于设计一种人工金属酶(ArM),以催化一种新的自然氢化反应。结合实验室自动化和新一代测序技术,我们获得了数千个 ArM 变体的序列-活性数据。然后,我们使用高斯过程回归法建立活性模型,并指导进一步的筛选工作。我们的方法的关键特点包括:经济高效地生成信息丰富的数据集、整合探索轮以提高模型的性能,以及包含实验噪音。我们的方法在有效利用实验资源的同时,还将命中率提高了一个数量级。像这样的搜索策略应该在酶工程中得到广泛应用,并加速新型生物催化剂的开发。
Enhanced Sequence-Activity Mapping and Evolution of Artificial Metalloenzymes by Active Learning
Tailored enzymes are crucial for the transition to a sustainable bioeconomy. However, enzyme engineering is laborious and failure-prone due to its reliance on serendipity. The efficiency and success rates of engineering campaigns may be improved by applying machine learning to map the sequence-activity landscape based on small experimental data sets. Yet, it often proves challenging to reliably model large sequence spaces while keeping the experimental effort tractable. To address this challenge, we present an integrated pipeline combining large-scale screening with active machine learning, which we applied to engineer an artificial metalloenzyme (ArM) catalyzing a new-to-nature hydroamination reaction. Combining lab automation and next-generation sequencing, we acquired sequence-activity data for several thousand ArM variants. We then used Gaussian process regression to model the activity landscape and guide further screening rounds. Critical characteristics of our pipeline include the cost-effective generation of information-rich data sets, the integration of an explorative round to improve the model’s performance, and the inclusion of experimental noise. Our approach led to an order-of-magnitude boost in the hit rate while making efficient use of experimental resources. Search strategies like this should find broad utility in enzyme engineering and accelerate the development of novel biocatalysts.
期刊介绍:
ACS Central Science publishes significant primary reports on research in chemistry and allied fields where chemical approaches are pivotal. As the first fully open-access journal by the American Chemical Society, it covers compelling and important contributions to the broad chemistry and scientific community. "Central science," a term popularized nearly 40 years ago, emphasizes chemistry's central role in connecting physical and life sciences, and fundamental sciences with applied disciplines like medicine and engineering. The journal focuses on exceptional quality articles, addressing advances in fundamental chemistry and interdisciplinary research.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
