Rovshan G. Sadygov*, Justin X. Zhu and Henock M. Deberneh,
{"title":"错误发现率和错误发现比例方差的精确积分公式。","authors":"Rovshan G. Sadygov*, Justin X. Zhu and Henock M. Deberneh, ","doi":"10.1021/acs.jproteome.3c00842","DOIUrl":null,"url":null,"abstract":"<p >Multiple hypothesis testing is an integral component of data analysis for large-scale technologies such as proteomics, transcriptomics, or metabolomics, for which the false discovery rate (FDR) and positive FDR (pFDR) have been accepted as error estimation and control measures. The pFDR is the expectation of false discovery proportion (FDP), which refers to the ratio of the number of null hypotheses to that of all rejected hypotheses. In practice, the expectation of ratio is approximated by the ratio of expectation; however, the conditions for transforming the former into the latter have not been investigated. This work derives exact integral expressions for the expectation (pFDR) and variance of FDP. The widely used approximation (ratio of expectations) is shown to be a particular case (in the limit of a large sample size) of the integral formula for pFDR. A recurrence formula is provided to compute the pFDR for a predefined number of null hypotheses. The variance of FDP was approximated for a practical application in peptide identification using forward and reversed protein sequences. The simulations demonstrate that the integral expression exhibits better accuracy than the approximate formula in the case of a small number of hypotheses. For large sample sizes, the pFDRs obtained by the integral expression and approximation do not differ substantially. Applications to proteomics data sets are included.</p>","PeriodicalId":48,"journal":{"name":"Journal of Proteome Research","volume":"23 6","pages":"2298–2305"},"PeriodicalIF":3.8000,"publicationDate":"2024-05-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Exact Integral Formulas for False Discovery Rate and the Variance of False Discovery Proportion\",\"authors\":\"Rovshan G. Sadygov*, Justin X. Zhu and Henock M. Deberneh, \",\"doi\":\"10.1021/acs.jproteome.3c00842\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Multiple hypothesis testing is an integral component of data analysis for large-scale technologies such as proteomics, transcriptomics, or metabolomics, for which the false discovery rate (FDR) and positive FDR (pFDR) have been accepted as error estimation and control measures. The pFDR is the expectation of false discovery proportion (FDP), which refers to the ratio of the number of null hypotheses to that of all rejected hypotheses. In practice, the expectation of ratio is approximated by the ratio of expectation; however, the conditions for transforming the former into the latter have not been investigated. This work derives exact integral expressions for the expectation (pFDR) and variance of FDP. The widely used approximation (ratio of expectations) is shown to be a particular case (in the limit of a large sample size) of the integral formula for pFDR. A recurrence formula is provided to compute the pFDR for a predefined number of null hypotheses. The variance of FDP was approximated for a practical application in peptide identification using forward and reversed protein sequences. The simulations demonstrate that the integral expression exhibits better accuracy than the approximate formula in the case of a small number of hypotheses. For large sample sizes, the pFDRs obtained by the integral expression and approximation do not differ substantially. Applications to proteomics data sets are included.</p>\",\"PeriodicalId\":48,\"journal\":{\"name\":\"Journal of Proteome Research\",\"volume\":\"23 6\",\"pages\":\"2298–2305\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2024-05-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Proteome Research\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://pubs.acs.org/doi/10.1021/acs.jproteome.3c00842\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Proteome Research","FirstCategoryId":"99","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acs.jproteome.3c00842","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
摘要
多重假设检验是蛋白质组学、转录组学或代谢组学等大规模技术数据分析不可或缺的组成部分,其错误发现率(FDR)和阳性 FDR(pFDR)已被公认为误差估计和控制措施。pFDR 是错误发现比例(FDP)的期望值,指的是无效假设的数量与所有被拒绝假设的数量之比。在实践中,期望比值近似于期望比值;然而,将前者转化为后者的条件尚未得到研究。这项工作推导出了 FDP 的期望值(pFDR)和方差的精确积分表达式。研究表明,广泛使用的近似值(期望比)是 pFDR 积分公式的一个特殊情况(在样本量较大的情况下)。提供了一个递推公式,用于计算预定数量零假设的 pFDR。在使用正向和反向蛋白质序列进行多肽鉴定的实际应用中,对 FDP 的方差进行了近似计算。模拟结果表明,在假设数量较少的情况下,积分表达式比近似公式表现出更好的准确性。在样本量较大的情况下,积分表达式和近似公式得到的 pFDR 没有太大差别。本研究还包括蛋白质组学数据集的应用。
Exact Integral Formulas for False Discovery Rate and the Variance of False Discovery Proportion
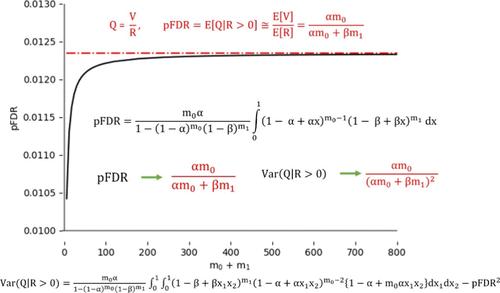
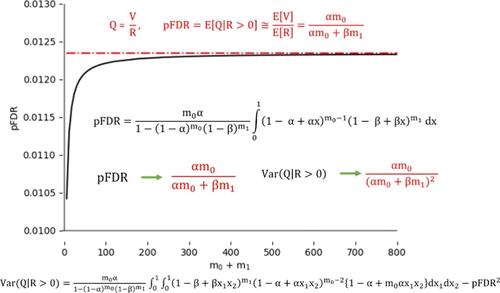
Multiple hypothesis testing is an integral component of data analysis for large-scale technologies such as proteomics, transcriptomics, or metabolomics, for which the false discovery rate (FDR) and positive FDR (pFDR) have been accepted as error estimation and control measures. The pFDR is the expectation of false discovery proportion (FDP), which refers to the ratio of the number of null hypotheses to that of all rejected hypotheses. In practice, the expectation of ratio is approximated by the ratio of expectation; however, the conditions for transforming the former into the latter have not been investigated. This work derives exact integral expressions for the expectation (pFDR) and variance of FDP. The widely used approximation (ratio of expectations) is shown to be a particular case (in the limit of a large sample size) of the integral formula for pFDR. A recurrence formula is provided to compute the pFDR for a predefined number of null hypotheses. The variance of FDP was approximated for a practical application in peptide identification using forward and reversed protein sequences. The simulations demonstrate that the integral expression exhibits better accuracy than the approximate formula in the case of a small number of hypotheses. For large sample sizes, the pFDRs obtained by the integral expression and approximation do not differ substantially. Applications to proteomics data sets are included.
期刊介绍:
Journal of Proteome Research publishes content encompassing all aspects of global protein analysis and function, including the dynamic aspects of genomics, spatio-temporal proteomics, metabonomics and metabolomics, clinical and agricultural proteomics, as well as advances in methodology including bioinformatics. The theme and emphasis is on a multidisciplinary approach to the life sciences through the synergy between the different types of "omics".




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
