{"title":"通过多语言 twitter 文本嵌入分析政党立场。","authors":"Jinghui Chen, Takayuki Mizuno, Shohei Doi","doi":"10.3389/fdata.2024.1330392","DOIUrl":null,"url":null,"abstract":"<p><p>Traditional monolingual word embedding models transform words into high-dimensional vectors which represent semantics relations between words as relationships between vectors in the high-dimensional space. They serve as productive tools to interpret multifarious aspects of the social world in social science research. Building on the previous research which interprets multifaceted meanings of words by projecting them onto word-level dimensions defined by differences between antonyms, we extend the architecture of establishing word-level cultural dimensions to the sentence level and adopt a Language-agnostic BERT model (LaBSE) to detect position similarities in a multi-language environment. We assess the efficacy of our sentence-level methodology using Twitter data from US politicians, comparing it to the traditional word-level embedding model. We also adopt Latent Dirichlet Allocation (LDA) to investigate detailed topics in these tweets and interpret politicians' positions from different angles. In addition, we adopt Twitter data from Spanish politicians and visualize their positions in a multi-language space to analyze position similarities across countries. The results show that our sentence-level methodology outperform traditional word-level model. We also demonstrate that our methodology is effective dealing with fine-sorted themes from the result that political positions towards different topics vary even within the same politicians. Through verification using American and Spanish political datasets, we find that the positioning of American and Spanish politicians on our defined liberal-conservative axis aligns with social common sense, political news, and previous research. Our architecture improves the standard word-level methodology and can be considered as a useful architecture for sentence-level applications in the future.</p>","PeriodicalId":52859,"journal":{"name":"Frontiers in Big Data","volume":"7 ","pages":"1330392"},"PeriodicalIF":2.4000,"publicationDate":"2024-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11169868/pdf/","citationCount":"0","resultStr":"{\"title\":\"Analyzing political party positions through multi-language twitter text embeddings.\",\"authors\":\"Jinghui Chen, Takayuki Mizuno, Shohei Doi\",\"doi\":\"10.3389/fdata.2024.1330392\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Traditional monolingual word embedding models transform words into high-dimensional vectors which represent semantics relations between words as relationships between vectors in the high-dimensional space. They serve as productive tools to interpret multifarious aspects of the social world in social science research. Building on the previous research which interprets multifaceted meanings of words by projecting them onto word-level dimensions defined by differences between antonyms, we extend the architecture of establishing word-level cultural dimensions to the sentence level and adopt a Language-agnostic BERT model (LaBSE) to detect position similarities in a multi-language environment. We assess the efficacy of our sentence-level methodology using Twitter data from US politicians, comparing it to the traditional word-level embedding model. We also adopt Latent Dirichlet Allocation (LDA) to investigate detailed topics in these tweets and interpret politicians' positions from different angles. In addition, we adopt Twitter data from Spanish politicians and visualize their positions in a multi-language space to analyze position similarities across countries. The results show that our sentence-level methodology outperform traditional word-level model. We also demonstrate that our methodology is effective dealing with fine-sorted themes from the result that political positions towards different topics vary even within the same politicians. Through verification using American and Spanish political datasets, we find that the positioning of American and Spanish politicians on our defined liberal-conservative axis aligns with social common sense, political news, and previous research. Our architecture improves the standard word-level methodology and can be considered as a useful architecture for sentence-level applications in the future.</p>\",\"PeriodicalId\":52859,\"journal\":{\"name\":\"Frontiers in Big Data\",\"volume\":\"7 \",\"pages\":\"1330392\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2024-05-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11169868/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Big Data\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fdata.2024.1330392\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Big Data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdata.2024.1330392","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Analyzing political party positions through multi-language twitter text embeddings.
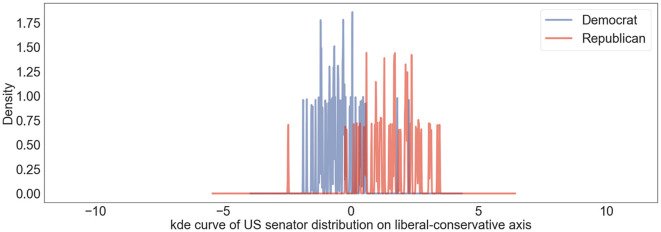
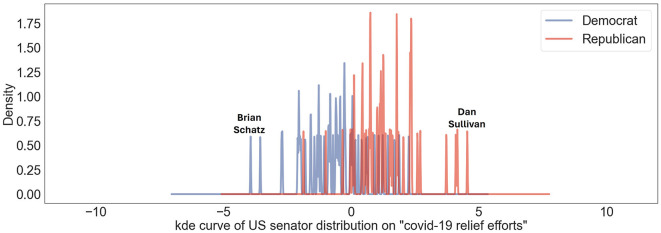
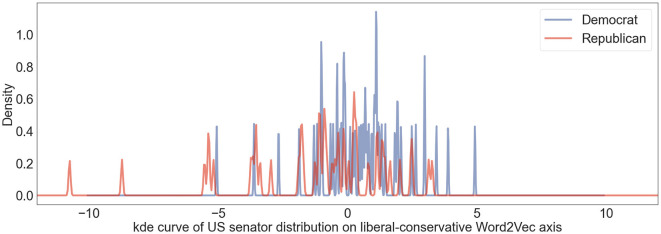
Traditional monolingual word embedding models transform words into high-dimensional vectors which represent semantics relations between words as relationships between vectors in the high-dimensional space. They serve as productive tools to interpret multifarious aspects of the social world in social science research. Building on the previous research which interprets multifaceted meanings of words by projecting them onto word-level dimensions defined by differences between antonyms, we extend the architecture of establishing word-level cultural dimensions to the sentence level and adopt a Language-agnostic BERT model (LaBSE) to detect position similarities in a multi-language environment. We assess the efficacy of our sentence-level methodology using Twitter data from US politicians, comparing it to the traditional word-level embedding model. We also adopt Latent Dirichlet Allocation (LDA) to investigate detailed topics in these tweets and interpret politicians' positions from different angles. In addition, we adopt Twitter data from Spanish politicians and visualize their positions in a multi-language space to analyze position similarities across countries. The results show that our sentence-level methodology outperform traditional word-level model. We also demonstrate that our methodology is effective dealing with fine-sorted themes from the result that political positions towards different topics vary even within the same politicians. Through verification using American and Spanish political datasets, we find that the positioning of American and Spanish politicians on our defined liberal-conservative axis aligns with social common sense, political news, and previous research. Our architecture improves the standard word-level methodology and can be considered as a useful architecture for sentence-level applications in the future.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
