{"title":"利用扩散模型生成用于医学图像分割的合成标记数据。","authors":"Daniel G Saragih, Atsuhiro Hibi, Pascal N Tyrrell","doi":"10.1007/s11548-024-03213-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Medical image analysis has become a prominent area where machine learning has been applied. However, high-quality, publicly available data are limited either due to patient privacy laws or the time and cost required for experts to annotate images. In this retrospective study, we designed and evaluated a pipeline to generate synthetic labeled polyp images for augmenting medical image segmentation models with the aim of reducing this data scarcity.</p><p><strong>Methods: </strong>We trained diffusion models on the HyperKvasir dataset, comprising 1000 images of polyps in the human GI tract from 2008 to 2016. Qualitative expert review, Fréchet Inception Distance (FID), and Multi-Scale Structural Similarity (MS-SSIM) were tested for evaluation. Additionally, various segmentation models were trained with the generated data and evaluated using Dice score (DS) and Intersection over Union (IoU).</p><p><strong>Results: </strong>Our pipeline produced images more akin to real polyp images based on FID scores. Segmentation model performance also showed improvements over GAN methods when trained entirely, or partially, with synthetic data, despite requiring less compute for training. Moreover, the improvement persists when tested on different datasets, showcasing the transferability of the generated images.</p><p><strong>Conclusions: </strong>The proposed pipeline produced realistic image and mask pairs which could reduce the need for manual data annotation when performing a machine learning task. We support this use case by showing that the methods proposed in this study enhanced segmentation model performance, as measured by Dice and IoU scores, when trained fully or partially on synthetic data.</p>","PeriodicalId":51251,"journal":{"name":"International Journal of Computer Assisted Radiology and Surgery","volume":" ","pages":"1615-1625"},"PeriodicalIF":2.3000,"publicationDate":"2024-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Using diffusion models to generate synthetic labeled data for medical image segmentation.\",\"authors\":\"Daniel G Saragih, Atsuhiro Hibi, Pascal N Tyrrell\",\"doi\":\"10.1007/s11548-024-03213-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>Medical image analysis has become a prominent area where machine learning has been applied. However, high-quality, publicly available data are limited either due to patient privacy laws or the time and cost required for experts to annotate images. In this retrospective study, we designed and evaluated a pipeline to generate synthetic labeled polyp images for augmenting medical image segmentation models with the aim of reducing this data scarcity.</p><p><strong>Methods: </strong>We trained diffusion models on the HyperKvasir dataset, comprising 1000 images of polyps in the human GI tract from 2008 to 2016. Qualitative expert review, Fréchet Inception Distance (FID), and Multi-Scale Structural Similarity (MS-SSIM) were tested for evaluation. Additionally, various segmentation models were trained with the generated data and evaluated using Dice score (DS) and Intersection over Union (IoU).</p><p><strong>Results: </strong>Our pipeline produced images more akin to real polyp images based on FID scores. Segmentation model performance also showed improvements over GAN methods when trained entirely, or partially, with synthetic data, despite requiring less compute for training. Moreover, the improvement persists when tested on different datasets, showcasing the transferability of the generated images.</p><p><strong>Conclusions: </strong>The proposed pipeline produced realistic image and mask pairs which could reduce the need for manual data annotation when performing a machine learning task. We support this use case by showing that the methods proposed in this study enhanced segmentation model performance, as measured by Dice and IoU scores, when trained fully or partially on synthetic data.</p>\",\"PeriodicalId\":51251,\"journal\":{\"name\":\"International Journal of Computer Assisted Radiology and Surgery\",\"volume\":\" \",\"pages\":\"1615-1625\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2024-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of Computer Assisted Radiology and Surgery\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1007/s11548-024-03213-z\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/6/20 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"ENGINEERING, BIOMEDICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Assisted Radiology and Surgery","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s11548-024-03213-z","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/6/20 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
引用次数: 0
摘要
目的:医学图像分析已成为机器学习的一个重要应用领域。然而,由于患者隐私法或专家注释图像所需的时间和成本,高质量的公开数据非常有限。在这项回顾性研究中,我们设计并评估了一个生成合成标记息肉图像的管道,用于增强医学图像分割模型,目的是减少这种数据稀缺性:我们在 HyperKvasir 数据集上训练了扩散模型,该数据集包含 2008 年至 2016 年间 1000 张人类消化道息肉图像。对专家定性审查、弗雷谢特起始距离(FID)和多尺度结构相似性(MS-SSIM)进行了测试评估。此外,还使用生成的数据训练了各种分割模型,并使用骰子得分(Dice score,DS)和交叉联合(Intersection over Union,IoU)进行了评估:结果:根据 FID 分数,我们的管道生成的图像更接近真实息肉图像。在完全或部分使用合成数据进行训练时,尽管训练所需的计算量较少,但分割模型的性能也比 GAN 方法有所提高。此外,在不同的数据集上进行测试时,这种改进依然存在,这表明生成的图像具有可移植性:结论:所提出的管道生成了逼真的图像和掩码对,这可以减少执行机器学习任务时对人工数据标注的需求。我们通过证明本研究中提出的方法提高了分割模型的性能(以 Dice 和 IoU 分数衡量)来支持这一用例。
Using diffusion models to generate synthetic labeled data for medical image segmentation.
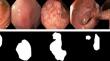
Purpose: Medical image analysis has become a prominent area where machine learning has been applied. However, high-quality, publicly available data are limited either due to patient privacy laws or the time and cost required for experts to annotate images. In this retrospective study, we designed and evaluated a pipeline to generate synthetic labeled polyp images for augmenting medical image segmentation models with the aim of reducing this data scarcity.
Methods: We trained diffusion models on the HyperKvasir dataset, comprising 1000 images of polyps in the human GI tract from 2008 to 2016. Qualitative expert review, Fréchet Inception Distance (FID), and Multi-Scale Structural Similarity (MS-SSIM) were tested for evaluation. Additionally, various segmentation models were trained with the generated data and evaluated using Dice score (DS) and Intersection over Union (IoU).
Results: Our pipeline produced images more akin to real polyp images based on FID scores. Segmentation model performance also showed improvements over GAN methods when trained entirely, or partially, with synthetic data, despite requiring less compute for training. Moreover, the improvement persists when tested on different datasets, showcasing the transferability of the generated images.
Conclusions: The proposed pipeline produced realistic image and mask pairs which could reduce the need for manual data annotation when performing a machine learning task. We support this use case by showing that the methods proposed in this study enhanced segmentation model performance, as measured by Dice and IoU scores, when trained fully or partially on synthetic data.
期刊介绍:
The International Journal for Computer Assisted Radiology and Surgery (IJCARS) is a peer-reviewed journal that provides a platform for closing the gap between medical and technical disciplines, and encourages interdisciplinary research and development activities in an international environment.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
