{"title":"手写速记识别和 LION 数据集","authors":"Raphaela Heil, Malin Nauwerck","doi":"10.1007/s10032-024-00479-6","DOIUrl":null,"url":null,"abstract":"<p>In this paper, we establish the first baseline for handwritten stenography recognition, using the novel LION dataset, and investigate the impact of including selected aspects of stenographic theory into the recognition process. We make the LION dataset publicly available with the aim of encouraging future research in handwritten stenography recognition. A state-of-the-art text recognition model is trained to establish a baseline. Stenographic domain knowledge is integrated by transforming the target sequences into representations which approximate diplomatic transcriptions, wherein each symbol in the script is represented by its own character in the transliteration, as opposed to corresponding combinations of characters from the Swedish alphabet. Four such encoding schemes are evaluated and results are further improved by integrating a pre-training scheme, based on synthetic data. The baseline model achieves an average test character error rate (CER) of 29.81% and a word error rate (WER) of 55.14%. Test error rates are reduced significantly (<i>p</i>< 0.01) by combining stenography-specific target sequence encodings with pre-training and fine-tuning, yielding CERs in the range of 24.5–26% and WERs of 44.8–48.2%. An analysis of selected recognition errors illustrates the challenges that the stenographic writing system poses to text recognition. This work establishes the first baseline for handwritten stenography recognition. Our proposed combination of integrating stenography-specific knowledge, in conjunction with pre-training and fine-tuning on synthetic data, yields considerable improvements. Together with our precursor study on the subject, this is the first work to apply modern handwritten text recognition to stenography. The dataset and our code are publicly available via Zenodo.</p>","PeriodicalId":50277,"journal":{"name":"International Journal on Document Analysis and Recognition","volume":"2015 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-06-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Handwritten stenography recognition and the LION dataset\",\"authors\":\"Raphaela Heil, Malin Nauwerck\",\"doi\":\"10.1007/s10032-024-00479-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>In this paper, we establish the first baseline for handwritten stenography recognition, using the novel LION dataset, and investigate the impact of including selected aspects of stenographic theory into the recognition process. We make the LION dataset publicly available with the aim of encouraging future research in handwritten stenography recognition. A state-of-the-art text recognition model is trained to establish a baseline. Stenographic domain knowledge is integrated by transforming the target sequences into representations which approximate diplomatic transcriptions, wherein each symbol in the script is represented by its own character in the transliteration, as opposed to corresponding combinations of characters from the Swedish alphabet. Four such encoding schemes are evaluated and results are further improved by integrating a pre-training scheme, based on synthetic data. The baseline model achieves an average test character error rate (CER) of 29.81% and a word error rate (WER) of 55.14%. Test error rates are reduced significantly (<i>p</i>< 0.01) by combining stenography-specific target sequence encodings with pre-training and fine-tuning, yielding CERs in the range of 24.5–26% and WERs of 44.8–48.2%. An analysis of selected recognition errors illustrates the challenges that the stenographic writing system poses to text recognition. This work establishes the first baseline for handwritten stenography recognition. Our proposed combination of integrating stenography-specific knowledge, in conjunction with pre-training and fine-tuning on synthetic data, yields considerable improvements. Together with our precursor study on the subject, this is the first work to apply modern handwritten text recognition to stenography. The dataset and our code are publicly available via Zenodo.</p>\",\"PeriodicalId\":50277,\"journal\":{\"name\":\"International Journal on Document Analysis and Recognition\",\"volume\":\"2015 1\",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-06-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal on Document Analysis and Recognition\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10032-024-00479-6\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal on Document Analysis and Recognition","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10032-024-00479-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Handwritten stenography recognition and the LION dataset
In this paper, we establish the first baseline for handwritten stenography recognition, using the novel LION dataset, and investigate the impact of including selected aspects of stenographic theory into the recognition process. We make the LION dataset publicly available with the aim of encouraging future research in handwritten stenography recognition. A state-of-the-art text recognition model is trained to establish a baseline. Stenographic domain knowledge is integrated by transforming the target sequences into representations which approximate diplomatic transcriptions, wherein each symbol in the script is represented by its own character in the transliteration, as opposed to corresponding combinations of characters from the Swedish alphabet. Four such encoding schemes are evaluated and results are further improved by integrating a pre-training scheme, based on synthetic data. The baseline model achieves an average test character error rate (CER) of 29.81% and a word error rate (WER) of 55.14%. Test error rates are reduced significantly (p< 0.01) by combining stenography-specific target sequence encodings with pre-training and fine-tuning, yielding CERs in the range of 24.5–26% and WERs of 44.8–48.2%. An analysis of selected recognition errors illustrates the challenges that the stenographic writing system poses to text recognition. This work establishes the first baseline for handwritten stenography recognition. Our proposed combination of integrating stenography-specific knowledge, in conjunction with pre-training and fine-tuning on synthetic data, yields considerable improvements. Together with our precursor study on the subject, this is the first work to apply modern handwritten text recognition to stenography. The dataset and our code are publicly available via Zenodo.
期刊介绍:
The large number of existing documents and the production of a multitude of new ones every year raise important issues in efficient handling, retrieval and storage of these documents and the information which they contain. This has led to the emergence of new research domains dealing with the recognition by computers of the constituent elements of documents - including characters, symbols, text, lines, graphics, images, handwriting, signatures, etc. In addition, these new domains deal with automatic analyses of the overall physical and logical structures of documents, with the ultimate objective of a high-level understanding of their semantic content. We have also seen renewed interest in optical character recognition (OCR) and handwriting recognition during the last decade. Document analysis and recognition are obviously the next stage.
Automatic, intelligent processing of documents is at the intersections of many fields of research, especially of computer vision, image analysis, pattern recognition and artificial intelligence, as well as studies on reading, handwriting and linguistics. Although quality document related publications continue to appear in journals dedicated to these domains, the community will benefit from having this journal as a focal point for archival literature dedicated to document analysis and recognition.
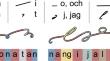



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
